scrapy item
item
item定义了爬取的数据的model
item的使用类似于dict
定义
在items.py中,继承scrapy.Item类,字段类型scrapy.Field()
实例化:(假设定义了一个名为Product的item类)
Product(key1=value1, key2=value2)
Product({key1:value1, key2:value2}
取赋值
product['key']
product.get('key')
product['key']=value
获取key,value的list
product.keys()
product.items()
转dict
dict(product)
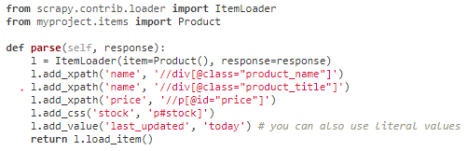
itemloader
scrapy item的更多相关文章
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- [scrapy]Item Loders
Items Items就是结构化数据的模块,相当于字典,比如定义一个{"title":"","author":""},i ...
- 第十篇 scrapy item loader机制
在我们执行scrapy爬取字段中,会有大量的和下面的代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制 def parse_detail(sel ...
- scrapy item pipeline
item pipeline process_item(self, item, spider) #这个是所有pipeline都必须要有的方法在这个方法下再继续编辑具体怎么处理 另可以添加别的方法 ope ...
- 使用sqlalchemy用orm方式写pipeline将scrapy item快速存入 MySQL
传统的使用scrapy爬下来的数据存入mysql,用的是在pipeline里用pymysql存入数据库, 这种方法需要写sql语句,如果item字段数量非常多的 情况下,编写起来会造成很大的麻烦. 我 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- scrapy item处理----cooperator和parallel()函数
twisted的task之cooperator和scrapy的parallel()函数 本文是关于下载结果返回后调用item处理的过程实现研究. 从scrapy的结果处理说起 def handle_s ...
- Scrapy系列教程(2)------Item(结构化数据存储结构)
Items 爬取的主要目标就是从非结构性的数据源提取结构性数据,比如网页. Scrapy提供 Item 类来满足这种需求. Item 对象是种简单的容器.保存了爬取到得数据. 其提供了 类似于词典(d ...
随机推荐
- 矩阵乘法C语言实现
/* 矩阵乘法C语言实现 Slyar 2009.3.20 */ #include <stdio.h> #include <stdlib.h> /* 给 int 类型定义 ...
- 使用sublime模板加快编码效率
这是使用模板系列的最后一篇了,也是最实用的方法. 前面提到的,插入文件的方法,适合计算机水平一般的初学者:而用TCL脚本的,则适合喜欢自定义各种奇特功能的专业人士. 那么,本次介绍的配置编辑器的方法, ...
- [elk]logstash的grok匹配逻辑grok+date+mutate
重点参考: http://blog.csdn.net/qq1032355091/article/details/52953837 logstash的精髓: grok插件原理 date插件原理 kv插件 ...
- Objective-C中的类型转换
转自:http://blog.csdn.net/lonelyroamer/article/details/7711920 类型转换 表2-3列出了简单数据类型.示例和格式符. 表2-3 简单数据类型. ...
- HTTP基本认证(Basic Authentication)的JAVA实例代码
大家在登录网站的时候,大部分时候是通过一个表单提交登录信息. 但是有时候浏览器会弹出一个登录验证的对话框,如下图,这就是使用HTTP基本认证. 下面来看看一看这个认证的工作过程: 第一步: 客户端发送 ...
- poj2392 Space Elevator(多重背包问题)
Space Elevator Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8569 Accepted: 4052 ...
- Macbook小问题
Macbook小问题 有时候 AppStore 和 Safari,QQ等 无法上网,但 chrome 却是正常的.解决办法:终端输入如下命令,其实是在 kill 掉网卡进程. sudo killall ...
- python 同时遍历多个变量
最近在用python的时候,用到遍历多个变量: import sys import math F58=11491939491.7 F=[11429229079.7,11374540753.7,1132 ...
- linux学习笔记34--命令rcp和scp
rcp代表“remote file copy”(远程文件拷贝).该命令用于在计算机之间拷贝文件.rcp命令有两种格式.第一种格式用于文件到文件的拷贝:第二种格式用于把文件或目录拷贝到另一个目录中. 1 ...
- python笔记-基础入门
Python 特点 1.易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单. 2.易于阅读:Python代码定义的更清晰. 3.易于维护:Python的成功在于 ...