机器学习-线性分类-支持向量机SVM-SMO算法代码实现-15
1. alpha2 的修剪
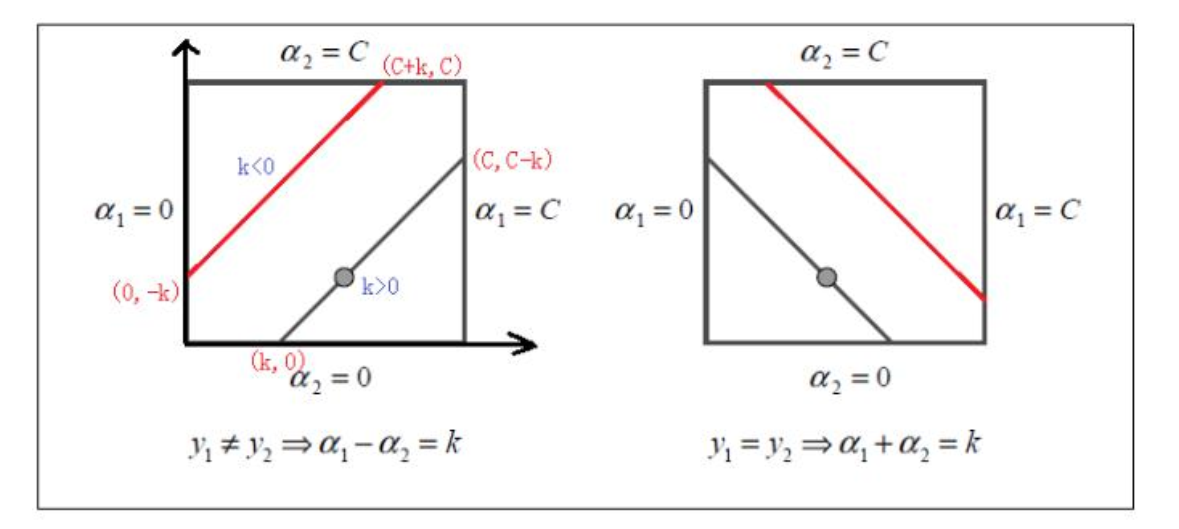
if y1 != y2 :
α1 - α2 = k # 不用算k的具体大小
if k > 0: # 上图的左 下这条线
α2 的区间 (0, c-k)
k < 0 : # 上图的左 下这条线
α2 的区间 (-k, C)
所以:
L = max(0, -k) # k>0 还是<0 都统一表达了
H = min(c, c-k)
else:
y1 = y2 右边的图 同理
2.参考
参考:https://zhuanlan.zhihu.com/p/49331510
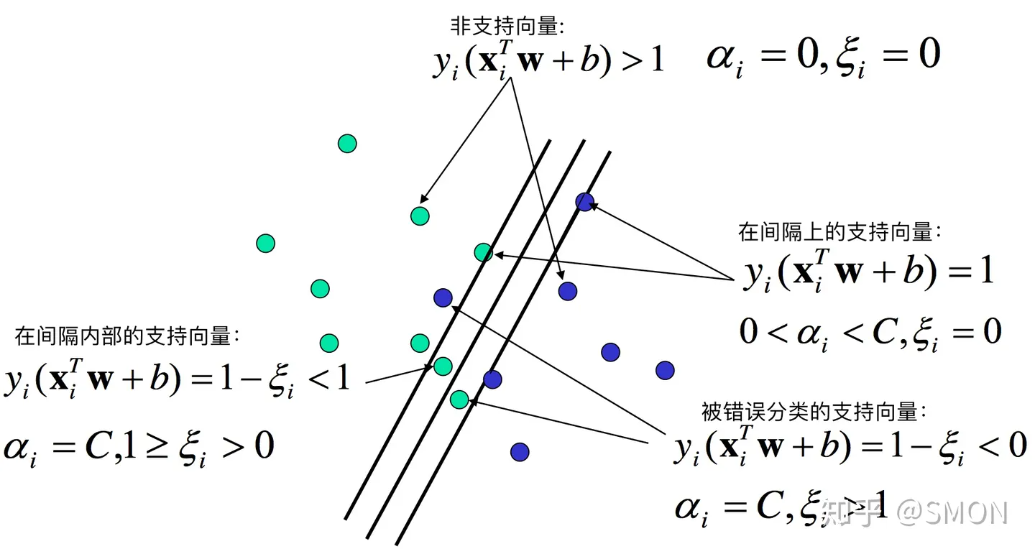
非支撑向量:
alpha=0
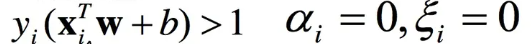
间隔上的支撑向量:
0<alpha<c

间隔之内:
alpha=c and 0< ei <1
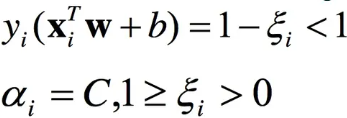
上面的三种都是正确分类的;
错误分类的:

alpha=c and ei > 1
yi(wxi+b) = 1-ei < 0 使负的 预测的与实际的符号相反
3. 代码实现
"""
算法思想:
创建一个alpha向量 并初始化为0
当迭代次数小于 最大迭代次数(外层循环):
遍历α中的每一个αi(内层循环):
如果该αi可以被优化:
随机选择另一个αj
同时优化 αi aj
如果αi aj优化完毕退出内层循环
"""
import numpy
import numpy as np
import random
import matplotlib.pyplot as plt
def load_data(filename):
X = []
y = []
fr = open(filename)
for line in fr.readlines():
x1, x2, y_true = line.strip().split("\t")
X.append([float(x1), float(x2)])
y.append(float(y_true))
fr.close()
return numpy.array(X), np.array(y)
def show_data(filename, line=None):
X, y = load_data("./testSet.txt")
class_1_index = np.where(y == -1) # -1 负样本的索引
X_class_1 = X[class_1_index, :].reshape(-1, 2) # 负样本对应的X取出
class_2_index = np.where(y == 1) # +1 正样本的索引
X_class_2 = X[class_2_index, :].reshape(-1, 2) # 正样本对应的X取出
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter(X_class_1[:, 0], X_class_1[:, 1], c="r", label="$-1$")
ax.scatter(X_class_2[:, 0], X_class_2[:, 1], c="g", label="$+1$")
plt.legend()
if line is not None:
alphas, b = line
x = np.linspace(1, 8, 50)
w = np.sum(alphas*y[:, np.newaxis]*X, axis=0)
# w1*x1 + w2*x2 +b = 0 # 或者 +1 -1
y = np.array([(-b - w[0]*x[i]) / w[1]for i in range(50)])
y1 = np.array([(1 -b - w[0]*x[i]) / w[1]for i in range(50)])
y2 = np.array([(-1 -b - w[0]*x[i]) / w[1]for i in range(50)])
ax.plot(x, y, "b-")
ax.plot(x, y1, "b--")
ax.plot(x, y2, "b--")
plt.show()
def smo_simple(dataArr, yArr, C, toler, maxIter):
numSample, numDim = dataArr.shape # 100行 2列
# 初始化
b = 0
alphas = np.zeros((numSample, 1))
iterations = 0 # 迭代次数
while iterations < maxIter:
alphaPairsChanged = 0
for i in range(numSample):
# 针对对i个样本给出预测值 这里没有使用核函数变换
# fXi= wXi+b
# alphas * y * X * Xi +b Xi为一条样本
fXi = np.sum(alphas * yArr[:, np.newaxis] * dataArr * dataArr[i, :]) + b
# Ei 为误差
Ei = fXi - yArr[i]
"""
kkt 约束条件:
yi*(wXi+b) >= 1 且alpha=0 远离边界 正常分类的 ----条件1
yi*(wXi+b) = 1 且0<alpha<c 边界上面
yi*(wXi+b) < 1 且 alpha=c 两条边界之间 ----条件2
# 0 <= alphas[i] <= C 已经在边界上的 alpha不能再优化
Ei = fXi - yArr[i] 两边都 乘以 yArr[i]
yArr[i]*Ei = yArr[i]*fXi - 1 # 偏差
如果 yArr[i]*Ei < -toler alpha应该为C 如果<C 就需要优化 ----对应条件2
如果 yArr[i]*Ei > toler alpha应该为0 如果>0 就需要优化 ----对应条件1
"""
if ( (yArr[i]*Ei < -toler) and (alphas[i] < C) ) or ( (yArr[i]*Ei > toler) and (alphas[i] > 0)):
# 进入这里 说明需要优化alpha[i] 我们在随机取一条alpha[j] j!=i
j = selectJrand(i, numSample)
fXj = np.sum(alphas * yArr[:, np.newaxis] * dataArr * dataArr[j, :]) + b
Ej = fXj - yArr[j]
# 先复制一份old alphaI alphaJ
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
# 根据 yArr[i] yArr[j] 是否同号 计算 L H
if yArr[i] != yArr[j]:
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H:
print("L == H")
continue
# 计算 eta, eta是alpha[j]的最大修正量 eta == 0 则 continue
# eta = K(1,1)+K(2,2) - 2K(1,2)
eta = (np.sum(dataArr[i,:] * dataArr[i, :]) +
np.sum(dataArr[j, :] * dataArr[j, :]) -
2 * np.sum(dataArr[i,:] * dataArr[j, :]))
if eta == 0:
continue
# 计算新的alphas[j]
alphas[j] = alphaJold + yArr[j]*(Ei - Ej) / eta
# 修剪新的alphas[j]
alphas[j] = clipAlpha(alphas[j], H, L)
# 新的alphas[j] 与 alphaJold 如果改动量很小 则 contine 退出
if abs(alphaJold - alphas[j]) < 0.00001:
continue
# 更新 alphas[i]
alphas[i] = alphaIold + yArr[i] * yArr[j] * (alphaJold - alphas[j])
# 计算参数b
bi = b - Ei - yArr[i] * (alphas[i] - alphaIold) * np.sum(dataArr[i, :] * dataArr[i, :]) - \
yArr[j] * (alphas[j] - alphaJold) * np.sum(dataArr[i, :] * dataArr[j, :])
bj = b - Ej - yArr[i] * (alphas[i] - alphaIold) * np.sum(dataArr[i, :] * dataArr[j, :]) - \
yArr[j] * (alphas[j] - alphaJold) * np.sum(dataArr[j, :] * dataArr[j, :])
if 0<alphas[i]<C:
b = bi
elif 0<alphas[j]<C:
b = bj
else:
b = (bi+bj)/2
# 走到这里说明 alpha b 更新了
alphaPairsChanged += 1
# 输出
print(f"iter: {iterations}, i: {i}, pairs changed: {alphaPairsChanged}")
if alphaPairsChanged ==0:
iterations += 1
else:
iterations =0
return b, alphas
def selectJrand(i, numSample):
j = i
while j == i:
j = int(random.uniform(0, numSample))
return j
def clipAlpha(aj, H, L):
if aj > H:
return H
if aj < L:
return L
return aj
if __name__ == '__main__':
X, y = load_data("./testSet.txt")
C = 0.6
toler = 0.001
maxIter = 40
b, alphas = smo_simple(X, y, C, toler, maxIter)
print(b)
print(alphas)
show_data("./testSet.txt", line=(alphas, b))

4. 优缺点
任何算法都有其优缺点,支持向量机也不例外。
支持向量机的优点是:
由于SVM是一个凸优化问题,所以求得的解一定是全局最优而不是局部最优。
不仅适用于线性线性问题还适用于非线性问题(用核技巧)。
拥有高维样本空间的数据也能用SVM,这是因为数据集的复杂度只取决于支持向量而不是数据集的维度,这在某种意义上避免了“维数灾难”。
理论基础比较完善(例如神经网络就更像一个黑盒子)。
支持向量机的缺点是:
二次规划问题求解将涉及m阶矩阵的计算(m为样本的个数), 因此SVM不适用于超大数据集。(SMO算法可以缓解这个问题)
只适用于二分类问题。(SVM的推广SVR也适用于回归问题;可以通过多个SVM的组合来解决多分类问题
机器学习-线性分类-支持向量机SVM-SMO算法代码实现-15的更多相关文章
- SVM-非线性支持向量机及SMO算法
SVM-非线性支持向量机及SMO算法 如果您想体验更好的阅读:请戳这里littlefish.top 线性不可分情况 线性可分问题的支持向量机学习方法,对线性不可分训练数据是不适用的,为了满足函数间隔大 ...
- 线性可分支持向量机--SVM(1)
线性可分支持向量机--SVM (1) 给定线性可分的数据集 假设输入空间(特征向量)为,输出空间为. 输入 表示实例的特征向量,对应于输入空间的点: 输出 表示示例的类别. 线性可分支持向量机的定义: ...
- 统计学习:线性可分支持向量机(SVM)
模型 超平面 我们称下面形式的集合为超平面 \[\begin{aligned} \{ \bm{x} | \bm{a}^{T} \bm{x} - b = 0 \} \end{aligned} \tag{ ...
- 机器学习算法整理(七)支持向量机以及SMO算法实现
以下均为自己看视频做的笔记,自用,侵删! 还参考了:http://www.ai-start.com/ml2014/ 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还 ...
- 机器学习笔记:支持向量机(svm)
支持向量机(svm)英文为Support Vector Machines 第一次接触支持向量机是2017年在一个在线解密游戏"哈密顿行动"中的一个关卡的二分类问题,用到了台湾教授写 ...
- 支持向量机的smo算法(MATLAB code)
建立smo.m % function [alpha,bias] = smo(X, y, C, tol) function model = smo(X, y, C, tol) % SMO: SMO al ...
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
随机推荐
- C++ Qt 开发:ListWidget列表框组件
Qt 是一个跨平台C++图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍ListWid ...
- IDEA美化教程
一.IDEA 字体大小怎么设置(图文教程) IDEA 初次安装时,默认字体非常小,这种情况下,代码阅读起来非常费劲,对保护视力非常不友好.那么,要如何在 IDEA 中设置字体大小呢? 这里介绍两种方法 ...
- Python——第一章:占位——pass
pass: 常用于代码占位 a = 10 if a > 100: pass 当设计代码时,有些条件或代码还没有想好要如何处理,先用pass做占位,后续可以回来继续写.如果不写pass则会报错,因 ...
- linux中iptables防火墙相关命令
https://www.cnblogs.com/seven1979/p/4173927.html https://blog.csdn.net/shenjianxz/article/details/62 ...
- libGDX游戏开发之Sprite、Texture和TextureRegion绘制旋转、反转(九)
libGDX游戏开发之Sprite.Texture和TextureRegion绘制反转(九) libGDX系列,游戏开发有unity3D巴拉巴拉的,为啥还用java开发?因为我是Java程序员emm- ...
- 使用推测解码 (Speculative Decoding) 使 Whisper 实现 2 倍的推理加速
Open AI 推出的 Whisper 是一个通用语音转录模型,在各种基准和音频条件下都取得了非常棒的结果.最新的 large-v3 模型登顶了 OpenASR 排行榜,被评为最佳的开源英语语音转录模 ...
- 文心一言 VS 讯飞星火 VS chatgpt (53)-- 算法导论6.2 5题
五.MAX-HEAPIFY的代码效率较高,但第 10 行中的递归调用可能例外,它可能使某些编译器产生低效的代码.请用循环控制结构取代递归,重写 MAX-HEAPIFY代码. 文心一言: 以下是使用循环 ...
- 详解ZooKeeper在微服务注册中心的应用
本文分享自华为云社区<SpringCloud ZooKeeper 详解,以及与Go.Rust等非Java服务的集成>,作者: 张俭. ZooKeeper,是一个开源的分布式协调服务,不仅支 ...
- 《华为云DTSE》期刊2023年第二季—HDC.Cloud 2023专刊
本文分享自华为云社区<<华为云DTSE>期刊2023年第二季-HDC.Cloud 2023专刊>,作者: HuaweiCloudDeveloper . AI技术风起云涌,百家争 ...
- 手把手教您在PyCharm中连接云端资源进行代码调试
摘要:ModelArts提供了一个PyCharm插件工具PyCharm ToolKit,协助用户完成代码上传.提交训练作业.将训练日志获取到本地展示等,用户只需要专注于本地的代码开发即可. 本文分享自 ...