Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一、修改hosts文件
在主节点,就是第一台主机的命令行下;
vim /etc/hosts
我的是三台云主机:
在原文件的基础上加上;
ip1 master worker0 namenode
ip2 worker1 datanode1
ip3 worker2 datanode2
其中的ipN代表一个可用的集群IP,ip1为master的主节点,ip2和iip3为从节点。
二、ssh互信(免密码登录)
注意我这里配置的是root用户,所以以下的家目录是/root
如果你配置的是用户是xxxx,那么家目录应该是/home/xxxxx/
#在主节点执行下面的命令:
ssh-keygen -t rsa -P '' #一路回车直到生成公钥
scp /root/.ssh/id_rsa.pub root@worker1:/root/.ssh/id_rsa.pub.master #从master节点拷贝id_rsa.pub到worker主机上,并且改名为id_rsa.pub.master
scp /root/.ssh/id_rsa.pub root@worker1:/root/.ssh/id_rsa.pub.master #同上,以后使用workerN代表worker1和worker2.
scp /etc/hosts root@workerN:/etc/hosts #统一hosts文件,让几个主机能通过host名字来识别彼此
#在对应的主机下执行如下命令:
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys #master主机
cat /root/.ssh/id_rsa.pub.master >> /root/.ssh/authorized_keys #workerN主机
这样master主机就可以无密码登录到其他主机,这样子在运行master上的启动脚本时和使用scp命令时候,就可以不用输入密码了。
三、安装基础环境(JAVA和SCALA环境)
1.Java1.8环境搭建:
配置master的java环境
#下载jdk1.8的rpm包
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u112-b15/jdk-8u112-linux-x64.rpm
rpm -ivh jdk-8u112-linux-x64.rpm
#增加JAVA_HOME
vim etc/profile
#增加如下行:
#Java home
export JAVA_HOME=/usr/java/jdk1..0_112/ #刷新配置:
source /etc/profile #当然reboot也是可以的
配置workerN主机的java环境
#使用scp命令进行拷贝
scp jdk-8u112-linux-x64.rpm root@workerN:/root
#其他的步骤如master节点配置一样
2.Scala2.12.2环境搭建:
Master节点:
#下载scala安装包:
wget -O "scala-2.12.2.rpm" "https://downloads.lightbend.com/scala/2.12.1/scala-2.12.2.rpm"
#安装rpm包:
rpm -ivh scala-2.12..rpm
#增加SCALA_HOME
vim /etc/profile
#增加如下内容;
#Scala Home
export SCALA_HOME=/usr/share/scala #刷新配置
source /etc/profile
WorkerN节点;
#使用scp命令进行拷贝
scp scala-2.12..rpm root@workerN:/root #其他的步骤如master节点配置一样
四、Hadoop2.7.3完全分布式搭建
MASTER节点:
1.下载二进制包:
wget http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
2.解压并移动至相应目录
我的习惯是将软件放置/opt目录下:
tar -xvf hadoop-2.7..tar.gz
mv hadoop-2.7. /opt
3.修改相应的配置文件:
(1)/etc/profile:
增加如下内容:
#hadoop enviroment
export HADOOP_HOME=/opt/hadoop-2.7./
export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
(2)$HADOOP_HOME/etc/hadoop/hadoop-env.sh
修改JAVA_HOME 如下:
export JAVA_HOME=/usr/java/jdk1..0_112/
(3)$HADOOP_HOME/etc/hadoop/slaves
worker1
worker2
(4)$HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value></value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7./tmp</value>
</property>
</configuration>
(5)$HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.7./hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7./hdfs/data</value>
</property>
</configuration>
(6)$HADOOP_HOME/etc/hadoop/mapred-site.xml
复制template,生成xml:
cp mapred-site.xml.template mapred-site.xml
内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:</value>
</property>
</configuration>
(7)$HADOOP_HOME/etc/hadoop/yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:</value>
</property>
至此master节点的hadoop搭建完毕
再启动之前我们需要
格式化一下namenode
hadoop namenode -format
WorkerN节点:
(1)复制master节点的hadoop文件夹到worker上:
scp -r /opt/hadoop-2.7. root@wokerN:/opt #注意这里的N要改为1或者2
(2)修改/etc/profile:
过程如master一样
五、Spark2.1.0完全分布式环境搭建:
MASTER节点:
1.下载文件:
wget -O "spark-2.1.0-bin-hadoop2.7.tgz" "http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.7.tgz"
2.解压并移动至相应的文件夹;
tar -xvf spark-2.1.-bin-hadoop2..tgz
mv spark-2.1.-bin-hadoop2. /opt
3.修改相应的配置文件:
(1)/etc/profie
#Spark enviroment
export SPARK_HOME=/opt/spark-2.1.-bin-hadoop2./
export PATH="$SPARK_HOME/bin:$PATH"
(2)$SPARK_HOME/conf/spark-env.sh
cp spark-env.sh.template spark-env.sh
#配置内容如下:
export SCALA_HOME=/usr/share/scala
export JAVA_HOME=/usr/java/jdk1..0_112/
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/hadoop-2.7./etc/hadoop
(3)$SPARK_HOME/conf/slaves
cp slaves.template slaves
配置内容如下
master
worker1
worker2
WorkerN节点:
将配置好的spark文件复制到workerN节点
scp spark-2.1.-bin-hadoop2. root@workerN:/opt
修改/etc/profile,增加spark相关的配置,如MASTER节点一样
六、启动集群的脚本
启动集群脚本start-cluster.sh如下:
#!/bin/bash
echo -e "\033[31m ========Start The Cluster======== \033[0m"
echo -e "\033[31m Starting Hadoop Now !!! \033[0m"
/opt/hadoop-2.7./sbin/start-all.sh
echo -e "\033[31m Starting Spark Now !!! \033[0m"
/opt/spark-2.1.-bin-hadoop2./sbin/start-all.sh
echo -e "\033[31m The Result Of The Command \"jps\" : \033[0m"
jps
echo -e "\033[31m ========END======== \033[0m"
截图如下:
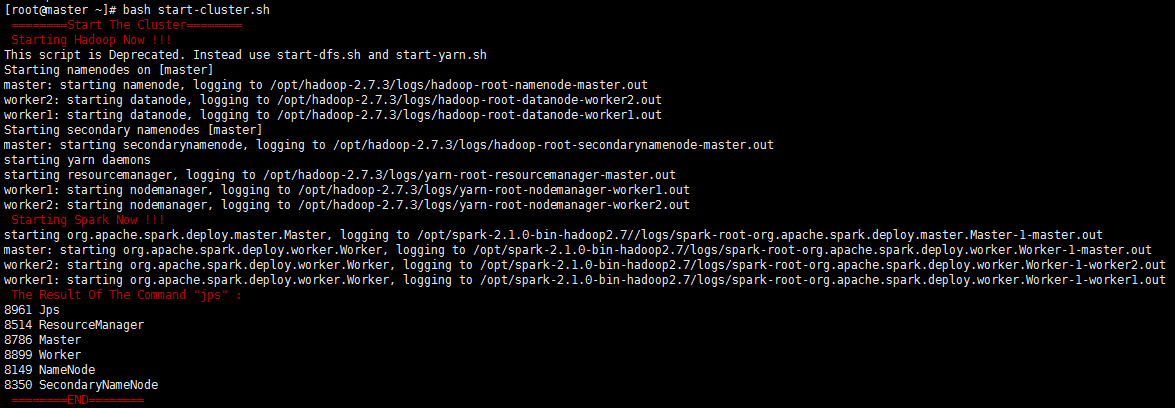
关闭集群脚本stop-cluser.sh如下:
#!/bin/bash
echo -e "\033[31m ===== Stoping The Cluster ====== \033[0m"
echo -e "\033[31m Stoping Spark Now !!! \033[0m"
/opt/spark-2.1.-bin-hadoop2./sbin/stop-all.sh
echo -e "\033[31m Stopting Hadoop Now !!! \033[0m"
/opt/hadoop-2.7./sbin/stop-all.sh
echo -e "\033[31m The Result Of The Command \"jps\" : \033[0m"
jps
echo -e "\033[31m ======END======== \033[0m"
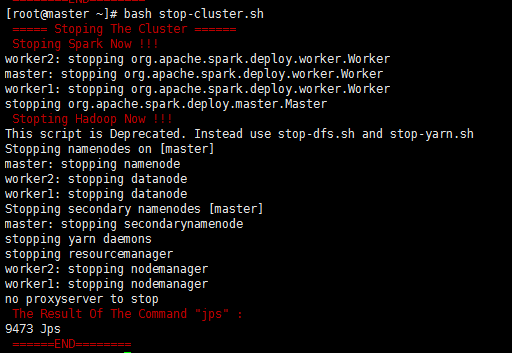
截图如下:
七、测试一下集群:
这里我都用最简单最常用的Wordcount来测试好了!
1.测试hadoop
测试的源文件的内容为:
Hello hadoop
hello spark
hello bigdata
然后执行下列命令:
hadoop fs -mkdir -p /Hadoop/Input
hadoop fs -put wordcount.txt /Hadoop/Input
hadoop jar /opt/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /Hadoop/Input /Hadoop/Output
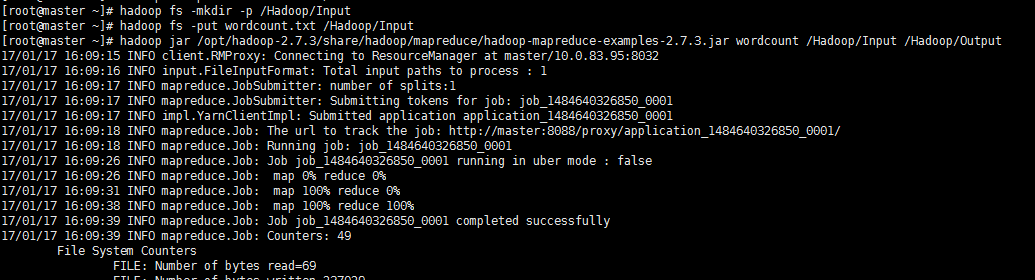
等待mapreduce执行完毕后,查看结果;
hadoop fs -cat /Hadoop/Output/*
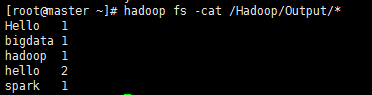
hadoop集群搭建成功!
2.测试spark
为了避免麻烦这里我们使用spark-shell,做一个简单的worcount的测试
用于在测试hadoop的时候我们已经在hdfs上存储了测试的源文件,下面就是直接拿来用就好了!
spark-shell
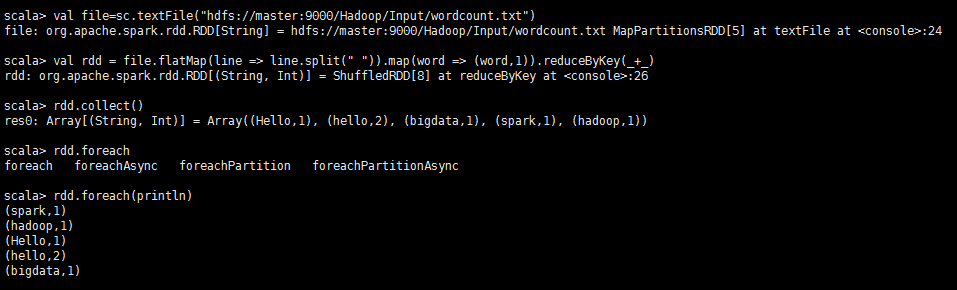
val file=sc.textFile("hdfs://master:9000/Hadoop/Input/wordcount.txt")
val rdd = file.flatMap(line => line.split(" ")).map(word => (word,)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)
退出的话使用如下命令:
:quit
至此我们这篇文章就结束了。
Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程的更多相关文章
- Spark2.4.0伪分布式环境搭建
一.搭建环境的前提条件 环境:ubuntu-16.04 hadoop-2.6.0 jdk1.8.0_161. spark-2.4.0-bin-hadoop2.6.这里的环境不一定需要和我一样,基本版 ...
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
- Hadoop2.7.5+Hbase1.4.0完全分布式
Hadoop2.7.5+Hbase1.4.0完全分布式一.在介绍完全分布式之前先给初学者推荐两本书:<Hbase权威指南>偏理论<Hbase实战>实战多一些 二.在安装完全分布 ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装 一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh ...
- 在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境
近几年大数据越来越火热.由于工作需要以及个人兴趣,最近开始学习大数据相关技术.学习过程中的一些经验教训希望能通过博文沉淀下来,与网友分享讨论,作为个人备忘. 第一篇,在win7虚拟机下搭建hadoop ...
- Hadoop-2.4.1完全分布式环境搭建
Hadoop-2.4.1完全分布式环境搭建 Hadoop-2.4.1完全分布式环境搭建 一.配置步骤如下: 主机环境搭建,这里是使用了5台虚拟机,在ubuntu 13系统上进行搭建hadoop ...
- hadoop学习(三)----hadoop2.x完全分布式环境搭建
今天我们来完成hadoop2.x的完全分布式环境搭建,话说学习本来是一件很快乐的事情,可是一到了搭环境就怎么都让人快乐不起来啊,搭环境的时间比学习的时间还多.都是泪.话不多说,走起. 1 准备工作 开 ...
随机推荐
- 解决Sublime Text 3在GBK编码下的中文乱码问题听语音
Sublime Text 3是我最喜欢的代码编辑器,没有之一,因为她的性感高亮代码配色,更因为它的小巧,但是它默认不支持GBK的编码格式,因此打开GBK的代码文件,如果里面有中文的话,就会乱码 工具/ ...
- 2017-06-27(useradd usermod userdel 禁止普通用户登录)
useradd useradd -g 组名 用户名 (添加新用户,并将其添加到指定的主用户组) useradd -g 组名 -G 附属组名 用户名 (添加新用户,并将其添加至指定主用 ...
- .net Core学习笔记2 实现列表的条件筛选,排序,分页
打开vs,完善上次"简单粗暴"的项目 发现上次的实体类的导航属性有点问题,这是更改后的 namespace ProductMvc.Models { public class Pro ...
- [Qt Quick] qmlscene工具的使用
qmlscene是Qt 5提供的一个查看qml文件效果的工具.特点是不需要编译应用程序. qmlscene = qml + scene (场景) qmlscene.exe位于Qt的安装目录下 (类似/ ...
- js实现最短时间走完不同速度的路程
题目: 现在有一条公路,起点是0公里,终点是100公里.这条公路被划分为N段,每一段有不同的限速.现在他们从A公里处开始,到B公里处结束.请帮他们计算在不超过限速的情况下,最少需要多少时间完成这段路程 ...
- 一个ios的各种组件、代码分类,供参考
http://github.ibireme.com/github/list/ios/#
- css 块状元素与行内元素(内联元素)的理解
块状元素: 它一般是其他元素的容器元素,可以容纳块状元素和行内元素,它默认是不会和其他元素同一行的,即相当于两个块状元素写一起是垂直布局的.最常用的是div和p 行内元素: 行内元素又称内联元素,它只 ...
- Elasticsearch 全教程--入门
1.1 初识 Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎,可以说 Lucene 是当今最先进,最高效的全功能开源搜索引擎框架. 但是 L ...
- js发展历史
1992年Nombas开发和醋C-minus-minus(c--),的嵌入式脚本语言,最初是绑定在Cenvi软件中,后将其改名scriptEase(客户端执行的语言) Netscape 接受Nomba ...
- python selenium 鼠标悬停
#鼠标悬停 chain = ActionChains(driver) implement = driver.find_element_by_link_text() chain.move_to_elem ...