Python开发简单爬虫(二)---爬取百度百科页面数据
一、开发爬虫的步骤
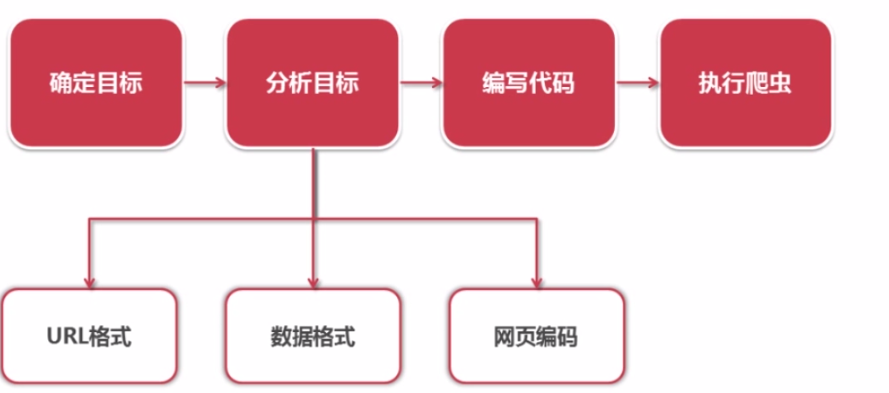
1.确定目标抓取策略:
打开目标页面,通过右键审查元素确定网页的url格式、数据格式、和网页编码形式。
①先看url的格式, F12观察一下链接的形式;
② 再看目标文本信息的标签格式, 比如文本数据为div class="xxx",
③ 容易看到编码为utf-8
2.分析目标
目标: 百度百科python词条
入口页: http://baike.baidu.com/item/Python
词条页面url格式:/item/****
数据格式:
标题: <dd class="lemmaWgt-lemmaTitle-title"><h1>****</h1></dd>
简介: <div class = "lemma-summary">****</div>
页面编码: utf-8
3.实例代码
爬取百度百科Python词条以及相关的1000个页面数据
Python开发简单爬虫(二)---爬取百度百科页面数据的更多相关文章
- R语言爬虫:爬取百度百科词条
抓取目标:抓取花儿与少年的百度百科中成员信息 url <- "http://baike.baidu.com/item/%E8%8A%B1%E5%84%BF%E4%B8%8E%E5%B0 ...
- 慕课爬虫实战 爬取百度百科Python词条相关1000个页面数据
http://www.imooc.com/learn/563 spider_main.py #!/usr/bin/python # coding=utf-8 #from baike_spider im ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
随机推荐
- (二十六)svn的问题二
上周五请了一天假,电脑放在公司没有带回来,三天的时间都没有看代码,使得我电脑上的东西与svn上相差了太多,因为不一样,所以就要更新同步,因为要更新同步的东西多,便又出了一些问题,也因此对svn有了更进 ...
- TensorFlow MNIST初级学习
MNIST MNIST 是一个入门级计算机视觉数据集,包含了很多手写数字图片,如图所示: 数据集中包含了图片和对应的标注,在 TensorFlow 中提供了这个数据集,我们可以用如下方法进行导入: f ...
- Log4j各级别日志重复打印
使用filter进行日志过滤 这个其实是Log4j自带的方案,也是推荐方案,不知道为什么网上的资料却很少提到这点.把log4j.properties配置文件修改成如下: #root日志 log4j.r ...
- 利用popstate事件和window下的history对象处理浏览器跳转问题
引子 之前,偶尔在项目中用过history接口做返回上一页功能,当时是用的history.go(-1),前几天面试中遇到一个控制浏览器跳转的问题时有点懵,特意查了文档记录一下,并且列出一些目前能想到的 ...
- manacher模板(manacher)
洛谷题目传送门 写完有一段时间了,发现板子忘记存在了这里...... 算法简述 一种字符串算法,\(O(n)\)高效求出以每个字符为对称中心的最长回文串长度. 然后,就可以进一步求出全串中最长回文串的 ...
- Docker_快速部署jenkins
开门见山,如何在利用docker快速部署jenkins服务?下面详解 1:docker的基本按照与部署,前文已经详述,这里不多说. 2:pull一个jenkins镜像 docker pull jenk ...
- 数据结构之队列c代码实现
一学期的数据结构,总不能毫无收获吧,因为书上的很多代码并不能实现,我一个编程小白可怎么过呢,难得假期有时间,于是我寻求度娘,从四面八方找了些可以编译通过的源码,这一次是队列,后面我还会逐渐补充,如果有 ...
- html、css简述面试题
hTML, HTTP,web综合问题 1.前端需要注意哪些SEO 合理的title.description.keywords:搜索对着三项的权重逐个减小,title值强调重点即可,重要关键词出现不要超 ...
- oracle中增加pga和sga
修改oracle数据库SGA和PGA大小 个人原创,允许转载,请注明出处,作者,否则追究法律责任. SGA的大小:一般物理内存20%用作操作系统保留,其他80%用于数据库.SGA普通数据库可以分配40 ...
- Geth 控制台使用及 Web3.js 使用实战
在开发以太坊去中心化应用,免不了和以太坊进行交互,那就离不开Web3.Geth 控制台(REPL)实现了所有的web3 API及Admin API,使用好 Geth 就是必修课.结合Geth命令用法阅 ...