XGBoost——机器学习--周振洋
XGBoost——机器学习(理论+图解+安装方法+python代码)
目录
一、集成算法思想
二、XGBoost基本思想
三、MacOS安装XGBoost
四、用python实现XGBoost算法
在竞赛题中经常会用到XGBoost算法,用这个算法通常会使我们模型的准确率有一个较大的提升。既然它效果这么好,那么它从头到尾做了一件什么事呢?以及它是怎么样去做的呢?
我们先来直观的理解一下什么是XGBoost。XGBoost算法是和决策树算法联系到一起的。决策树算法在我的另一篇博客中讲过了.
一、集成算法思想
在决策树中,我们知道一个样本往左边分或者往右边分,最终到达叶子结点,这样来进行一个分类任务。 其实也可以做回归任务。

看上面一个图例左边:有5个样本,现在想看下这5个人愿不愿意去玩游戏,这5个人现在都分到了叶子结点里面,对不同的叶子结点分配不同的权重项,正数代表这个人愿意去玩游戏,负数代表这个人不愿意去玩游戏。所以我们可以通过叶子结点和权值的结合,来综合的评判当前这个人到底是愿意还是不愿意去玩游戏。上面「tree1」那个小男孩它所处的叶子结点的权值是+2(可以理解为得分)。
用单个决策树好像效果一般来说不是太好,或者说可能会太绝对。通常我们会用一种集成的方法,就是一棵树效果可能不太好,用两棵树呢?
看图例右边的「tree2」,它和左边的不同在于它使用了另外的指标,出了年龄和性别,还可以考虑使用电脑频率这个划分属性。通过这两棵树共同帮我们决策当前这个人愿不愿意玩游戏,小男孩在「tree1」的权值是+2,在「tree2」的权值是+0.9, 所以小男孩最终的权值是+2.9(可以理解为得分是+2.9)。老爷爷最终的权值也是通过一样的过程得到的。
所以说,我们通常在做分类或者回归任务的时候,需要想一想一旦选择用一个分类器可能表达效果并不是很好,那么就要考虑用这样一个集成的思想。上面的图例只是举了两个分类器,其实还可以有更多更复杂的弱分类器,一起组合成一个强分类器。
二、XGBoost基本思想
XGBoost的集成表示是什么?怎么预测?求最优解的目标是什么?看下图的说明你就能一目了然。

在XGBoost里,每棵树是一个一个往里面加的,每加一个都是希望效果能够提升,下图就是XGBoost这个集成的表示(核心)。

一开始树是0,然后往里面加树,相当于多了一个函数,再加第二棵树,相当于又多了一个函数...等等,这里需要保证加入新的函数能够提升整体对表达效果。提升表达效果的意思就是说加上新的树之后,目标函数(就是损失)的值会下降。
如果叶子结点的个数太多,那么过拟合的风险会越大,所以这里要限制叶子结点的个数,所以在原来目标函数里要加上一个惩罚项「omega(ft)」。

这里举个简单的例子看看惩罚项「omega(ft)」是如何计算的:
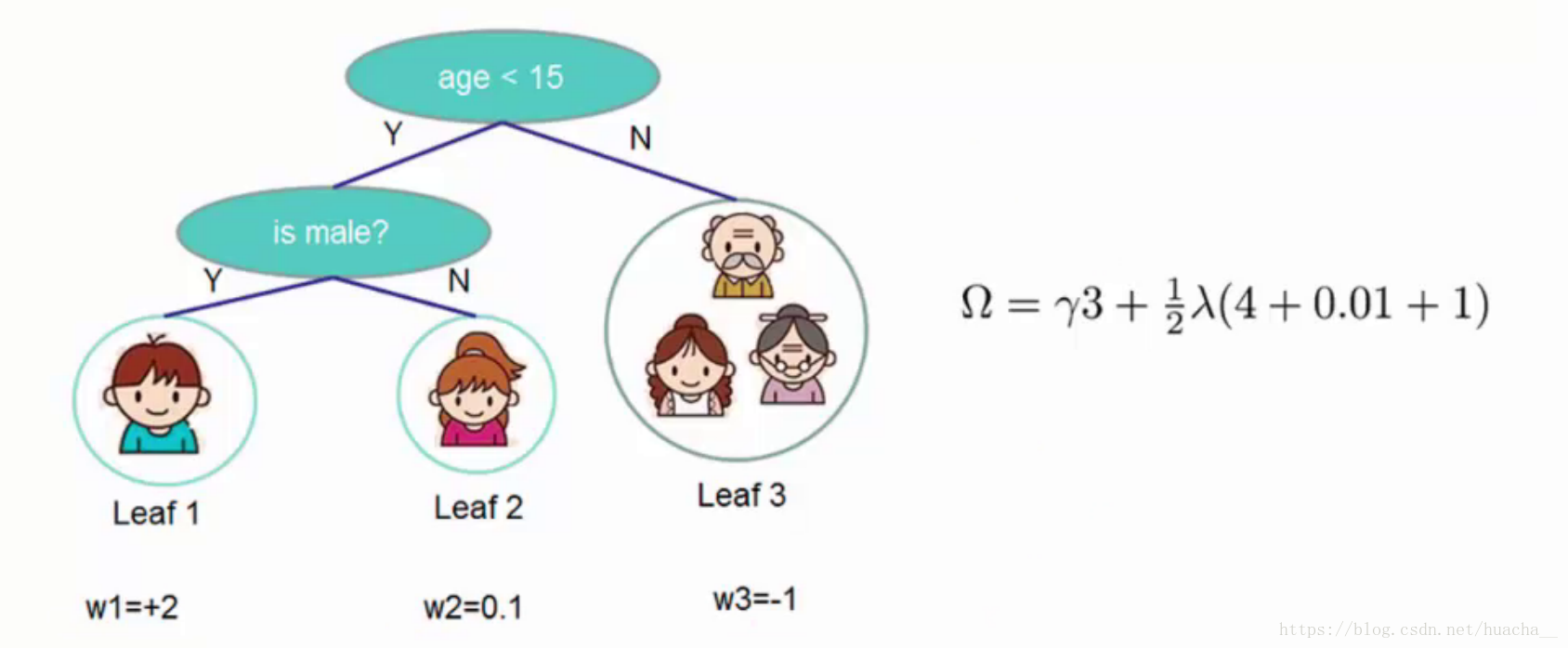
一共3个叶子结点,权重分别是2,0.1,-1,带入「omega(ft)」中就得到上面图例的式子,惩罚力度和「lambda」的值人为给定。
XGBoost算法完整的目标函数见下面这个公式,它由自身的损失函数和正则化惩罚项「omega(ft)」相加而成。

关于目标函数的推导本文章不作详细介绍。过程就是:给目标函数对权重求偏导,得到一个能够使目标函数最小的权重,把这个权重代回到目标函数中,这个回代结果就是求解后的最小目标函数值,如下:
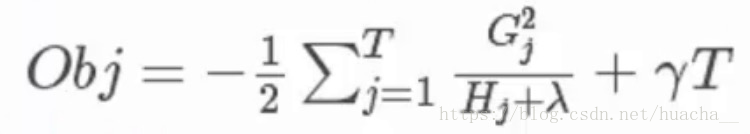
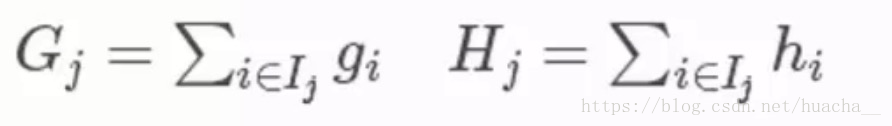

其中第三个式子中的一阶导二阶导的梯度数据都是可以算出来的,只要指定了主函数中的两个参数,这就是一个确定的值。下面给出一个直观的例子来看下这个过程。

(这里多说一句:Obj代表了当我们指定一个树的结构的时候,在目标上最多会减少多少,我们可以把它叫做结构分数,这个分数越小越好)
对于每次扩展,我们依旧要枚举所有可能的方案。对于某个特定的分割,我们要计算出这个分割的左子树的导数和和右子数导数和之和(就是下图中的第一个红色方框),然后和划分前的进行比较(基于损失,看分割后的损失和分割前的损失有没有发生变化,变化了多少)。遍历所有分割,选择变化最大的作为最合适的分割。

三、MacOS安装XGBoost
用pip安装XGBoost
第一步, 安装HomeBrew.
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"HomeBrew是Mac的一个包管理软件, 类似于Linux里面的apt-get
第二步, 安装llvm
brew install llvm第三步,安装clang-omp
brew install clang-omp有人提到clang-omp已经从HomeBrew移除了, 如果找不到clang-omp可以尝试
brew install --with-clang llvm 第四步,安装XGBoost
pip install xgboost测试一下,大功告成!

四、用python实现XGBoost算法
pima-indians-diabetes.csv文件中包括了8列数值型自变量,和第9列0-1的二分类因变量,导入到python中用XGBoost算法做探索性尝试,得到预测数据的准确率为77.95%。
- import xgboost
- from numpy import loadtxt
- from xgboost import XGBClassifier
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score
- # 载入数据集
- dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
- # split data into X and y
- X = dataset[:,0:8]
- Y = dataset[:,8]
- # 把数据集拆分成训练集和测试集
- seed = 7
- test_size = 0.33
- X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
- # 拟合XGBoost模型
- model = XGBClassifier()
- model.fit(X_train, y_train)
- # 对测试集做预测
- y_pred = model.predict(X_test)
- predictions = [round(value) for value in y_pred]
- # 评估预测结果
- accuracy = accuracy_score(y_test, predictions)
- print("Accuracy: %.2f%%" % (accuracy * 100.0))
结果输出:
Accuracy: 77.95%在python的XGBoost包中最重要的函数是XGBClassifier(),函数中涉及到多种参数,此外还可以关注plot_importance(),更多的说明我将在以后进行更新。
XGBoost——机器学习--周振洋的更多相关文章
- LightGBM的并行优化--机器学习-周振洋
LightGBM的并行优化 上一篇文章介绍了LightGBM算法的特点,总结起来LightGBM采用Histogram算法进行特征选择以及采用Leaf-wise的决策树生长策略,使其在一批以树模型为基 ...
- LightGBM详细用法--机器学习算法--周振洋
LightGBM算法总结 2018年08月21日 18:39:47 Ghost_Hzp 阅读数:2360 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
- 机器学习sklearn的快速使用--周振洋
ML神器:sklearn的快速使用 传统的机器学习任务从开始到建模的一般流程是:获取数据 -> 数据预处理 -> 训练建模 -> 模型评估 -> 预测,分类.本文我们将依据传统 ...
- Tensorflow中使用tfrecord方式读取数据-深度学习-周振洋
本博客默认读者对神经网络与Tensorflow有一定了解,对其中的一些术语不再做具体解释.并且本博客主要以图片数据为例进行介绍,如有错误,敬请斧正. 使用Tensorflow训练神经网络时,我们可以用 ...
- Python音频处理(一)音频基础知识-周振洋
1.声音音频基础知识 (1)声音是由震动产生,表现为波的形式.波有频率,振幅等参数.对于声波而言:频率越大,音调越高,反之越低.振幅越大,声音越大,反之越小. (2)采样率,帧率:波是连续(无穷)的, ...
- 机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC--周振洋
机器学习性能指标精确率.召回率.F1值.ROC.PRC与AUC 精确率.召回率.F1.AUC和ROC曲线都是评价模型好坏的指标,那么它们之间有什么不同,又有什么联系呢.下面让我们分别来看一下这几个指标 ...
- 【Todo】【读书笔记】机器学习-周志华
书籍位置: /Users/baidu/Documents/Data/Interview/机器学习-数据挖掘/<机器学习_周志华.pdf> 一共442页.能不能这个周末先囫囵吞枣看完呢.哈哈 ...
- 机器学习周志华 pdf统计学习人工智能资料下载
周志华-机器学习 pdf,下载地址: https://u12230716.pipipan.com/fs/12230716-239561959 统计学习方法-李航, 下载地址: https://u12 ...
- XGBoost参数调优完全指南(附Python代码)
XGBoost参数调优完全指南(附Python代码):http://www.2cto.com/kf/201607/528771.html https://www.zhihu.com/question/ ...
随机推荐
- CKEditor4x word导入不保存格式的解决方案
后台上传文档时,目前功能都通过word直接复制黏贴实现,之前和word控件朋友一起测试找个问题,原始代码CK4.X没有找个问题. 第一时间排查config.js的配置发现端倪,测试解决! 由于配合ck ...
- 编译安装 mysql 5.5,运行 cmake报错Curses library not found
是因为 curses库没有安装,执行下面的语句即可 yum -y install ncurses-devel 如果上述命令的结果是no package,则使用下面的命令安装 apt-get insta ...
- Breaking Biscuits(模板题-求凸边形的宽)
Breaking Biscuits 时间限制: 1 Sec 内存限制: 128 MB Special Judge提交: 70 解决: 26[提交] [状态] [讨论版] [命题人:admin] ...
- Win10预览版激活信息
微软在10月2日零点正式公开了Win10预览版的下载地址,这个时间大家应该逐步开始安装工作了,因此提出下面两个问题的用户特别多,IT之家再稍作告知一下.1.Win10预览版安装密钥是什么?答:NKJF ...
- HTML5<fieldset>标签
1.<fieldset>标签对表单中的相关元素进行分组. 2.<fieldset>标签会在相关表单元素周围绘制边框. <!DOCTYPE html><html ...
- 3.vue引入axios全局配置
前言: Vue官方推荐使用axios来进行异步访问. axios文档参考:axios中文文档 开始搭建: 1.引入axios (1)打开终端 win+R (2)切换到项目路径: g: cd Webap ...
- ES6初识- Class
{ //基本定义和生成实例 class Parent{ //构造函数 constructor(name='lisi'){ this.name=name; } //属性get,set get longN ...
- 牛客小白月赛1 I あなたの蛙が帰っています 【卡特兰数】
链接:https://www.nowcoder.com/acm/contest/85/I题目描述 あなたの蛙が帰っています! 蛙蛙完成了一趟旅行,回家啦!但它还是没有去它心中非常想去的几个地方.总共 ...
- 基于THINKPHP+layui+Ajax无刷新实现图片上传预览
<fieldset class="layui-elem-field" style="width:500px;margin:50px 0 0 300px;" ...
- C语言数组篇(一)一维数组
0. 数组的两种表现形式 一种是常见的a[10]; //初学者常用 另一种是用指针表示的数组. //实际工程使用.常用于参数传递 ...