DVT:华为提出动态级联Vision Transformer,性能杠杠的 | NeurIPS 2021
论文主要处理Vision Transformer中的性能问题,采用推理速度不同的级联模型进行速度优化,搭配层级间的特征复用和自注意力关系复用来提升准确率。从实验结果来看,性能提升不错
来源:晓飞的算法工程笔记 公众号
论文: Not All Images are Worth 16x16 Words: Dynamic Transformers for Efficient Image Recognition

- 论文地址:https://arxiv.org/abs/2105.15075
- 论文代码:https://github.com/blackfeather-wang/Dynamic-Vision-Transformer
Introduction
Transformers是自然语言处理 (NLP) 中占主导地位的自注意的模型,最近很多研究将其成功适配到图像识别任务。这类模型不仅在ImageNet上取得了SOTA,而且性能还能随着数据集规模的增长而不断增长。这类模型一般都先将图像拆分为固定数量的图像块,然后转换为1D token作为输入,拆分更多的token有助于提高预测的准确性,但也会带来巨额的计算成本(与token数成二次增长)。为了权衡性能和准确率,现有的这类模型都采用14x14或16x16的token数量。
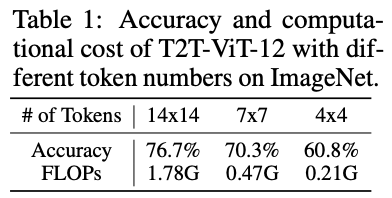
论文认为不同图片之间存在相当大的差异,使用相同数量的token处理所有图片并不是最优的。最理想的做法应为每个输入专门配置token数量,这也是模型计算效率的关键。以T2T-ViT-12为例,官方推荐的14x14 token数仅比4x4 token数增加了15.9%(76.7% 对 60.8%)的准确率,却增加了8.5倍的计算成本(1.78G 对 0.21G)。也就是说,对“简单”图片使用14x14 token数配置浪费了大量计算资源,使用4x4 token数配置就足够了。
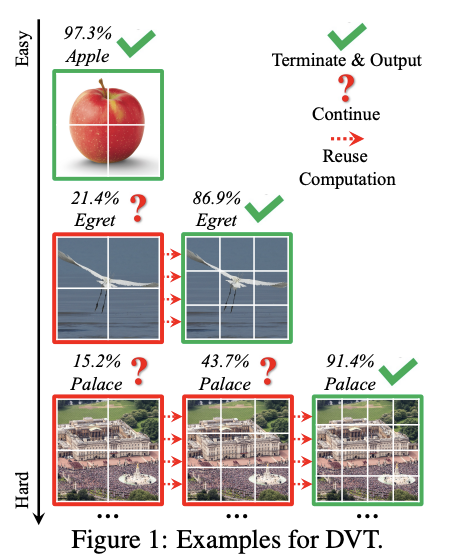
受此启发,论文提出了一种动态Vision Transformer(DVT)框架,能够根据每个图片自动配置合适的token数,实现高效计算。训练时使用逐渐增多的token数训练级联Transformer,测试时从较少的token数开始依次推理,得到置信度足够的预测即终止推理过程。通过自动调整token数,“简单”样本和“困难”样本的计算消耗将会不一样,从而显着提高效率。
另外,论文还设计了基于特征和基于关系的两种复用机制,减少冗余的计算。前者允许下游模型在先前提取的深度特征上进行训练,而后者允许利用上游模型中的自注意力关系来学习更准确的注意力图。
DVT是一个通用框架,可集成到大多数图像识别的Transformer模型中。而且可以通过简单地调整提前终止标准,在线调整整体计算成本,适用于计算资源动态波动或需要以最小功耗来实现特定性能的情况。从ImageNet和CIFAR的实验结果来看,在精度相同的情况下,DVT能将T2T-ViT的计算成本降低1.6-3.6倍,而在NVIDIA 2080Ti上的真实推理速度也与理论结果一致。
Dynamic Vision Transformer
Overview
Inference
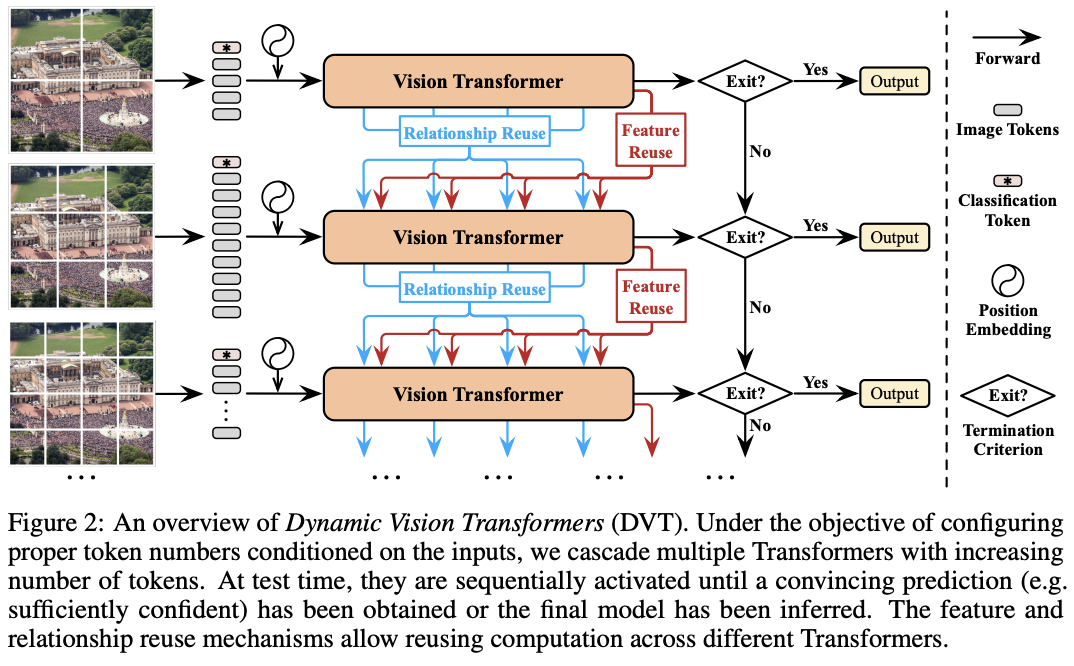
DVT的推理过程如图2所示。对于每张测试图片,先使用少量1D token序列对其进行粗略表示,可通过直接使用分割图像块或利用如tokens-to-token模块之类的技术来实现,然后通过Vision Transformer对这些token进行快速预测。由于Transformer的计算消耗与token数量成二次增长,所以这个过程很快。最后基于预设的终止标准对预测结果进行快速评估,确定是否足够可靠。
如果预测未能满足终止标准,原始输入图像将被拆分为更多token,再进行更准确、计算成本更高的推理。每个token embedding的维度保持不变,只增加token数量,从而实现更细粒度的表示。此时推理使用的Vision Transformer与上一级具有相同架构,但参数是不同的。根据设计,此阶段在某些“困难”测试图片上权衡计算量以获得更高的准确性。为了提高效率,新模型可以复用之前学习的特征和关系。在获得新的预测结果后,同样根据终止标准进行判断,不符合则继续上述过程,直到结果符合标准或已使用最终的Vision Transformer。
Training
训练时,需保证DVT中所有级联Vision Transformer输出正确的预测结果,其优化目标为:
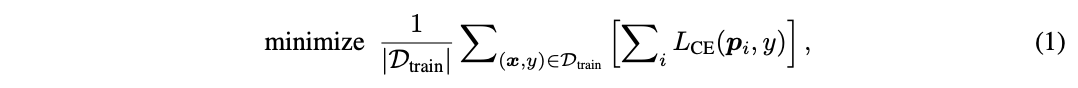
其中,\((x, y)\)为训练集\(D_{train}\)中的一个样本及其对应的标签,采用标准的交叉熵损失函数\(L_{CE}(·)\),而\(p_i\)表示第\(i\)个模型输出的softmax预测概率。
Transformer backbone
DVT是一个通用且灵活的框架,可以嵌入到大多数现有的Vision Transformer模型(如ViT、DeiT和T2T-ViT)之中,提高其性能。
Feature and Relationship Reuse
DVT的一个重要挑战是如何进行计算的复用。在使用的具有更多token的下游Vision Transformer时,直接忽略之前模型中的计算结果显然是低效的。虽然上游模型的token数量较少,但也提取了对预测有价值的信息。因此,论文提出了两种机制来复用学习到的深度特征和自注意力关系,仅增加少量的额外计算成本就能显着提高准确率。
Background
介绍前,先重温一下Vision Transformer的基本公式。Transformer encoder由交替堆叠的多头自注意力(MSA)和多层感知器 (MLP)块组成,每个块的之前和之后分别添加了层归一化(LN)和残差连接。定义\(z_l\in R^{N\times D}\)表示第\(l\)层的输出,其中\(N\)是样本的token数,\(D\)是token的维度。需要注意的是,\(N=HW+1\),对应\(H\times W\)图像块和可学习的分类token。假设Transformer共\(L\)层,则整个模型的计算可表示为:
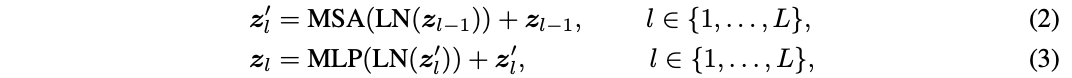
得到最终的结果\(z_L\)后,取其中的分类token通过LN层+全连接层进行最终预测。这里省略了position embedding的细节,论文没有对其进行修改。
Feature reuse
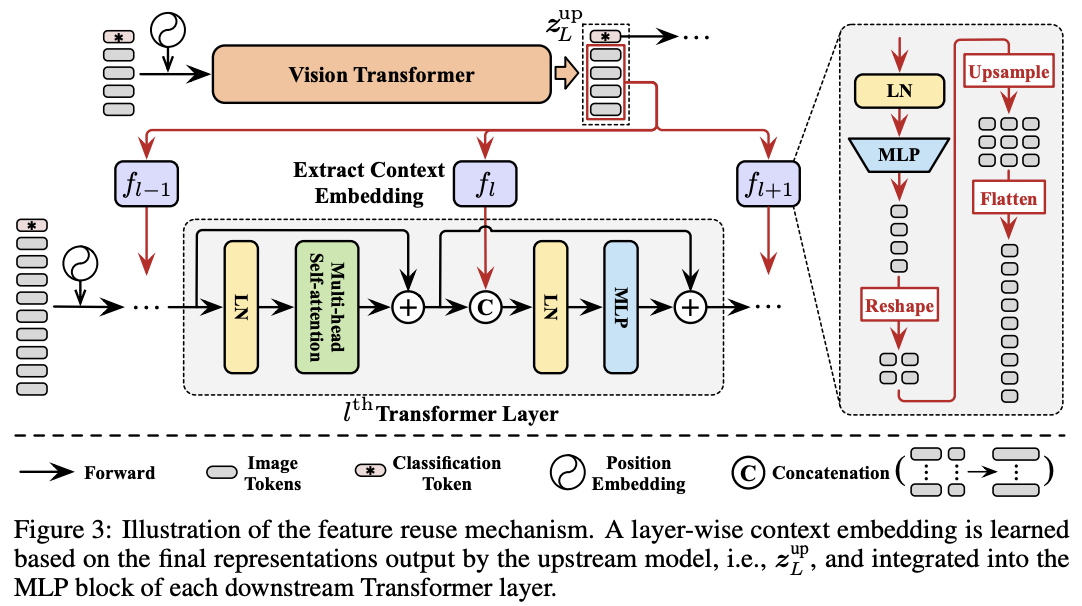
DVT中的所有Transformer都具有相同的目标,即提取关键特征进行准确识别。 因此,下游模型应该在上游模型计算的深度特征的基础上学习才是最高效的,而不是从头开始提取特征。为此,论文提出了图3的特征复用机制,利用上游Transformer最后输出的结果\(z^{up}_L\)来生成下游模型每层的辅助embedding输入\(E_l\):
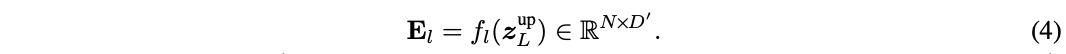
\(f_l:\mathbb{R}^{N\times D}\to \mathbb{R}^{N\times D^{'}}\) 由LN+MLP(\(\mathbb{R}^{D}\to \mathbb{R}^{D^{'}}\))开头,对上游模型输出进行非线性转换。转换后将结果reshape到原始图像中的相应位置,然后上采样并展平来匹配下游模型的token数量。一般情况下,使用较小的\(D^{'}\)以便快速生成\(f_l\)。
之后将\(E_l\)拼接到下游模型对应层的中间特征作为预测的先验知识,也就是将公式3替换为:
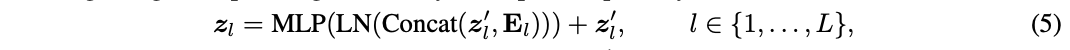
\(E_l\)与中间特征\(z^{'}_l\)拼接,LN 的维度和MLP的第一层从\(D\)增加到\(D+D^{'}\)。 由于\(E_l\)是基于上游输出\(z^{up}_L\)生成的,token数少于\(z^{'}_l\),它实际上为\(z^{'}_l\)中的每个token总结了输入图像的上下文信息。 因此,将\(E_l\)命名为上下文embedding。此外,论文发现不复用分类token对性能有提升,因此在公式5中将其填充零。
公式4和5允许下游模型在每层灵活地利用\(z^{up}_L\)内的信息,从而最小化最终识别损失,这种特征重用方式也可以认为隐式地扩大了模型深度。
Relationship reuse
Vision Transformer的关键在于自注意力模块能够整合整个图像的信息,从而有效地模拟图像中的长距离关系。通常情况下,模型需要在每一层学习一组注意力图来描述token之间的关系。除了上面提到的特征复用,论文认为下游模型还可以复用上游模型产生的自注意力图来进行优化。
定义输入特征\(z_l\),自注意力模块先通过线性变换得到query矩阵\(Q_l\)、key矩阵\(K_l\)和value矩阵\(V_l\):
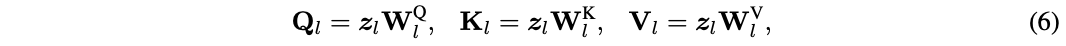
其中,\(W^Q_l\)、\(W^K_l\)和\(W^V_l\)为权重矩阵。然后通过一个带有softmax的缩放点乘矩阵运算得到注意力图,最后根据注意力图来计算所有token的值:
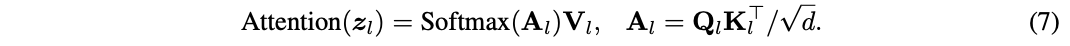
其中,\(d\)是\(Q\)或\(K\)的点积结果维度,\(A_l\in \mathbb{R}^{N\times N}\)为注意力图。为了清楚起见,这省略了多头注意力机制的细节,多头情况下\(A_l\)包含多个注意力图。
对于关系复用,先将上游模型所有层产生的注意力图(即\(A^{up}_l, l\in \{1,\cdots , L\}\))拼接起来:
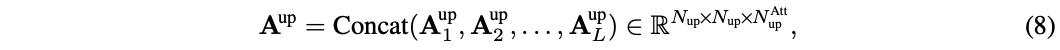
其中,\(N^{up}\)和\(N^{Att}_{up}\) 分别为上游模型中的toekn数和注意力图数,通常\(N^{Att}_{up} = N^H L\),\(N^H\)是多头注意力的head数,\(L\)是层数。
下游的模型同时利用自己的token和\(A^{up}\)来构成注意力图,也就是将公式7替换为:
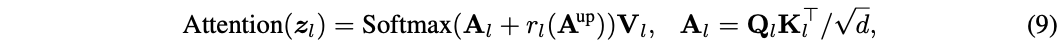
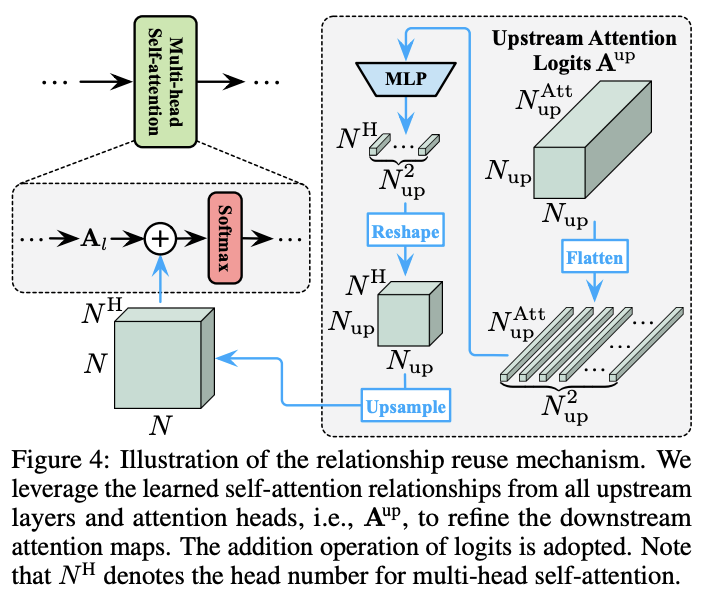
其中\(r_l(\cdot)\)是一个转换网络,整合\(A^{up}\)提供的信息来细化下游注意力图\(A_l\)。\(r_l(\cdot)\)的架构如图5所示,先进行非线性MLP转换,然后上采样匹配下游模型的注意力图大小。
公式9虽然很简单,但很灵活。有两个可以魔改的地方:
- 由于下游模型中的每个自注意力模块可以访问上游模型的所有浅层和深层的注意力头,可以尝试通过可学习的方式来对多层的注意力信息进行加权整合。
- 新生成的注意力图和复用注意力图直接相加,可以尝试通过可学习的方式来对两者加权。
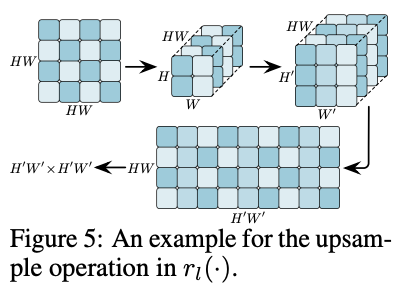
还需要注意的是,\(r_l(\cdot)\)不能直接使用常规上采样操作。如图5所示,假设需要将\(HW\times HW\)(\(H =W = 2\))的注意力图映射上采样到\(H^{'}W^{'}\times H^{'}W^{'}\)(\(H^{'} =W^{'} = 3\))的大小。由于每一行对应单个token与其他\(H\times W\)个token的关系,直接对注意力图上采样会引入混乱的数据。因此,需要先将行reshape为\(H\times W\),然后再缩放到\(H^{'}W^{'}\times H^{'}W^{'}\),最后再展平为\(H^{'}W^{'}\)向量。
Adaptive Infernece
如前面所述,DVT框架逐渐增加测试样本的token数量并执行提前终止,“简单”和“困难”图像可以使用不同的token数来处理,从而提高了整体效率。对于第\(i\)个模型产生的softmax预测\(p_i\),将\(p_i\)的最大项\(max_j p_{ij}\)与阈值\({\mu}_{i}\)进行比较。如果\(max_j p_{ij}\ge {\mu}_{i}\),则停止并采用\(p_i\)作为输出。否则,将使用更多token数更多的下游模型继续预测直到最后一个模型。
阈值\(\{\mu_1, \mu_2, \cdots\}\)需要在验证集上求解。假设一个计算资源有限的批量数据分类场景,DVT需要在给定的计算预算\(B > 0\)内识别一组样本\(D_{val}\)。定义\(Acc(D_{val}, \{\mu_1, \mu_2, \cdots\})\)和\(FLOPs(D_{val}, \{\mu_1, \mu_2, \cdots\})\)为数据集\(D_{val}\)上使用阈值\(\{\mu_1, \mu_2, \cdots\}\)时的准确度和计算成本,最优阈值可以通过求解以下优化问题得到:
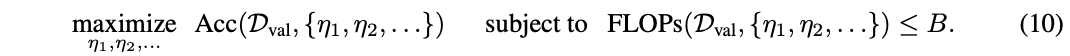
由于公式10是不可微的,论文使用遗传算法解决了这个问题。
Experiment
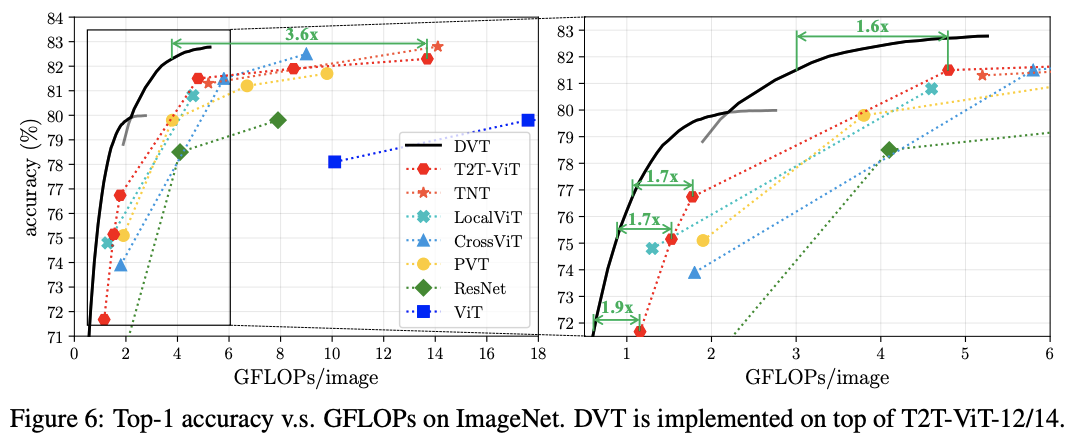
ImageNet上的性能对比。
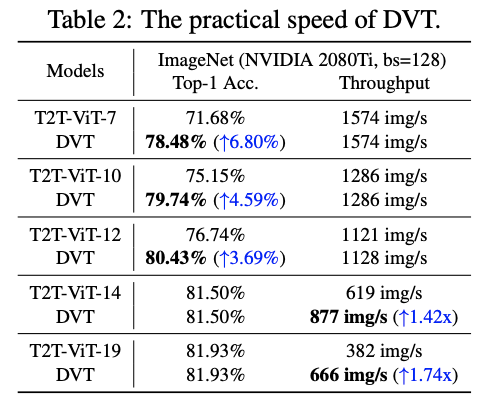
推理性能对比。

CIFAR上对比DVT在不同模型规模的性能。
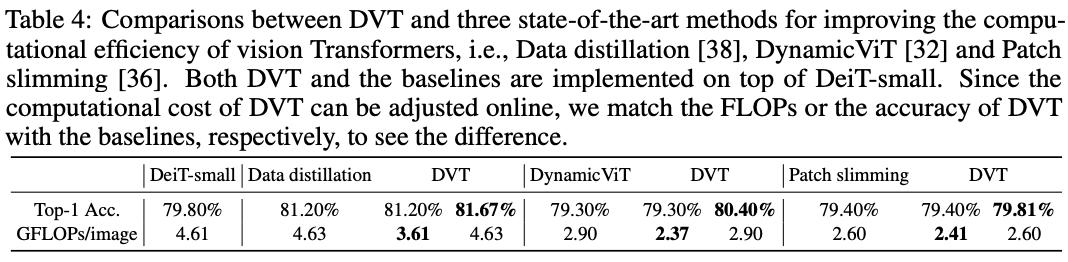
在ImageNet上与SOTA vision transformer提升方法的性能对比。
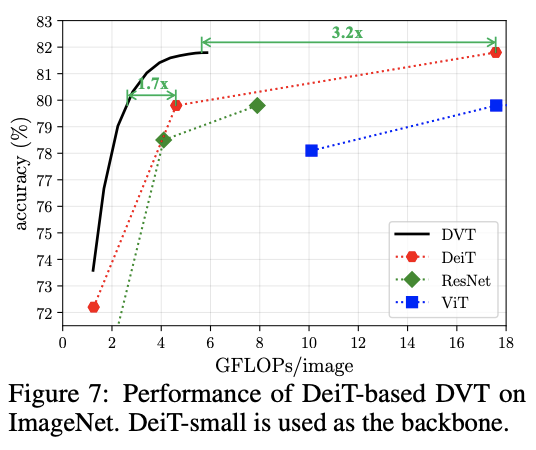
基于DeiT的DVT性能对比。
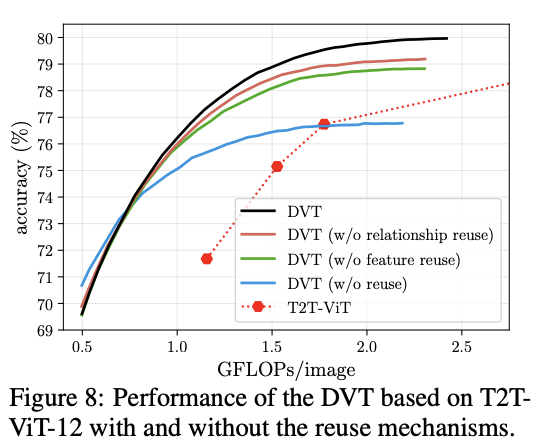
复用机制的对比实验。
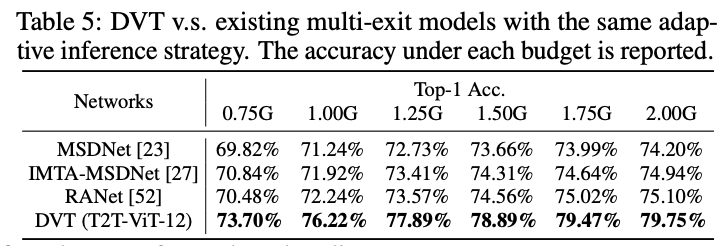
与类似的提前退出方法的性能对比。
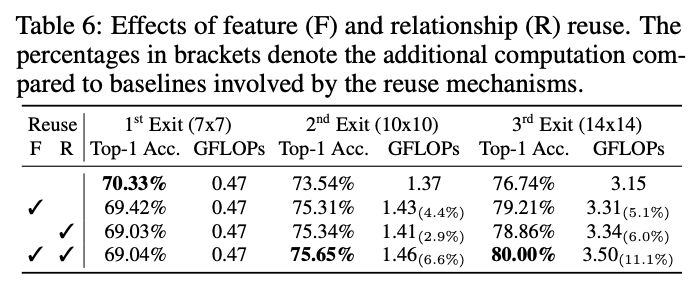
复用机制提升的性能与计算量。
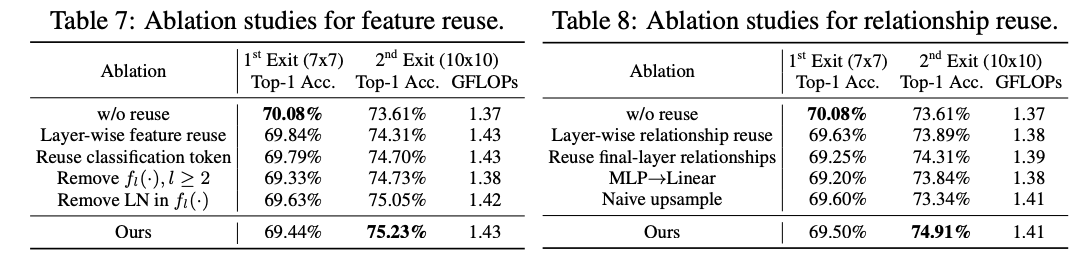
复用机制实现细节的对比实验。

难易样本的例子以及数量分布。

不同终止标准的性能对比。
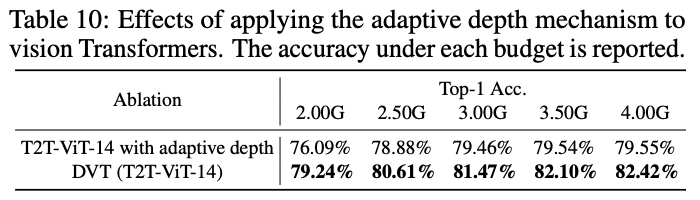
与自适应深度方法进行性能对比,自适应方法是在模型的不同位置插入分类器。
Conclusion
论文主要处理Vision Transformer中的性能问题,采用推理速度不同的级联模型进行速度优化,搭配层级间的特征复用和自注意力关系复用来提升准确率。从实验结果来看,性能提升不错。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

DVT:华为提出动态级联Vision Transformer,性能杠杠的 | NeurIPS 2021的更多相关文章
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...
- Vicinity Vision Transformer概述
0.前言 相关资料: arxiv github 论文解读 论文基本信息: 发表时间:arxiv2022(2022.6.21) 1.针对的问题 视觉transformer计算复杂度和内存占用都是二次的, ...
- ICCV2021 | 渐进采样式Vision Transformer
前言 ViT通过简单地将图像分割成固定长度的tokens,并使用transformer来学习这些tokens之间的关系.tokens化可能会破坏对象结构,将网格分配给背景等不感兴趣的区域,并引 ...
- 【手搓模型】亲手实现 Vision Transformer
前言 博客主页:睡晚不猿序程 首发时间:2023.3.17,首发于博客园 最近更新时间:2023.3.17 本文由 睡晚不猿序程 原创 作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我, ...
- JS动态级联菜单
JS动态级联菜单是前端常用的一个功能,特此抽时间研究了下,附上代码 <html> <head> <meta charset="utf-8" /> ...
- Ajax+json实现菜单动态级联
1:jsp //级联ajax处理函数 function areaChange(){ var areano=document.all("areaNo").value; v ...
- 中小企业上云首选,华为云全新云服务器S6性能评测分析
转: 中小企业上云首选,华为云全新云服务器S6性能评测分析 [小宅按]今天,华为云全新弹性云服务器ECS通用计算型云服务器S6(以下简称为"华为云S6云服务器")正式发布,至顶网云 ...
- 关于C#调用非托管动态库方式的性能疑问
最近的项目中,因为一些原因,需要C#调用非托管(这里为C++)的动态库.网上喜闻乐见的方式是采用静态(DllImport)方式进行调用.偶然在园子里看到可以用动态(LoadLibrary,GetPro ...
- Javascript动态生成表格的性能调优
vision 0.8 [耗时672ms]终极优化 将字符串作为数组对象的方式是目前效率最高,性能最优的方式. <script> var t1 = new Date(); < ...
随机推荐
- CMS垃圾收集器小实验之CMSInitiatingOccupancyFraction参数
CMS垃圾收集器小实验之CMSInitiatingOccupancyFraction参数 背景 测试CMSInitiatingOccupancyFraction参数,测试结果和我的预期不符,所以花了一 ...
- WEB服务与NGINX(21)- nginx 的fastcgi反向代理功能
目录 1. NGINX实现fastcgi反向代理 1.1 fastcgi概述 1.2 nginx实现fastcgi相关参数 1.3 nginx与php-fpm部署在一台服务器 1.3.1 php服务器 ...
- 批量删除WordPress文章和页面的数据库命令和从后台直接删除
批量删除wordpress的方法有两种:1.从wp后台可以调整展示:最多999条 2.选择"Bulk"--"Apply" 通过批量删除wordpress文章和页 ...
- 九、.net core(.NET 6)添加通用的Redis功能
.net core 编写通用的Redis功能 在 Package项目里面,添加包:StackExchange.Redis: 在Common工具文件夹下,新建 Wsk.Core.Redis类库项目,并 ...
- Vue3 项目
创建 Vue3 项目的步骤如下: 安装 Node.js Vue3 需要依赖 Node.js 环境,因此需要先安装 Node.js.可以从官网下载 Node.js 的安装包并安装,也可以使用包管理器安装 ...
- 官宣:Splashtop与JumpCloud合作 提供单次登录远程访问解决方案
号外! 官宣:Splashtop与JumpCloud合作 提供单次登录远程访问解决方案! 打开百度APP,查看更多高清图片 以下是一本正经的官宣新闻,我是没感情的翻译机器人,嘻嘻. Bad Robot ...
- 基于FPGA的数字钟设计---第三版
欢迎各位朋友关注"郝旭帅电子设计团队",本篇为各位朋友介绍基于FPGA的数字钟设计---第三版. 功能说明: 1. 在数码管上面显示时分秒(共计六个数码管,前两个显示小时:中间两个 ...
- docker应用基础
docker相关 镜像 镜像仓库使用的Docker默认的Docker Hub. 搜索仓库的镜像 docker search 默认按评分排序,offical [ok] 表示是官方镜像 $ docker ...
- Authentication failed. Some common reasons include:
问题无论是pull.clone还是push都报错 fatal: Out of memory, malloc failed (tried to allocate 301989888 bytes)fata ...
- WPF DataGrid使用 自动显示行号、全选、三级联动、拖拽
1.DataGrid的使用自动显示行号(修复删除行时行号显示不正确) dgTool.LoadingRow += new EventHandler<DataGridRowEventArgs&g ...