Hadoop基础-SequenceFile的压缩编解码器
Hadoop基础-SequenceFile的压缩编解码器
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Hadoop压缩简介
1>.文件压缩的好处
第一:较少存储文件占用的磁盘空间,这样就加速数据在磁盘中的传输(比如源文件1G,经过压缩后只有10M,那么文件传输起来就相当的快啦!)
第二:节省网络带宽,很多时候将数据压缩不仅仅是为了存储,还是为了节省网络带块,在传输数据的时候,先将数据进行压缩处理再发送给接收端,接收端接到数据后会进解压操作,从而拿到真正的数据。
2>.Hadoop压缩算法
包括Deflate,Gzip,Bzip2,Lz4,Snappy等算法,其中Bzip2是极致压缩比例,而Lz4,Lzo和Snappy则是优化压缩速度,在生产环境下根据算法相关特性进行技术选型。
注意:Lzo(with index)和Bzip2是可切割的算法,适合在MR中使用。
3>.Hadoop压缩算法的对比

二.Gzip压缩与解压缩案例展示
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.compress; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.util.ReflectionUtils; import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream; public class TestCompressCodec {
private static final File srcFile = new File("D:\\10.Java\\IDE\\yhinzhengjieData\\CompressCodec\\jdk-9.CHM");
private static final File gzipFilePath = new File("D:\\10.Java\\IDE\\yhinzhengjieData\\CompressCodec\\yinzhengjie.gz");
private static final File gunzipFilePath = new File("D:\\10.Java\\IDE\\yhinzhengjieData\\CompressCodec\\yinzhengjie.CHM");
public static void main(String[] args) throws Exception {
GizpCompress();
GunizpCompress();
} //Gzip进行压缩的方法
public static void GizpCompress() throws Exception {
//获取程序开始执行的时间戳
long start = System.currentTimeMillis();
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//将hdfs写入的路径定义在本地,需要修改默认我文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。
conf.set("fs.defaultFS","file:///");
//通过hadoop提供的反射工具类ReflectionUtils的newInstance方法生成一个GzipCodec方法,第一个参数需要传入一个编解码器类,第二个参数需要传入一个Configuration对象。
GzipCodec gzipCodec = ReflectionUtils.newInstance(GzipCodec.class, conf);
//通过gzipCodec的createOutputStream方法创建出压缩输出流
CompressionOutputStream cos = gzipCodec.createOutputStream(new FileOutputStream(gzipFilePath));
//创建出需要压缩的文件
FileInputStream fis = new FileInputStream(srcFile);
//通过hadoop提供的拷贝类工具进行拷贝数据,第一个参数需要传入一个输入流,第二个参数需要传入一个输出流,第三个参数指定传输的缓冲区大小。
IOUtils.copyBytes(fis,cos,1024);
//释放资源
fis.close();
cos.close();
//获取程序结束执行的时间戳
long end = System.currentTimeMillis();
//输出时间压缩的时间
System.out.printf("源文件大小是:[%d]字节,压缩时间:[%d],压缩后的文件大小是:[%d]字节.\n",srcFile.length(),(end - start),gzipFilePath.length());
} //Gzip进行解压的方法
public static void GunizpCompress() throws Exception {
//获取程序开始执行的时间戳
long start = System.currentTimeMillis();
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//将hdfs写入的路径定义在本地,需要修改默认我文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。
conf.set("fs.defaultFS", "file:///");
//通过hadoop提供的反射工具类ReflectionUtils的newInstance方法生成一个GzipCodec方法,第一个参数需要传入一个编解码器类,第二个参数需要传入一个Configuration对象。
GzipCodec gzipCodec = ReflectionUtils.newInstance(GzipCodec.class, conf);
//通过gzipCodec的createOutputStream方法创建出解压输入流
CompressionInputStream cis = gzipCodec.createInputStream(new FileInputStream(gzipFilePath));
//创建解压后生成的文件
FileOutputStream fos = new FileOutputStream(gunzipFilePath);
//通过hadoop提供的工具类拷贝数据
IOUtils.copyBytes(cis,fos,1024);
//释放资源
fos.close();
cis.close();
//获取程序结束执行的时间戳
long end = System.currentTimeMillis();
//输出时间压缩的时间
System.out.printf("源文件大小是:[%d]字节,压缩时间:[%d],解压后的文件大小是:[%d]字节.\n",gzipFilePath.length(),(end - start),gunzipFilePath.length());
}
} /*
以上代码输出结果如下:
源文件大小是:[53712527]字节,压缩时间:[2360],压缩后的文件大小是:[53030595]字节.
源文件大小是:[53030595]字节,压缩时间:[336],解压后的文件大小是:[53712527]字节.
*/
代码执行之前目录文件如下:
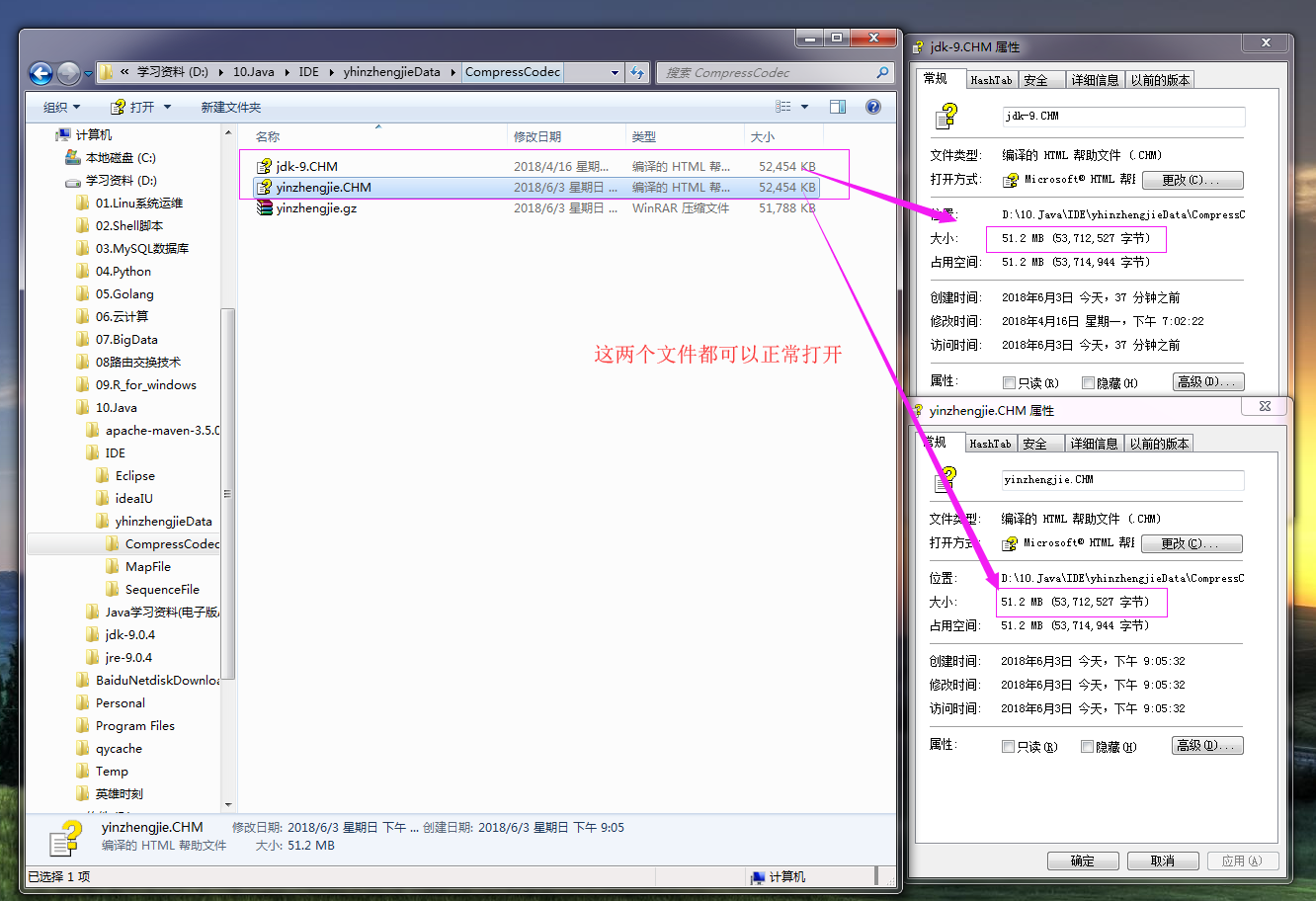
代码执行之后目录文件如下:
三.综合测试Hadoop压缩编解码器(windows环境测试,不包含Snappy压缩)
1>.测试代码如下:
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.compress; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.*;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream; public class TestCompressCodec {
/**
* 设置路径动态传参
* @param args
*/
public static void main(String[] args) {
if(args == null || args.length == 0){
System.out.println("需要输入路径");
System.exit(-1);
}
Class[] classes = {
DefaultCodec.class,
GzipCodec.class,
BZip2Codec.class,
Lz4Codec.class,
LzopCodec.class,
// SnappyCodec.class
};
for(Class clazz : classes){
testCompress(clazz, args[0]);
testDecompress(clazz,args[0]);
}
}
/**
* Gzip压缩
* @throws Exception
*/
public static void testCompress(Class clazz, String path) {
try {
long start = System.currentTimeMillis();
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "file:///");
CompressionCodec codec = (CompressionCodec)ReflectionUtils.newInstance(clazz, conf);
FileInputStream fis = new FileInputStream(path);
//获取扩展名
String ext = codec.getDefaultExtension();
//创建压缩输出流
CompressionOutputStream cos = codec.createOutputStream(new FileOutputStream(path+ext));
IOUtils.copyBytes(fis,cos,1024);
fis.close();
cos.close();
System.out.print("压缩类型:"+ ext+"\t"+ "压缩时间:" + (System.currentTimeMillis() - start)+ "\t");
File f = new File(path+ext);
System.out.print("文件大小:"+ f.length() + "\t");
} catch (Exception e) {
e.printStackTrace();
}
} /**
* Gzip解压
* @throws Exception
*/
public static void testDecompress(Class clazz,String path) {
try {
long start = System.currentTimeMillis();
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "file:///");
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(clazz, conf);
//扩展名
String ext = codec.getDefaultExtension();
//压缩输入流
CompressionInputStream cis = codec.createInputStream(new FileInputStream(path+ext));
FileOutputStream fos = new FileOutputStream(path+ext+".txt");
IOUtils.copyBytes(cis,fos,1024);
cis.close();
fos.close();
System.out.println("解压时间:" + (System.currentTimeMillis() - start));
} catch (Exception e) {
e.printStackTrace();
}
}
}
2>.Idea进行模拟命令行传参
点击编辑配置(Edit Configurations)
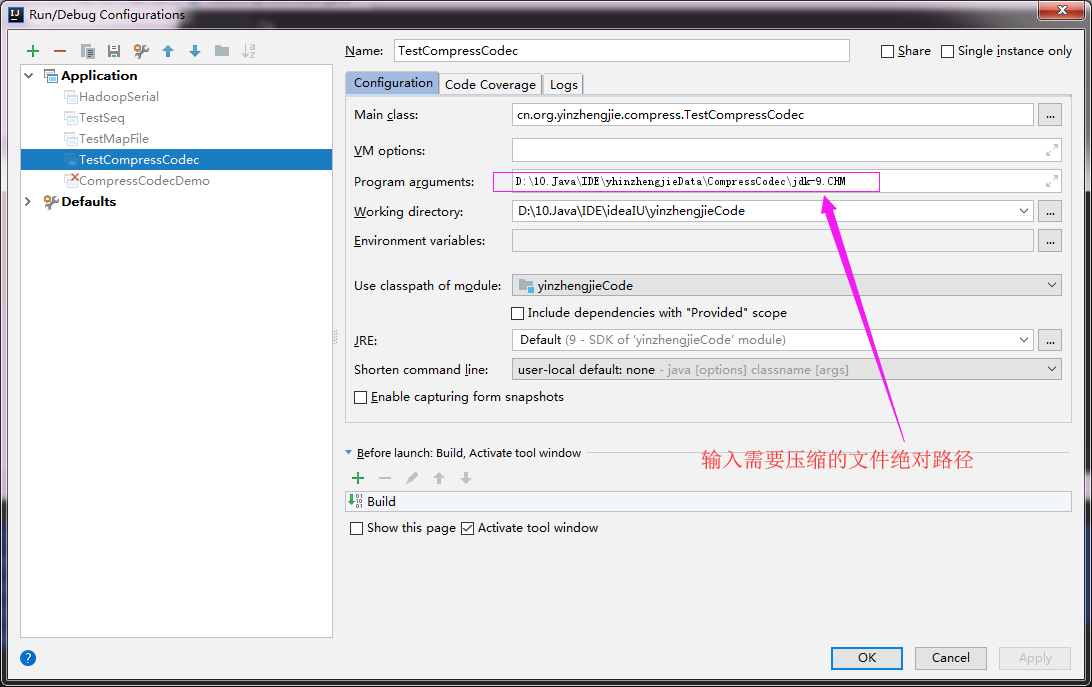
输入需要压缩的文件路径
3>.执行代码产物
执行代码之前目录文件如下:

执行代码之后目录文件如下:
4>.比较压缩结果
执行上述代码结果如下:
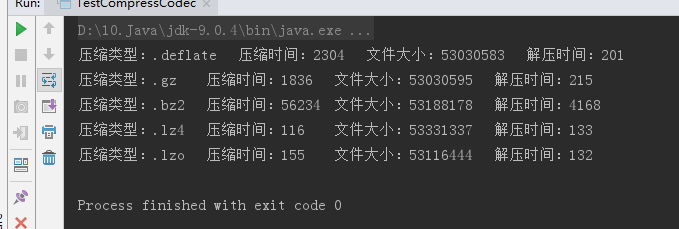
根据结果反推理论:(以上实验是我取了一次结果为准,生成环境最好以实际生成环境为准,这个数据仅供参考!)
压缩时间从小到大:lz4 < lzo < gz < deflate < bz2;
压缩大小从小到大:defalte < gz < lzo < bz2 < lz4;
解压时间从小到大:lzo < lz4 < deflate < gz < bz2;
注意,由于我此次测试环境是在windows,上述测试不包含Snappy压缩类型,想要查看Snappy压缩,请参考:https://www.cnblogs.com/yinzhengjie/p/9124038.html
四.压缩格式选型
1>.应该使用哪种压缩格式?(文笔摘自<<Hadoop权威指南第四册>>)
Hadoop 应用处理的数据集非常大,因此需要借助于压缩。使用哪种压缩格式与待处理的文件的大小,格式和所使用的工具相关。下面有一些建议,大致是按照效率从高到低排列的。
建议一:使用容器格文件格式,例如顺序文件,Avro数据文件,ORCFiles或者Parquet文件,所有含有这些文件格式同时支持压缩和切分。通常最好与一个快速压缩工具联合使用,例如:LZO,LZ4,或者Snappy。(推荐使用)
建议二:使用支持切分的压缩格式,例如 bzip2(尽管 bzip2非常慢),或者使用通过索引实现切分的压缩格式,例如:LZO。(推荐使用)
建议三:在应用中将文件切分成块,并使用任意一种压缩格式为每个数据块建立压缩文件(不论它是否支持切分)。在这种情况下,需要合理选择数据块的大小,以确保压缩后数据块的大小近似于HDFS块的大小。(不推荐)
建议四:存储未经过压缩的文件。(不推荐)
对大文件来说,不要使用不支持切分整个文件的压缩格式,因为会失去数据的本地特性,进而造成MapReduce应用效率底下。
2>.LZO通过索引实现切分的压缩格式案例展示
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.compress; import com.hadoop.compression.lzo.LzoIndexer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path; import java.io.IOException; public class LzoIndex {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置编解码器
conf.set("io.compression.codecs","org.apache.hadoop.io.compress.LzopCodec");
//创建一个LzoIndexer对象,需要传入conf对象
LzoIndexer indexer = new LzoIndexer(conf);
//需要指定协议为本地“file:///”
indexer.index(new Path("file:///D:\\10.Java\\IDE\\yhinzhengjieData\\CompressCodec\\jdk-9.CHM.lzo"));
}
} /*
以上代码执行成功后,会在D:\10.Java\IDE\yhinzhengjieData\CompressCodec\jdk-9.CHM.lzo同级目录下生成文件:D:\10.Java\IDE\yhinzhengjieData\CompressCodec\jdk-9.CHM.lzo.index文件。
*/
Hadoop基础-SequenceFile的压缩编解码器的更多相关文章
- Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例)
Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编辑配置文件(pml.xml)(我 ...
- hadoop基础-SequenceFile详解
hadoop基础-SequenceFile详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.SequenceFile简介 1>.什么是SequenceFile 序列文件 ...
- [SequenceFile_4] SequenceFile 配置压缩
0. 说明 SequenceFile 配置压缩编解码器 && 压缩类型的选型 1. SequenceFile 配置压缩编解码器 package hadoop.compression; ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop中SequenceFile的使用
1.对于某些应用而言,须要特殊的数据结构来存储自己的数据. 对于基于MapReduce的数据处理.将每一个二进制数据的大对象融入自己的文件里并不能实现非常高的可扩展性,针对上述情况,Hadoop开发了 ...
- hadoop深入研究:(七)——压缩
转载请标明出处:hadoop深入研究:(七)——压缩 文件压缩主要有两个好处,一是减少了存储文件所占空间,另一个就是为数据传输提速.在hadoop大数据的背景下,这两点尤为重要,那么我现在就先来了解下 ...
- Hadoop之SequenceFile
Hadoop序列化文件SequenceFile能够用于解决大量小文件(所谓小文件:泛指小于black大小的文件)问题,SequenceFile是Hadoop API提供的一种二进制文件支持.这样的二进 ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
随机推荐
- Team Member Introduction and Division of Work
Team leader Name:宋天舒 Student Number:12061166 Interested In: Information safety. Responsible For: Des ...
- TeamWork#1,Week 2,Learn In Team
我觉得做为一个团队,每个人的能力固然重要,但是更重要的是几个人能同心协力. 俗话说“三个臭皮匠,赛过诸葛亮”,团队合作往往能激发出团体不可思议的潜力,集体协作干出的成果往往能超过成员个人业绩的总和.在 ...
- Spring的Controller映射规则
URL映射 1) 一般格式@RequestMapping(value=“/test”) 2) 可以使用模板模式映射,@RequestMapping(value=“/test/{userId}”) 3) ...
- 第十章I/O
系统级i/o 开始进程时的三个标准: 标准输入(描述符0):STDIN_FILENO 标准输出(描述符1):STDOUT_FILENO 标准错误(描述符2):STDERR_FILENO 文件位置: 从 ...
- 用java进行简单的万年历编写
import java.util.Scanner; public class PrintCalendarDemo1 { public static void main(String[] args) { ...
- Teamwork(The fourth day of the team)
在这天我们已经开始去做自己手上的的任务.由于我们都忙于手头上的工作,所以这天我们就没有过多的交流,有的可能就是网上说一下实现到了哪里.
- 团队作业8——测试与发布(Beta阶段)之展示博客
展示博客 1. 团队成员的简介和个人博客地址,团队的源码仓库地址. a.陈福鹏 擅长技术:java.web等网站方面技术: 博客:http://www.cnblogs.com/royalchen/b. ...
- JavaWeb基础【1】—— Tomcat
此笔记是学习黑马程序员JavaWeb系列视频的课堂笔记. 感谢黑马程序员. 一.Tomcat概述 Tomcat服务器由Apache提供,开源免费.由于Sun和其他公司参与到了Tomcat的开发中,所以 ...
- forEach遍历数组对象且去重
forEach遍历数组对象 var obj1 = [{ key: '01', value: '哈哈' }, { key: '02', value: '旺旺' }, { key: '03', value ...
- Introduction to One-class Support Vector Machines
Traditionally, many classification problems try to solve the two or multi-class situation. The goal ...