spark yarn cluster模式下任务提交和计算流程分析
spark可以运行在standalone,yarn,mesos等多种模式下,当前我们用的最普遍的是yarn模式,在yarn模式下又分为client和cluster。本文接下来将分析yarn cluster下任务提交的过程。也就是回答,在yarn cluster模式下,任务是怎么提交的问题。在yarn cluster模式下,spark任务提交涉及四个角色(client, application, driver以及executor)之间的交互。接下来,将详细分析这四个角色在任务提交过程中都做了那些事。
1,client流程
Step 1:我们知道:在我们写完任务准备向集群提交spark任务时,一般是调用bin下的spark-submit脚本进行任务的提交。在完成一些环境变量和参数的准备后,最终调用spark代码库中的SparkSubmit类。

Step 2:在SparkSubmit的main函数中,通过submit,runMain然后通过YarnClusterApplication启动org.apache.spark.deploy.yarn.Client.
Step 3:在Client中,通过main,run,然后在submitApplication中,利用yarnClient向ResourceManager提交新应用以启动ApplicationMaster,其中在yarn cluster模式下启动ApplicationMaster的类是
org.apache.spark.deploy.yarn.ApplicationMaster。 至此,client完成所有的工作。
2,ApplicationMaster流程
Step1:yarn分配container运行ApplicationMaster。通过main,run,runDriver,调用startUserApplication,新建线程,运行在spark-submit --class参数指定的应用类用户代码。
Step2:ApplicationMaster等待driver完成sparkContext的初始化后,获取driver的一个ref。调用registerAM函数,利用YarnRMClient向yarn申请资源运行executor。一旦获取到container资源,在yarnAllocator中,
launcherPool线程池会将container,driver等相关信息封装成ExecutorRunnable对象,通过ExecutorRunnable启动新的container以运行executor。在次过程中,指定启动executor的类是
org.apache.spark.executor.CoarseGrainedExecutorBackend。
3,Driver流程
在ApplicationMaster的步骤1中,会新建线程运行用户端代码,并且在完成sparkcontext的初始化,其中包括dagScheduler完成job stage的切分,每个stage的任务转成化一系列的task,封装成taskset。交由taskScheduler去调用。由于这个过程比较复杂,而且非常的重要,准备稍后会单独对这个部分进行详细讲解。
4,Executor流程
在ApplicationMaster的步骤2中提到,新的container将会运行executor。在executor启动以后,会向driver发送RegisterExecutor消息告诉driver注册当前运行的executor。在driver端的CoarseGrainedSchedulerBackend中,可以看到对该消息的处理过程。在driver段感知到该消息后,driver将向executor发送RegisteredExecutor消息。executor和driver更多的细节,在稍后spark任务计算解析中,会将进行更详细的描述。
至此,client在完成使命后退出。其他三个部分也已启动起来。接下来将以spark example中的sparkPi例子来看看平常我们写的spark任务是怎么计算的。
首先把sparkPi中的代码贴出来:
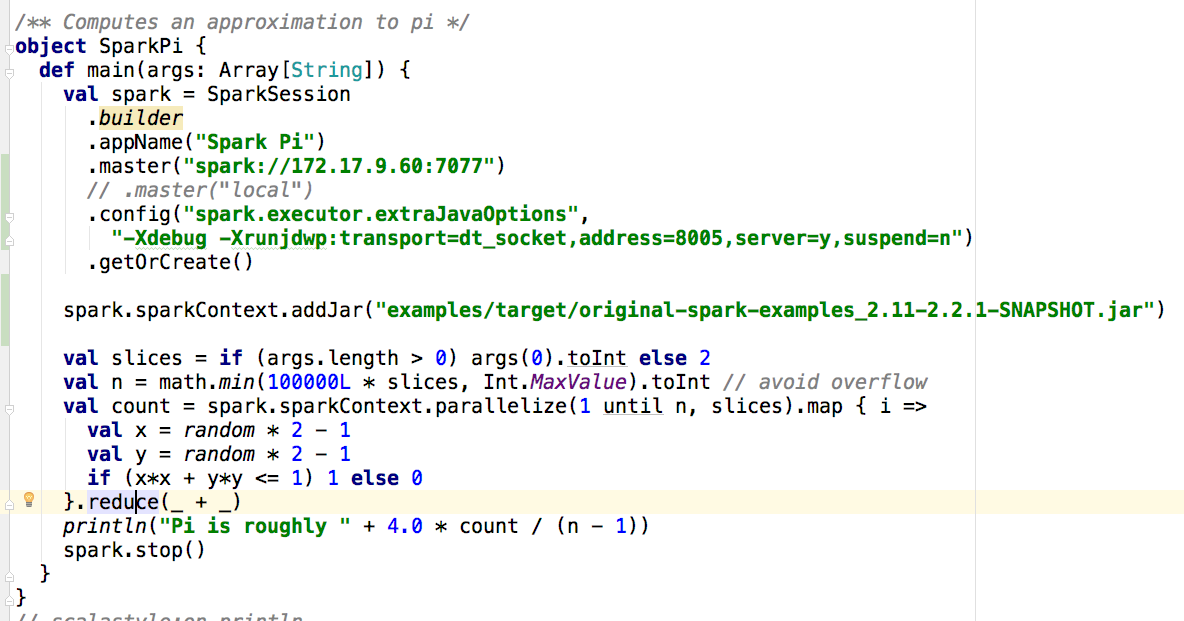
问题1:何时开始运行用户的中main函数?
在前文中 ApplicationMaster流程中第一步提到:yarn分配container运行ApplicationMaster。通过main,run,runDriver,调用startUserApplication,新建线程,运行在spark-submit --class参数指定的应用类用户代码。也就是说,在这一步将运行用户写入的代码。
问题2:上述代码具体都做了些啥?
1,在SparkSession...getOrCreate函数中主要做的事情是完成sparkContext的初始化,这其中主要包括DAGScheduler,TaskSchedule的初始化等。(注:在调试过程中使用的standalone模式,并且加入extraJavaOption主要是为了便于调试executor的代码)。
2,上述代码的核心是sparkContext.parallelize(....).map(....).reduce。在parallelize函数中将新建ParallelCollectionRDD。在map中将新建MapPartitionsRDD。最后reduce是一个action(一个action对应一个Job),触发实际的计算。
3,在reduce函数中,通过调用sc.runJob->dagScheduler.runJob→submitJob提交JobSubmitted事件到DAGScheduler自己。然后调用handleJobSubmitted来处理Job提交。在handleJobSubmitted函数中,将创建ResultStage,然后根据shuffle将Job划分为不同的stage。在本例中,由于没有shuffle,将只有一个stage。最终通过submitMissingTasks将stage中的task封装成taskset,交由taskschuduler(taskScheduler.submitTasks)进行task级别的调度。
4,在TaskSchdulerImpl的submitTasks中,可以看到taskset会被进一步封装成TasksetManager,加入到schedulableBuilder中(默认使用FIFO队列进行调度)。然后driver向自己发送ReviveOffers消息。driver接收到该信息后,如果发现有空闲的executor,将该Task序列后,发送LaunchTask消息给executor。让executor去执行。
5,executor处理LaunchTask消息的代码如下:

launchTask会将task信息TaskRunner,启用线程池运行。
6,在TaskRunner的run方法中,将运行
val res = task.run(
taskAttemptId = taskId,
attemptNumber = taskDescription.attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
然后调用runTask进行运行,有两种类型的Task(ShuffleMapTask,ResultTask),本例中将运行ResultTask中的runTask方法,然后在该方法中,调用用户传入的函数代码。
7,在TaskRunner的run方法中,在完成计算后,将调用execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult),该函数将向driver发送信息,告诉改Task已完成。
8,在driver端,如果任务正常结束,将调用taskResultGetter.enqueueSuccessfulTask。在该函数中,接着调用handleSuccessfulTask,最终DAGScheduler将向自己发送CompletionEvent事件,然后使用handleTaskCompletion来处理。如果任务正常结束,将通过
job.listener.taskSucceeded通知JobWaiter,JobWaiter完成任务结果的合并。在所有的JobWaiter中的Task都完成后,任务退出。
spark yarn cluster模式下任务提交和计算流程分析的更多相关文章
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
- Apache Spark源码走读之19 -- standalone cluster模式下资源的申请与释放
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文主要讲述在standalone cluster部署模式下,Spark Application在整个运行期间,资源(主要是cpu core和内存)的申请与 ...
- [Spark内核] 第31课:Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本課主題 Master 资源调度的源码鉴赏 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... 资源调度管理 任务调度与资源是通过 DAGScheduler.Ta ...
- DEBUG模式下, 内存中的变量地址分析
测试函数的模板实现 /// @file my_template.h /// @brief 测试数据类型用的模板实现 #ifndef MY_TEMPLATE_H_2016_0123_1226 #defi ...
- Android平台dalvik模式下java Hook框架ddi的分析(2)--dex文件的注入和调用
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/77942585 前面的博客<Android平台dalvik模式下java Ho ...
- Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本课主题 Master 资源调度的源码鉴赏 资源调度管理 任务调度与资源是通过 DAGScheduler.TaskScheduler.SchedulerBackend 等进行的作业调度 资源调度是指应 ...
- 【原】Spark不同运行模式下资源分配源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Task的提交源码解读 http://www.cnblogs.com/yourarebest/p/5423906.html Sch ...
- 【转】log4js在PM2的cluster模式下大坑
请直接查看原文:https://blog.yourtion.com/fix-log4js-with-pm2-not-work.html 之前一直使用 debug 还有 console.log 去打日志 ...
- 解决Redis Cluster模式下的排序问题
通常的redis排序我们可以这么做: 比如按商品价格排序:sort goods_id_set by p_*_price 这样在非集群模式下是没问题的,但如果在集群模式下,就会报错: 说是在集群模式下不 ...
随机推荐
- POJ 题目1204 Word Puzzles(AC自己主动机,多个方向查询)
Word Puzzles Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 10244 Accepted: 3864 S ...
- Sql数据库查询语言
1.概述 Sql是一种面向数据库的结构化查询语言.是符合美国国家标准化组织ANSI的一种计算机标准语言. Sql具对数据库的操作有:增删改查.创建数据库.创建表.创建存储过程.创建视图等 RDBMS关 ...
- 两个喜欢的"新"C#语法
现在C#比较新的语法,我都十分喜欢. 比如属性可设默认值: public string Name { get; set; } = "张三"; 还有一个就是拼接字符串. 以往,通常都 ...
- Hadoop0.20.203.0在关机重启后,namenode启动报错(/dfs/name is in an inconsistent state)
Hadoop0.20.203.0在关机重启后,namenode启动报错: 2011-10-21 05:22:20,504 INFO org.apache.hadoop.hdfs.server.comm ...
- Hadoop 解除 “Name node is in safe mode”
运行Hadoop程序时,有时候会报以下错误: org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. N ...
- shutdown的几种方式,shutdown abort的一些弊端有哪些
1.shutdown normal 正常方式关闭数据库. 2.shutdown immediate 立即方式关闭数据库. 在SVRMGRL中执行shutdown immedia ...
- POJ1984 Navigation Nightmare —— 种类并查集
题目链接:http://poj.org/problem?id=1984 Navigation Nightmare Time Limit: 2000MS Memory Limit: 30000K T ...
- get the default proxy by Powershell
https://stackoverflow.com/questions/571429/powershell-web-requests-and-proxies $proxyAddr = (get-ite ...
- plink 与 ssh 远程登录问题
plink 是一种 putty-tools,ubuntu 环境下,如果没有安装 plink,可通过如下方法进行安装: $ echo y | sudo apt-get install plink 1. ...
- BZOJ_1067_[SCOI2007]降雨量_ST表
BZOJ_1067_[SCOI2007]降雨量_ST表 Description 我们常常会说这样的话:“X年是自Y年以来降雨量最多的”.它的含义是X年的降雨量不超过Y年,且对于任意 Y<Z< ...