【python爬虫实战】用python爬取爱奇艺电视剧十大榜单的全部数据!
一、爬取目标
本次爬取的目标是,爱奇艺电视剧类目下的10个榜单:电视剧风云榜-爱奇艺风云榜
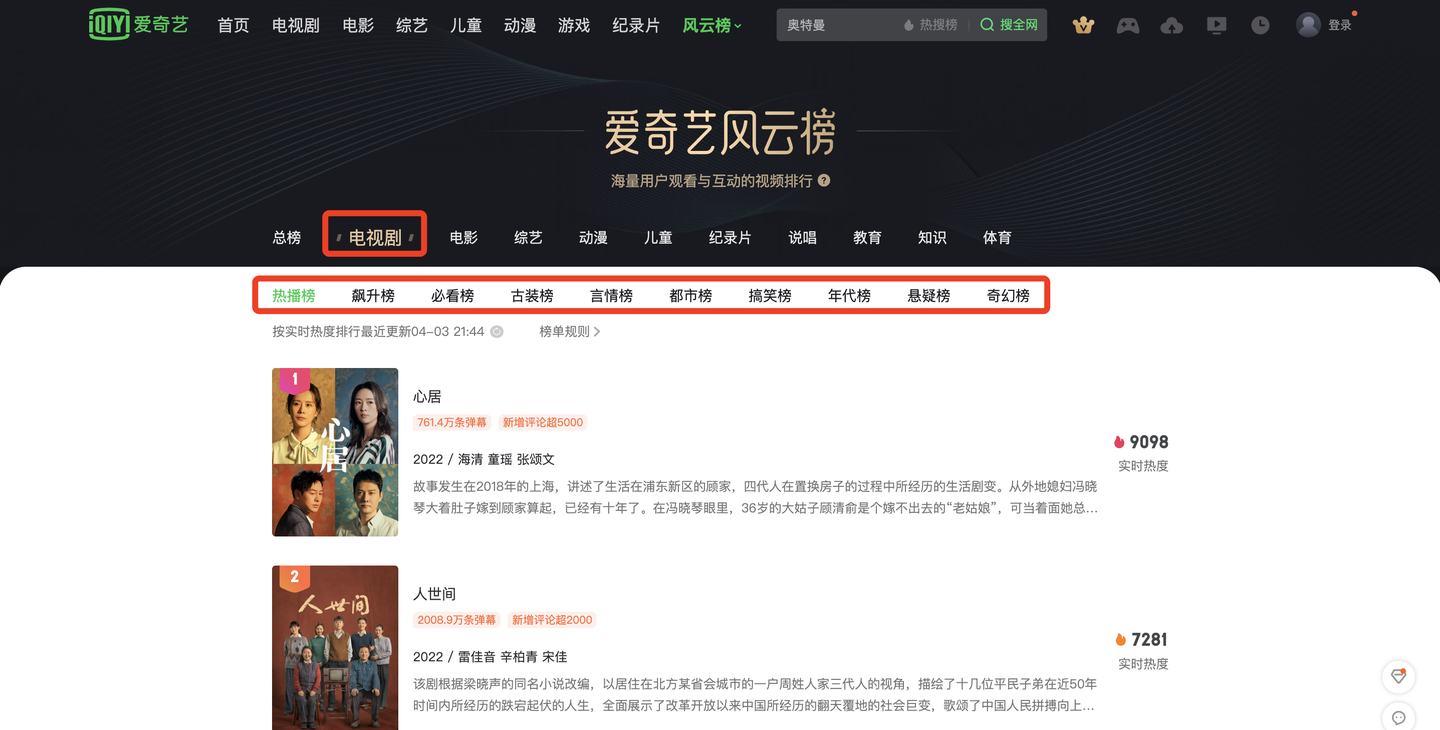
可以看到,这10个榜单包含了:
热播榜、飙升榜、必看榜、古装榜、言情榜、都市榜、搞笑榜、年代榜、悬疑榜、奇幻榜。
我们以热播榜为例,打开Chrome浏览器,按F12进入开发者模式,选择网络 -> XHR这个选项,重新刷新一下页面,并且逐次下拉页面到最底部,展现出全部100部电视剧:
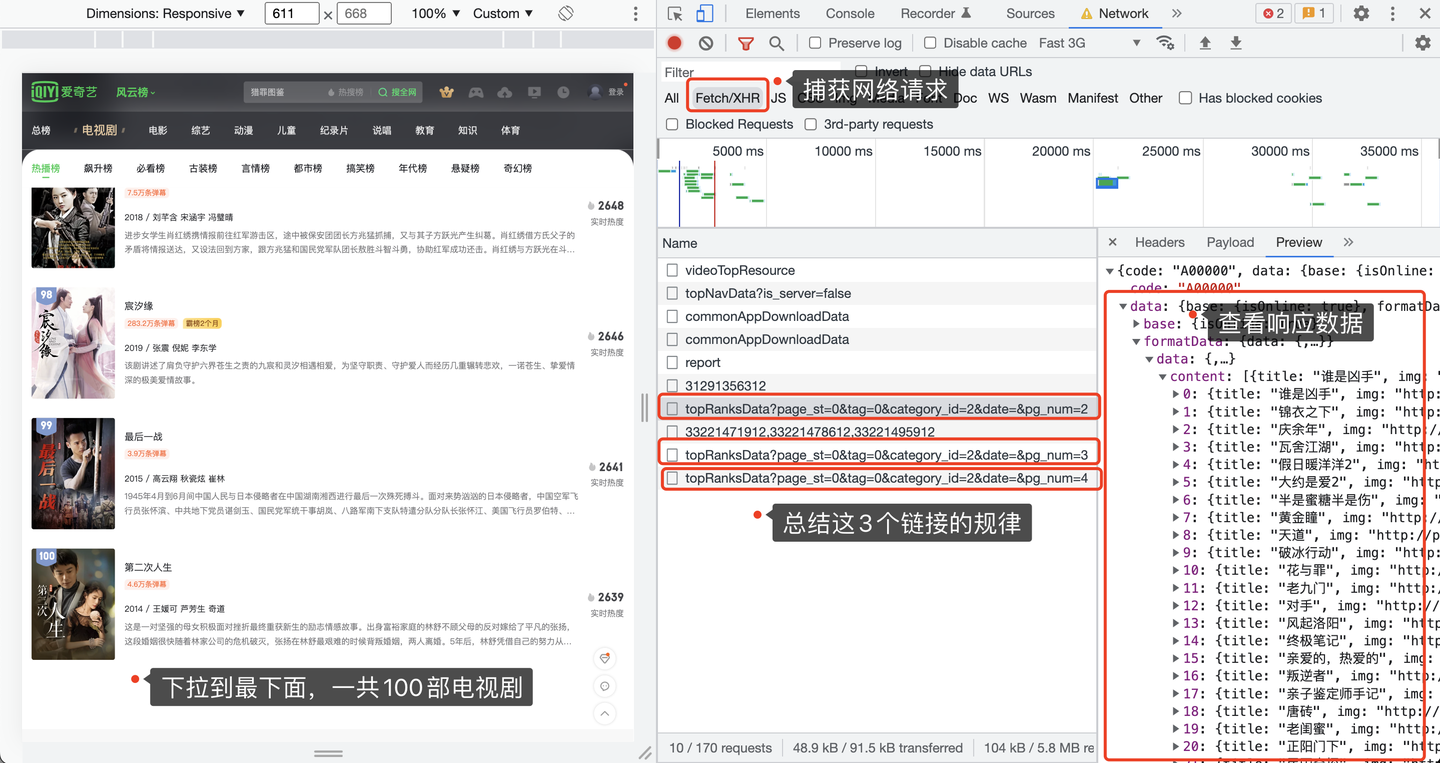
查看捕获到的请求链接地址,每翻一次页,出现一条链接地址,并且该地址的响应数据就是20条电视剧的数据。
所以,这个地址就是我们要请求的地址了。
二、讲解代码
首先,导入需要用到的爬虫库:
import requests # 发送请求
import pandas as pd # 存入excel文件
from time import sleep # 随机等待,防止反爬
import random # 设置随机
从请求地址的Request Header处,拷贝过来一个请求头,放到代码里:
headers = {
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'origin': 'https://www.iqiyi.com',
'referer': 'https://www.iqiyi.com/',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
'sec-ch-ua-mobile': '?1',
'sec-ch-ua-platform': '"Android"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Mobile Safari/537.36'
}
爱奇艺的这个榜单页面,反爬不那么厉害,请求头中连cookie都不用加!
由于我想自动爬取这10个榜单,每个榜单对应一个tag标签,从哪里获取呢?经过分析,是从另外一个请求地址返回的:
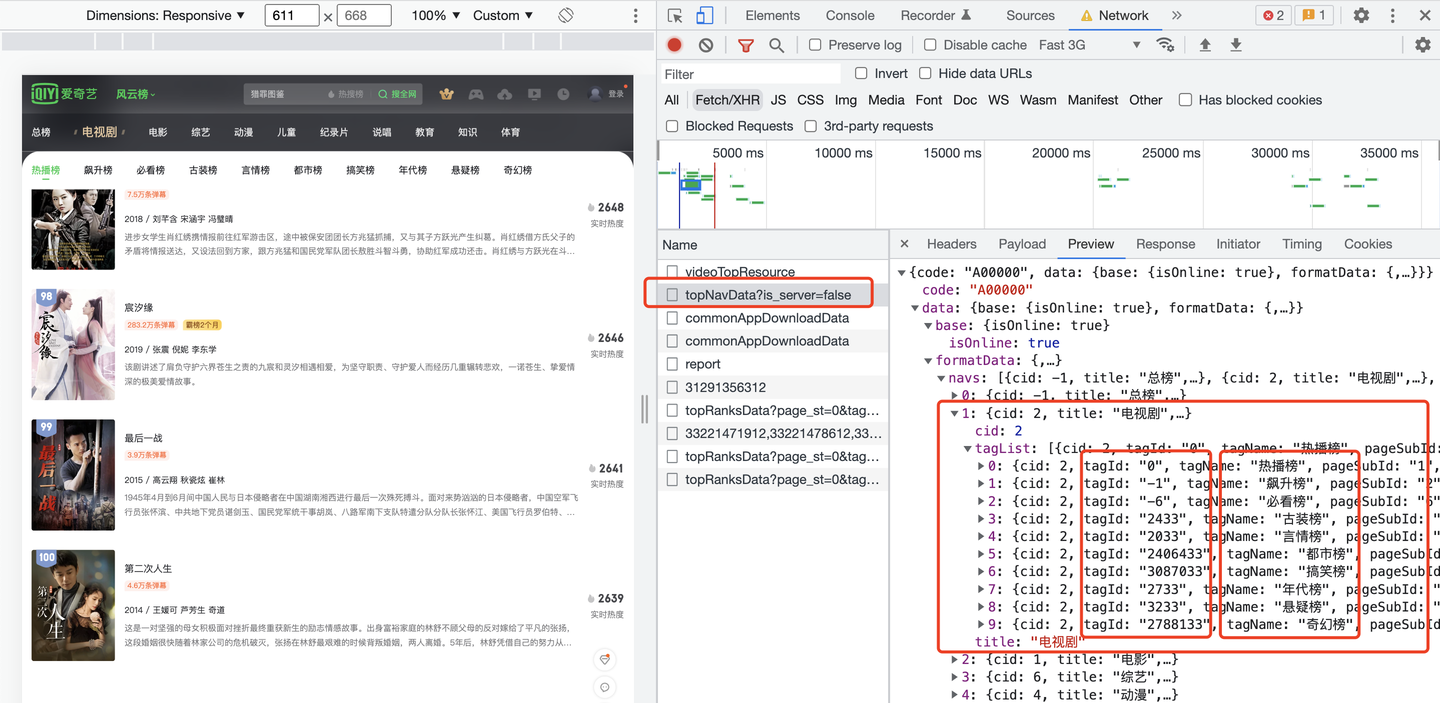
发现了吗?每个榜单名称是一个tagName,对应一个tagId。拿到tagId,带入到榜单数据的请求地址中:
for page in range(1, 5):
url = 'https://pcw-api.iqiyi.com/strategy/pcw/data/topRanksData?page_st={}&tag={}&category_id=2&date=&pg_num={}'.format(v_tag_id, v_tag_id, page)
r = requests.get(url, headers=headers)
这样,就完成了向页面发送请求的过程。
顺便说一下这个for循环,一共翻4页,每页25条数据,对应一共100部电视剧。
用json格式接收返回的数据:
json_data = r.json()
然后开始解析json数据:
content_list = json_data['data']['formatData']['data']['content']
for content in content_list:
# 排名
order_list.append(order)
# 标题
title_list.append(content['title'])
print(order, ' ', content['title'])
# 描述
try:
desc_list.append(content['desc'])
except:
desc_list.append('')
# 标签
tags_list.append(content['tags'])
tag_info = content['tags'].split(' / ')
# 上映年份
year = tag_info[0]
year_list.append(year)
# 主演
actor = tag_info[-1]
actor_list.append(actor)
# 弹幕
try:
danmu_list.append(content['danmu'].replace('条弹幕', ''))
except:
danmu_list.append('')
# 霸榜
try:
babang_list.append(content['babang'])
except:
babang_list.append('')
# 实时热度
if v_tag_name == '飙升榜':
index_list.append(content['index'] + '%')
else:
index_list.append(content['index'])
order += 1
最后,依然采用我最顺手的方法,拼装成DataFrame的格式,保存到excel文件:
df = pd.DataFrame({
'排名': order_list,
'标题': title_list,
'描述': desc_list,
'标签': tags_list,
'上映年份': year_list,
'主演': actor_list,
'弹幕': danmu_list,
'霸榜': babang_list,
'实时热度': index_list,
})
if v_tag_name == '飙升榜': # 如果是飙升榜,把excel标题中的'实时热度'改为'飙升幅度'
df.rename(columns={'实时热度': '飙升幅度'}, inplace=True)
df.to_excel('爱奇艺电视剧_{}.xlsx'.format(v_tag_name), index=False)
这里,需要注意一个小逻辑,飙升榜的'实时热度'需要rename为'飙升幅度',因为飙升榜跟其他榜单不一样!

三、查看结果
共爬取到10个榜单文件:
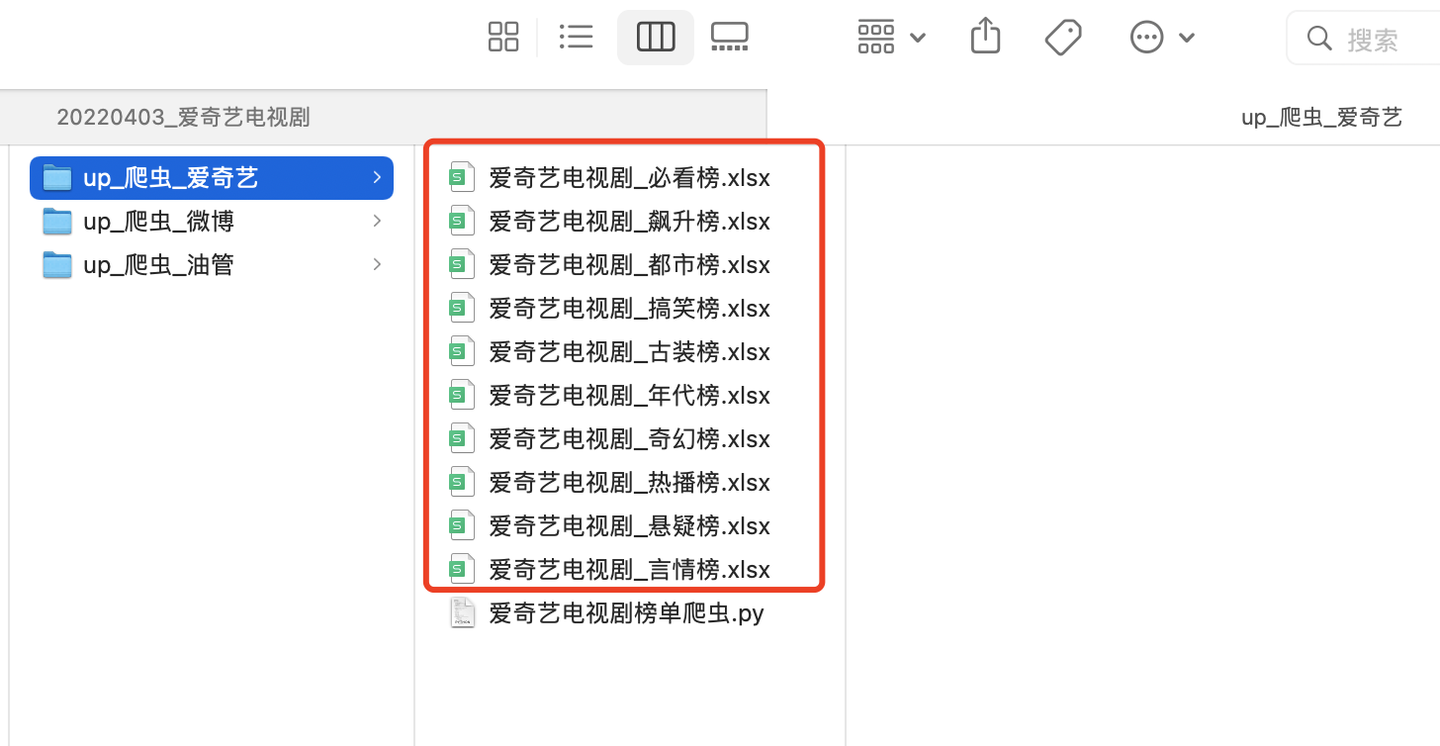
随便打开一个文件,比如,热播榜:
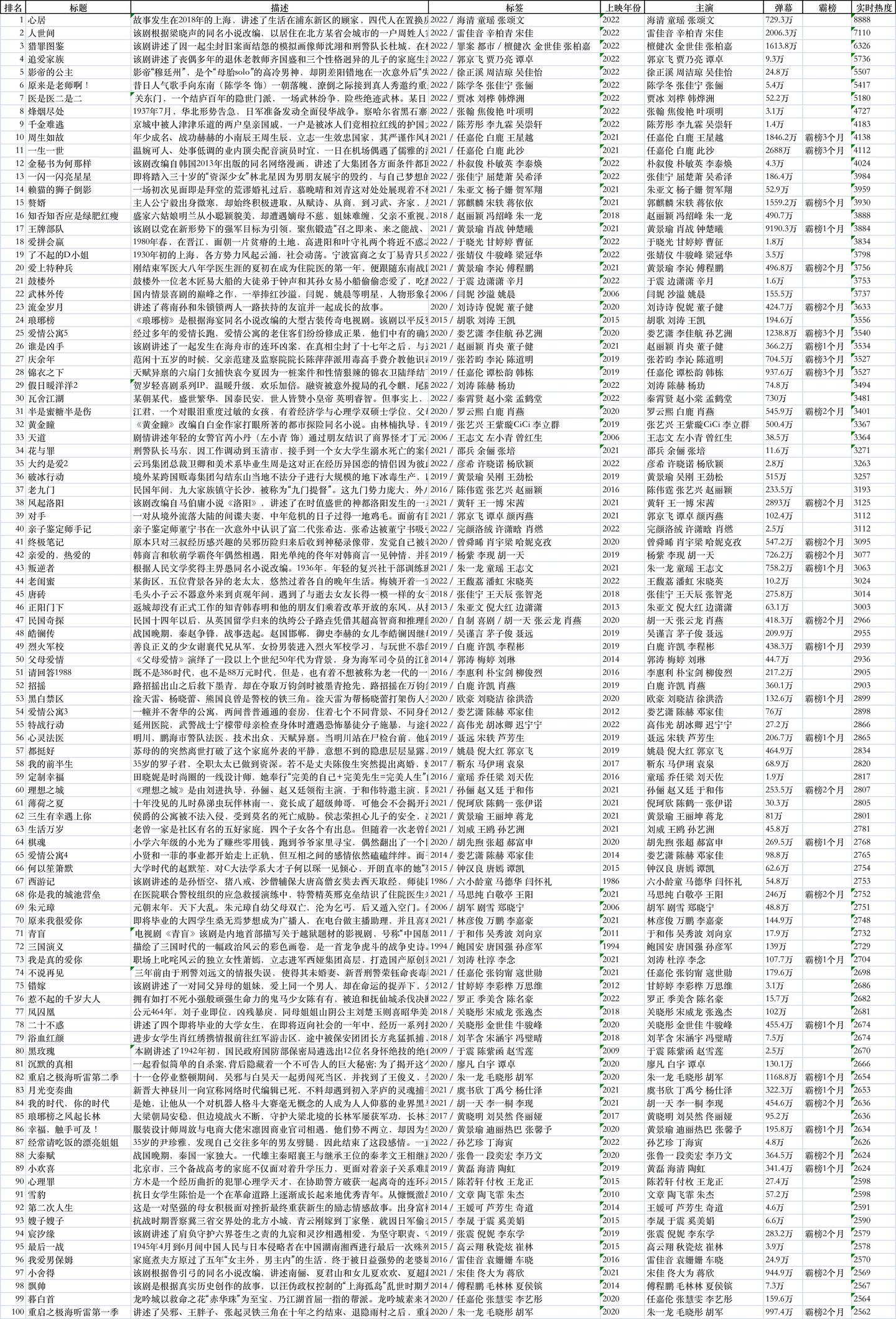
比如,都市榜:
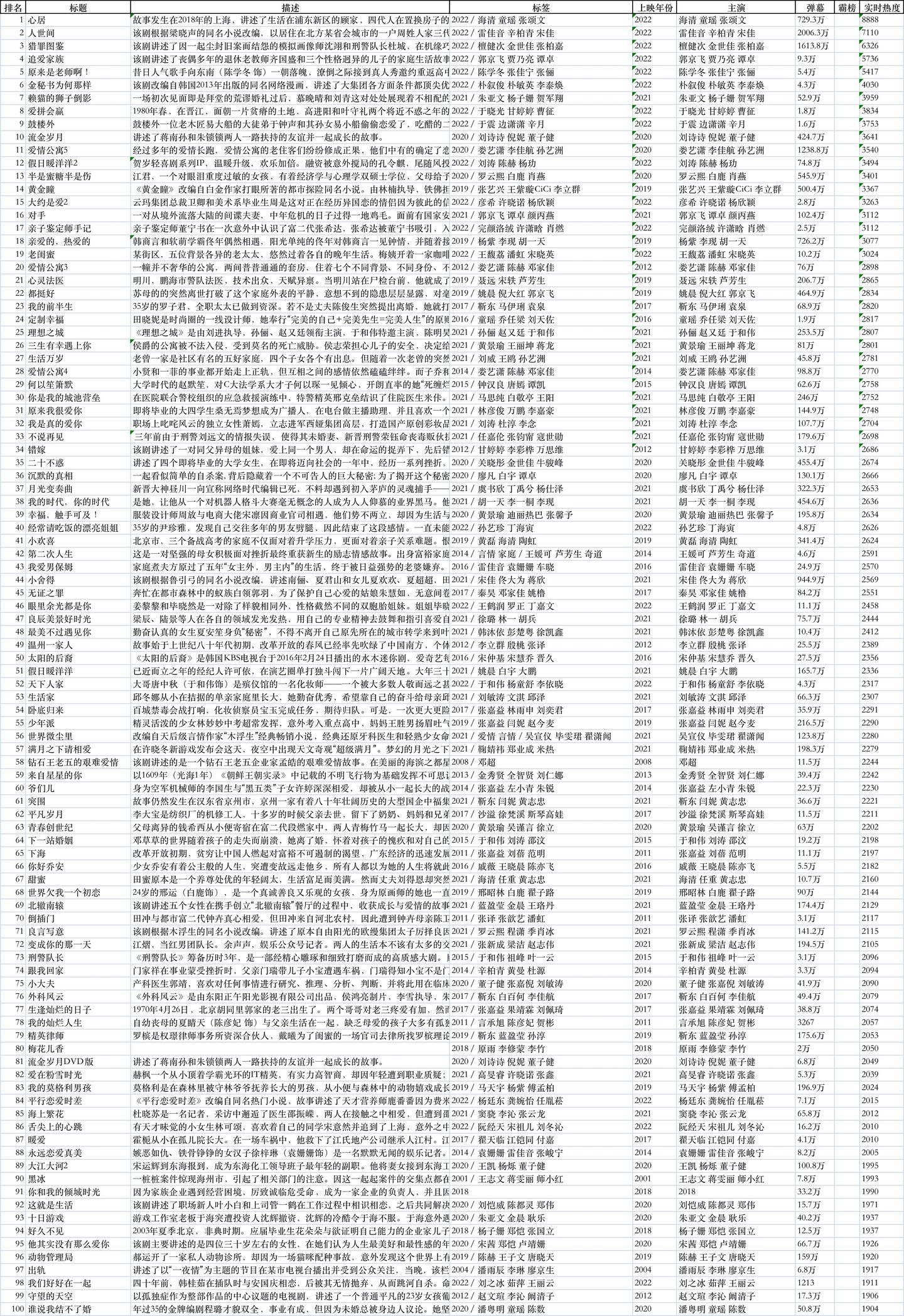
除了搞笑榜有40+条数据,其他榜单都是100条数据,对应100部电视剧。
四、视频演示
代码演示视频:https://www.bilibili.com/video/BV1fT4y1e7wd/
五、附完整源码
完整源码:【python爬虫实战】用python爬取《爱奇艺风云榜》电视剧十大榜单!2023.6发布
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫实战】用python爬取爱奇艺电视剧十大榜单的全部数据!的更多相关文章
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- 爬取爱奇艺电视剧url
----因为需要顺序,所有就用串行了---- import requests from requests.exceptions import RequestException import re im ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- 使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息 转载请注明出处. 爬取目标:每个电影的评分.名称.时长.主演.和类型 爬取思路: 源文件:(有注释) from selenium import webd ...
- Python 爬虫实例(5)—— 爬取爱奇艺视频电视剧的链接(2017-06-30 10:37)
1. 我们找到 爱奇艺电视剧的链接地址 http://list.iqiyi.com/www/2/-------------11-1-1-iqiyi--.html 我们点击翻页发现爱奇艺的链接是这样的 ...
- 如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7 思路: 1.先选取你要爬取的电影 2.用vip解析工具解析,获取地址 3.写好脚本,下载片断 4.将片断利用电脑合成 需要的python模块: ##第一 ...
随机推荐
- 在基于vue-next-admin的Vue3+TypeScript前端项目中,为了使用方便全局挂载的对象接口
在基于vue-next-admin 的 Vue3+TypeScript 前端项目中,可以整合自己的 .NET 后端,前端操作一些功能的时候,为了使用方便全局挂载的对象接口,以便能够快速处理一些特殊的操 ...
- 全网最详细中英文ChatGPT-GPT-4示例文档-从0到1快速入门计算时间复杂度应用——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)
目录 Introduce 简介 setting 设置 Prompt 提示 Sample response 回复样本 API request 接口请求 python接口请求示例 node.js接口请求示 ...
- Module not found: Error: Can't resolve 'pubsub-js'
包未安装或者包版本过新,再者安装位置有误. 我安装各种工具库或者其他包时有个 -g 到全局的习惯,觉得装到全局时在文件夹中何时何处都可以用. 在子孙文件夹中引入时依赖会在子孙和文件根目录的node_m ...
- Lodash中常用函数,不建议经常使用,容易让人变懒忘了原生函数
1.N次循环 <script type="text/javascript"> console.log('------- javascript -------'); // ...
- [Linux]常用命令之【hostname】
1: 个人的片面理解: hostname是主机名(的"昵称"),而非域名.一般设置hostname,来标识当前机器的主要用途.以区别与其它机器 2: hostname的严格定义: ...
- 四月二十六java基础知识
1..对文件的随机访问:前面介绍的流类实现的是磁盘文件的顺序读写,而且读和写分别创建不同的对象,java语言中还定义了一个功能强大.使用更方便的随机访问类RandomAcessFile它可以实现文件的 ...
- Spring入门系列:浅析知识点
前言 讲解Spring之前,我们首先梳理下Spring有哪些知识点可以进行入手源码分析,比如: Spring IOC依赖注入 Spring AOP切面编程 Spring Bean的声明周期底层原理 S ...
- 对抗 ChatGPT,免费体验 Claude
对抗 ChatGPT,免费体验 Claude Claude 是 Anthropic 构建的大型语言模型(LLM),对标ChatGPT. Anthropic 创始团队多是前openai研究员和工程师,C ...
- C#写一套最全的MySQL帮助类(包括增删改查)
介绍说明:这个帮助类包含了六个主要的方法:ExecuteNonQuery.ExecuteScalar.ExecuteQuery.ExecuteQuery(泛型).Insert.Update和Delet ...
- Python 列表的修改、添加和删除元素
列表修改.添加和删除元素 大多数创建的列表都是动态的,随程序的运行增删元素 修改列表元素 指定列表名和要修改的元素的索引,再指定要修改元素的新值 # 修改列表元素案例 motorcycles = [' ...