[scrapy]Item Loders
Items
Items就是结构化数据的模块,相当于字典,比如定义一个{"title":"","author":""},items_loders就是从网页中提取title和author字段填充到items里,比如{"title":"初学scrapy","author":"Alex"},然后items把结构化的数据传给pipeline,pipeline可以把数据插入进MySQL里.
实例
items.py
import scrapy class JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()
jobbole.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from scrapy.loader import ItemLoader from urllib import parse
import re
import datetime
from ArticleSpider.items import JobBoleArticleItem from utils.common import get_md5 class JpbboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] #先下载http://blog.jobbole.com/all-posts/这个页面,然后传给parse解析 def parse(self, response): #1.start_urls下载页面http://blog.jobbole.com/all-posts/,然后交给parse解析,parse里的post_urls获取这个页面的每个文章的url,Request下载每个文章的页面,然后callback=parse_detail,交给parse_detao解析
#2.等post_urls这个循环执行完,说明这一个的每个文章都已经解析完了, 就执行next_url,next_url获取下一页的url,然后Request下载,callback=self.parse解析,parse从头开始,先post_urls获取第二页的每个文章的url,然后循环每个文章的url,交给parse_detail解析 #获取http://blog.jobbole.com/all-posts/中所有的文章url,并交给Request去下载,然后callback=parse_detail,交给parse_detail解析
post_nodes = response.css("#archive .floated-thumb .post-thumb a")
for post_node in post_nodes:
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
yield Request(url=parse.urljoin(response.url,post_url),meta={"front_image_url":image_url},callback=self.parse_detail) #获取下一页的url地址,交给Request下载,然后交给parse解析
next_url = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_url:
yield Request(url=next_url,callback=self.parse) def parse_detail(self,response): article_item = JobBoleArticleItem() #实例化定义的items item_loader = ItemLoader(item=JobBoleArticleItem(),response=response) #实例化item_loader,把我们定义的item传进去,再把下载器下载的网页穿进去
#针对直接取值的情况
item_loader.add_value("url",response.url)
item_loader.add_value("url_object_id",get_md5(response.url))
item_loader.add_value("front_image_url",[front_image_url])
#针对css选择器
item_loader.add_css("title",".entry-header h1::text")
item_loader.add_css("create_date","p.entry-meta-hide-on-mobile::text")
item_loader.add_css("praise_nums",".vote-post-up h10::text")
item_loader.add_css("comment_nums","a[href='#article-comment'] span::text")
item_loader.add_css("fav_nums",".bookmark-btn::text")
#把结果返回给items
article_item = item_loader.load_item()
- .add_value:把直接获取到的值,复制给字段
- .add_css:需要通过css选择器获取到的值
- .add_xpath:需要通过xpath选择器获取到的值
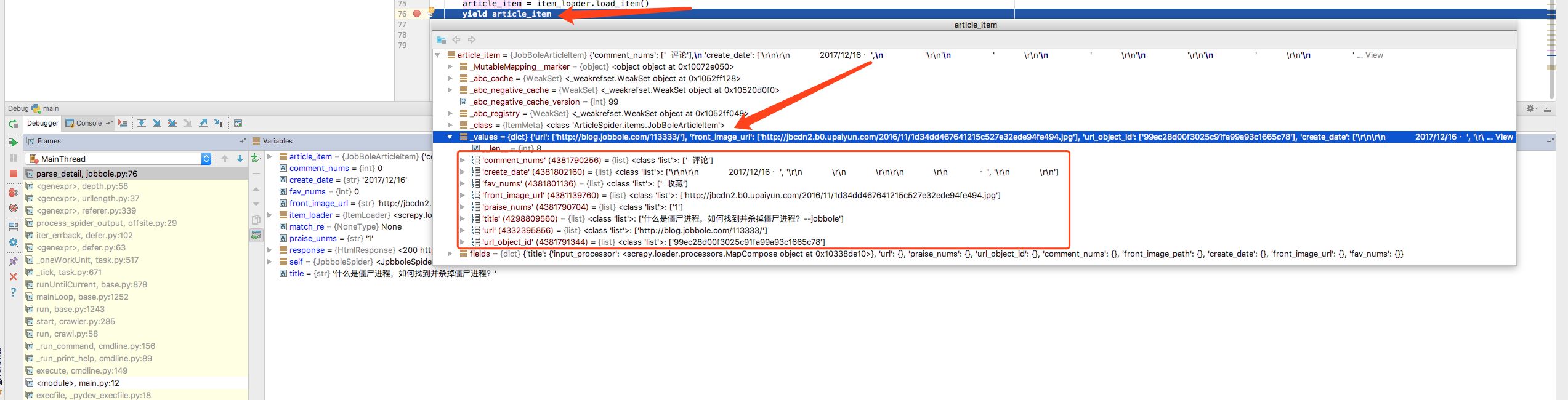
debug调试,可以看到拿到的信息
[scrapy]Item Loders的更多相关文章
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- scrapy item
item item定义了爬取的数据的model item的使用类似于dict 定义 在items.py中,继承scrapy.Item类,字段类型scrapy.Field() 实例化:(假设定义了一个名 ...
- 第十篇 scrapy item loader机制
在我们执行scrapy爬取字段中,会有大量的和下面的代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制 def parse_detail(sel ...
- scrapy item pipeline
item pipeline process_item(self, item, spider) #这个是所有pipeline都必须要有的方法在这个方法下再继续编辑具体怎么处理 另可以添加别的方法 ope ...
- 使用sqlalchemy用orm方式写pipeline将scrapy item快速存入 MySQL
传统的使用scrapy爬下来的数据存入mysql,用的是在pipeline里用pymysql存入数据库, 这种方法需要写sql语句,如果item字段数量非常多的 情况下,编写起来会造成很大的麻烦. 我 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- scrapy item处理----cooperator和parallel()函数
twisted的task之cooperator和scrapy的parallel()函数 本文是关于下载结果返回后调用item处理的过程实现研究. 从scrapy的结果处理说起 def handle_s ...
- Scrapy系列教程(2)------Item(结构化数据存储结构)
Items 爬取的主要目标就是从非结构性的数据源提取结构性数据,比如网页. Scrapy提供 Item 类来满足这种需求. Item 对象是种简单的容器.保存了爬取到得数据. 其提供了 类似于词典(d ...
随机推荐
- mysql 慢查询日志 pt-query-digest 工具安装
介绍:pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog.General log.slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump ...
- 安装tesserocr的步骤和报错RuntimeError: Failed to init API, possibly an invalid tessdata path解决办法
1,首先下载合适的tesseract-ocr的版本 2,然后安装到这一步注意要勾选这一项来安装OCR识别支持的语言包,这样OCR就可以识别多国语言,然后就可以一直点击下一步完成安装. 3,安装tess ...
- CentOS下配置LVM和RAID
1.CentOS配置LVM http://www.cnblogs.com/mchina/p/linux-centos-logical-volume-manager-lvm.html http://ww ...
- python 跨域
CORS跨域请求 CORS即Cross Origin Resource Sharing 跨域资源共享, 那么跨域请求还分为两种,一种叫简单请求,一种是复杂请求~~ 简单请求 HTTP方法是下列方法之一 ...
- C++中的临时变量
临时变量有两个特征: 1.invisiable,在程序代码中没有显式出现 2 没有名字 non - named. 出现临时变量/对象的场合1.函数的返回值2. 参数传递 值传递 by - value ...
- map 插入数据的方式局别
#include<map> #include<iostream> usingnamespace std; int main() { map <int, int> m ...
- mysql条件查询and or使用实例及优先级介绍
mysql and与or介绍 AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来. 使用OR关键字时: 只要符合这几个查询条件的其中一个条件,这样的记录就会被查询出来. 如果不符合这 ...
- linux下连接到远程主机,用图像界面(想在远程服务器上用cmake)
1. 需要通过SSH -X username@ip登陆服务器后,再用图形界面,比如用cmake 2.直接用 SSH username@ip命令登陆服务器后,不能用cmake
- 在LoadRunner中执行命令行程序之:popen()取代system()
我想大家应该都知道在LoadRunner可以使用函数system()来调用系统指令,结果同在批处理里执行一样. 但是system()有个缺陷:无法获取命令的返回结果. 也许你可以用`echo comm ...
- nginx反向代理,负载均衡,动静分离,rewrite地址重写介绍
一.rewrite地址重写 地址转发后客户端浏览器地址栏中的地址显示是不变的,而地址重写后地址栏中的地址会变成正确的地址. 在一次地址转发过程中只会产生一次网络请求,而一次地址重写产生两次请求. 地址 ...