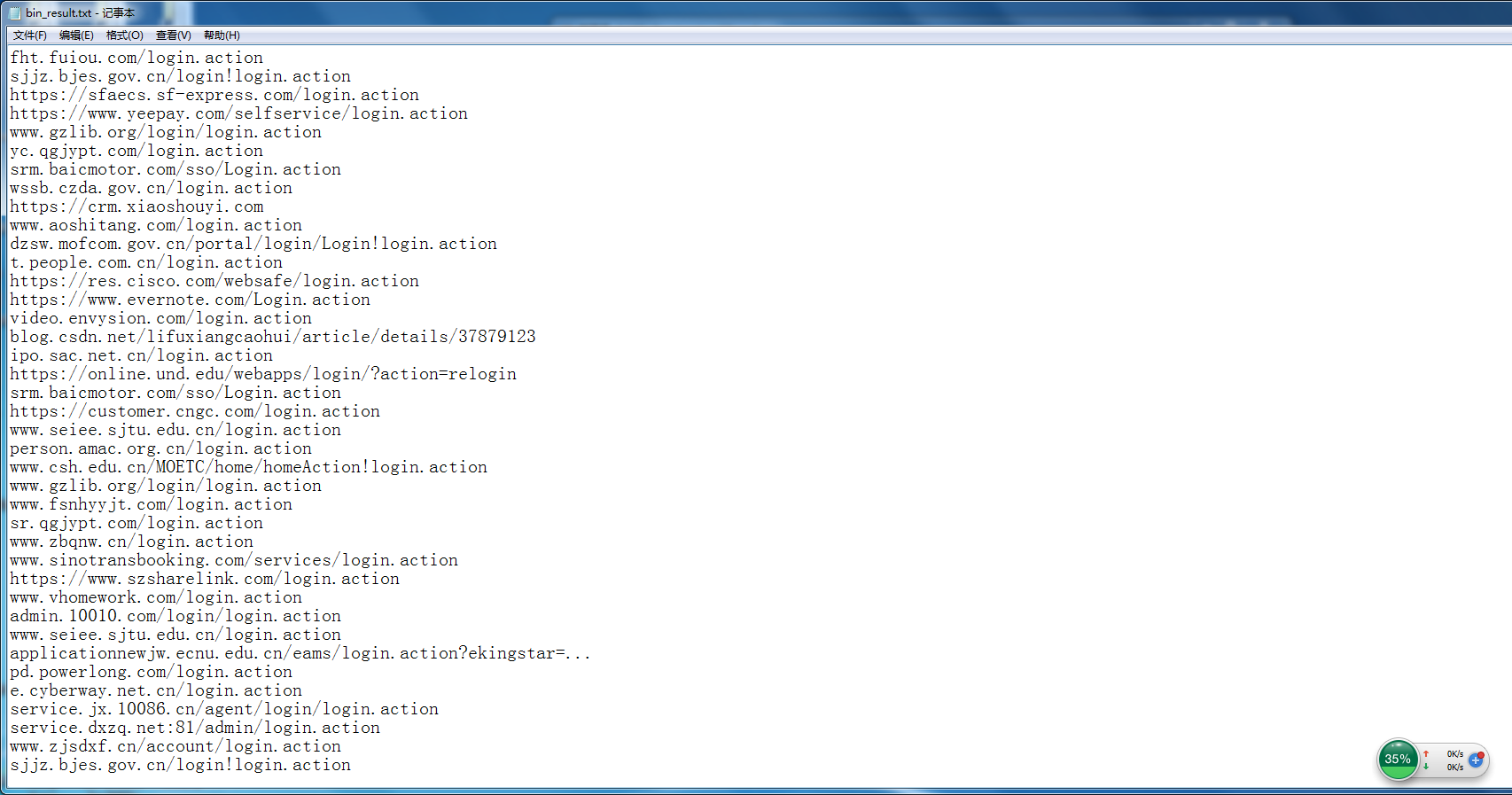
Perl6 必应抓取(1):测试版代码
一个相当丑漏的代码, 以后有时间再优化了。
默认所有查找都是15页, 如果结果没有15页这么多估计会有重复。速度还是很快的。
sub MAIN() {
my $fp = open 'bin_result.txt', :w;
my $number = ;
print 'String:';
my $string = get;
$string = do given $string {S:g/\s/+/};
use HTTP::UserAgent;
my $url = 'http://cn.bing.com/search?q=';
my $ua = HTTP::UserAgent.new;
my $check = rx/'<'cite'>'(.*?)'</cite>'/;#要查的内容
my @number = '';
@number.append(..$number);
my $page='';
my $html;
my $target = $url~$string~'&first=20&FROM=FERE'~$page;
$html = $ua.get($target).content;
loop {
say '===============> '~$target;
$html ~~ $check;
$html = $/.postmatch;
#$0 = do given ~$0 {S:g/'<strong>'//;}
if not $ {
#当是null时, 说明这一页已全部提取, 构造下一页
$page = Int($page);
my $page_next = $string~'&first='~$page~'0&FROM=FERE'~$page;
$target = $url~$page_next;
$html = $ua.get($target).content;
$page++;
#/search?q=123&first=10&FORM=PERE
#/search?q=123&first=20&FORM=PERE1
#/search?q=123&first=30&FORM=PERE2
#/search?q=123&first=30&FORM=PERE2
#last;
$html ~~ $check;
$html = $/.postmatch;
if ($page > $number) {last;}
}
my $ok_check = $.Str;
my $result = $ok_check;
$result = do given $result {S:g/'<strong>'//;}
$result = do given $result {S:g/'</strong>'//;}
say $result;
$fp.say($result);
}
#$fp.print($html);
}


下次代码优化:
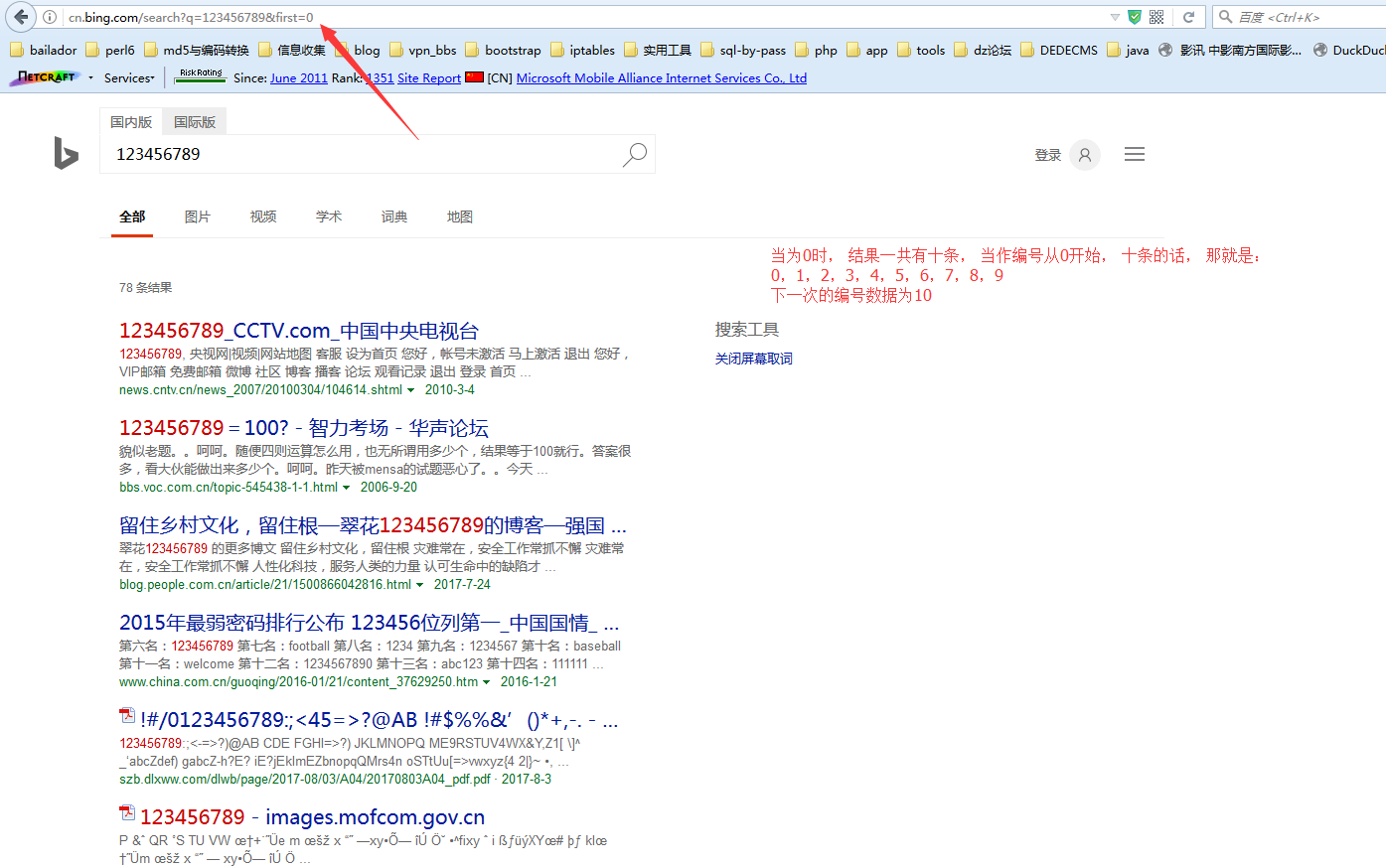
总结一下必应的规律, 如下:
http://cn.bing.com/search?q=&first=&FORM=PERE
http://cn.bing.com/search?q=&first=&FORM=PERE
http://cn.bing.com/search?q=&first=&FORM=PERE1
http://cn.bing.com/search?q=&first=&FORM=PERE2
http://cn.bing.com/search?q=&first=&FORM=PERE3
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
在页面上测试, 参数只虽两个即可:
q=查询字符串&first=起始帐号


Perl6 必应抓取(1):测试版代码的更多相关文章
- Perl6 必应抓取(2):最终版
use HTTP::UserAgent; use URI::Encode; Firefox/52.0>); my $bing_url = 'http://cn.bing.com/search?q ...
- HttpClient 4.x 执行网站登录并抓取网页的代码
HttpClient 4.x 的 API 变化还是很大,这段代码可用来执行登录过程,并抓取网页. HttpClient API 文档(4.0.x), HttpCore API 文档(4.1) pack ...
- php中抓取网页内容的代码
方法一: 使用file_get_contents方法实现 $url = "http://news.sina.com.cn/c/nd/2016-10-23/doc-ifxwztru695114 ...
- xheditor编辑器上传截图图片抓取远程图片代码
xheditor是一款很不错的开源编辑器,用起来很方便也很强大. 分享一个xheditor直接上传截图的问题解决方法. 第一步.设置参数 localUrlTest:/^https?:\/\/[^\/] ...
- python网页抓取练手代码
from urllib import request import html.parser class zhuaqu(html.parser.HTMLParser): blogHtml = " ...
- Python网络编程_抓取百度首页代码(注释详细)
1 #coding=utf-8 2 #网络编程 3 4 #客户端建立socket套接字 5 #引入socket模块 6 import socket 7 #实例化一个套接字,2个参数分别是: IPV4. ...
- 抓取网站数据不再是难事了,Fizzler(So Easy)全能搞定
首先从标题说起,为啥说抓取网站数据不再难(其实抓取网站数据有一定难度),SO EASY!!!使用Fizzler全搞定,我相信大多数人或公司应该都有抓取别人网站数据的经历,比如说我们博客园每次发表完文章 ...
- PHP的cURL库:抓取网页,POST数据及其他,HTTP认证 抓取数据
From : http://developer.51cto.com/art/200904/121739.htm 下面是一个小例程: ﹤?php// 初始化一个 cURL 对象$curl = curl_ ...
- php中封装的curl函数(抓取数据)
介绍一个封闭好的函数,封闭了curl函数的常用步骤,方便抓取数据. 代码如下: <?php /** * 封闭好的 curl函数 * 用途:抓取数据 * edit by www.jbxue.com ...
随机推荐
- 反向代理负载均衡-----nginx
一:集群 1.1:集群的概念 集群是一组相互独立的.通过高速网络互联的计算机,他们构成了一个组,并以单一系统的模式加以管理.一个客户与集群相互作用时,集群像是一个独立的服务器.集群配置是用于提高 ...
- apache server-status配置
引言 自己配置LAMP服务器时(xwamp),获取状态信息出现错误: You don't have permission to access /server-status on this server ...
- android面试(5)---SQL数据库
SQL基础: 1.如何查询table1从20到30条记录: select * from table1 limit 19,11 2.替换id=1,name =deman的记录? replace into ...
- BZOJ4950 Wf2017Mission Improbable(二分图匹配)
先给每个非零格子-1以满足俯视图不变.于是就相当于要求每行每列最大值不变.能减少剩余箱子的唯一方法是在要求相同的行列的交叉处放箱子以同时满足两个需求.给这些行列连边跑二分图匹配即可.注意必须格子初始时 ...
- element-ui中单独引入Message组件的问题
import Message from './src/main.js'; export default Message; 由于Message组件并没有install 方法供Vue来操作的,是直接返回的 ...
- [BZOJ4870][Shoi2017]组合数问题 dp+矩阵乘
4870: [Shoi2017]组合数问题 Time Limit: 10 Sec Memory Limit: 512 MB Description Input 第一行有四个整数 n, p, k, r ...
- Spring Boot系列教程九:Spring boot集成Redis
一.创建项目 项目名称为 “springboot_redis”,创建过程中勾选 “Web”,“Redis”,第一次创建Maven需要下载依赖包(耐心等待) 二.实现 properties配置文件中添加 ...
- linux服务之NTP时间服务器
1. NTP简介 NTP(Network Time Protocol,网络时间协议)是用来使网络中的各个计算机时间同步的一种协议.它的用途是把计算机的时钟同步到世界协调时UTC,其精度在局域网内可达0 ...
- Linux内核设计第五周学习总结 分析system_call中断处理过程
陈巧然原创作品 转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 使用gdb跟踪分析一 ...
- 关于JBoss基本说明文档及基本使用安装
关于JBoss JBoss是全世界开发者共同努力的成果,一个基于J2EE的开放源代码的应用服务器.在不 到12个月的时间里有一百万以上的拷贝被下载.JBoss是第一位的J2EE应用服务器. J ...