hbase 安装(集群模式)
环境:jdk 1.8 + hadoop2.7.6+zookeeper3.4.9+centos7
一.安装zookeeper(集群模式)
0.安装机器
ip hostname
192.168.100.9 ns1
192.168.100.10 dn1
2.zookeeper tar包一栋至 ns1的 /usr/local,解压
tar -zxvf zookeeper-3.4..tar.gz
3.修改zk配置文件
cd /usr/local/zookeeper-3.4./conf cp zoo_sample.cfg zoo.cfg
修改配置文件zoo.cfg(所有节点的配置文件相同)
#tickTime这个时间是作为zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是说每个tickTime时间就会发送一个心跳
tickTime=
#initLimit这个配置项是用来配置zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数
initLimit=
#syncLimit这个配置项标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*=10秒
syncLimit=
#dataDir顾名思义就是zookeeper保存日志的目录
dataLogDir=/usr/local/zookeeper-3.4./logs
#dataDir顾名思义就是zookeeper保存数据的目录
dataDir=/usr/local/zookeeper-3.4./data
#clientPort这个端口就是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求;
clientPort=
#这个参数指定了需要保留的文件数目
autopurge.snapRetainCount=
#3.4.0及之后版本,ZK提供了自动清理事务日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功能。(No Java system property) New in 3.4.
autopurge.purgeInterval=
#server.A=B:C:D中的A是一个数字,表示这个是第几号服务器,B是这个服务器的IP地址,C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用的端口。
server.= 192.168.100.9::
server.= 192.168.100.10::
新建配置中的log data目录
4.配置myid
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下。
这个文件里面有一个数据就是A的值(该A就是zoo.cfg文件中server.A=B:C:D中的A),在zoo.cfg文件中配置的dataDir路径中创建myid文件。
#在192.168.1.148服务器上面创建myid文件,并设置值为1,同时与zoo.cfg文件里面的server.1保持一致,如下
echo "" > /usr/local/zookeeper-3.4./data/myid
在 dn1 上执行如下命令
echo "" > /usr/local/zookeeper-3.4./data/myid
5.添加环境变量
在两个节点的 /etc/profile中添加如下语句
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.
export PATH=${ZOOKEEPER_HOME}/bin:${PATH}
刷新环境变量
source /etc/profile
6.每个节点都启动zk 进行测试
sh /usr/local/zookeeper-3.4./bin/zkServer.sh start
查看状态:
sh /usr/local/zookeeper-3.4./bin/zkServer.sh status
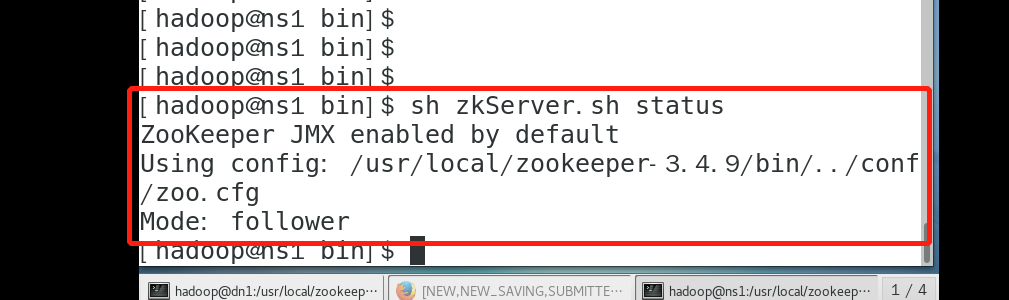
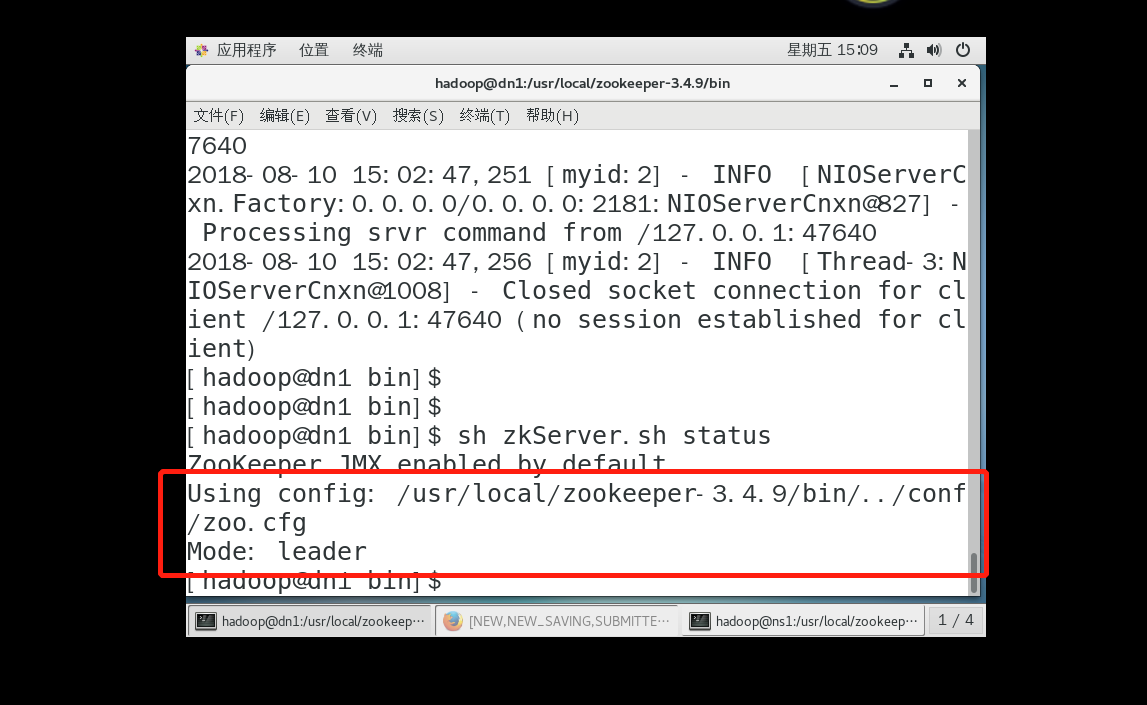
二 hbase 安装
1.下载hbase
2.解压到/user/local
tar -zxvf hbase-2.1.-bin.tar.gz
3.配置
cd /usr/local/hbase-2.1.0/conf
hbase-site.xml 修改如下
<configuration>
<!--此处的bx为以前搭建hdfs集群时,使用的那个集群代号-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1:9000/hbase</value>
</property>
<!--指定集群的几台zookeeper主机名-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>ns1,dn1</value>
</property>
<!--设置使用zookeeper集群,true为使用-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property> <property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase-2.1./tmp</value>
</property>
<!--ui端口,可通过ns1:60010访问web-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
</configuration>
hbase-env.sh 修改如下
#设置补充hbase 自带的zk
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/local/jdk
regionservers 添加节点
ns1
dn1
赋值hadoop core-site.xml ,hdfs-site.xml 到 /usr/local/hbase-2.1.0/conf
4.启动
ns1 上执行
sh /usr/local/hbase-2.1./bin/start-hbase.sh
5,查看状态
ns1 查看
[hadoop@ns1 bin]$ jps
HRegionServer
SecondaryNameNode
JobHistoryServer
HistoryServer
DataNode
Worker
Jps
38408 HMaster #hbase master
QuorumPeerMain
NameNode
Master
NodeManager
dn1 查看
[hadoop@dn1 local]$ jps
26754 HRegionServer #regionserver 已启动
Worker
Jps
QuorumPeerMain
DataNode
NodeManager
hbase 安装(集群模式)的更多相关文章
- Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Eclipse的下载 Eclipse的安装 Eclipse的使用 本地模式或集群模式 Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群 ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
- IntelliJ IDEA(Community版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! 对于初学者来说,建议你先玩玩这个免费的社区版,但是,一段时间,还是去玩专业版吧,这个很简单哈,学聪明点,去搞到途径激活!可以看我的博客. 包括: IntelliJ IDEA(Co ...
- Greenplum源码编译安装(单机及集群模式)完全攻略
公司有个项目需要安装greenplum数据库,让我这个gp小白很是受伤,在网上各种搜,结果找到的都是TMD坑货帖子,但是经过4日苦战,总算是把greenplum的安装弄了个明白,单机及集群模式都部署成 ...
- Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Scala IDE for Eclipse的下载 Scala IDE for Eclipse的安装 本地模式或集群模式 我们知道,对于开发而言,IDE是有很多个选择的版本.如我们大部分人经常 ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- 1.8分布式集群模式基础(VM安装多台服务器)
前言 一晃就是10几天,学习的过程是断断续续的,对个人来说,这并不是一个良好的状态.在这10几天了,迷恋起了PS... 从今天起,坚持一周4篇,额.希望吧 在之前的随笔中,我安装了Xshell 和 C ...
- Hbase的集群安装
hadoop集群的搭建 搭建真正的zookeeper集群 Hbase需要安装在成功部署的Hadoop平台,并且要求Hadoop已经正常启动. 同时,HBase需要集群部署,我们分别把HBase 部署到 ...
- IntelliJ IDEA(Ultimate版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! IntelliJ IDEA号称当前Java开发效率最高的IDE工具.IntelliJ IDEA有两个版本:社区版(Community)和旗舰版(Ultimate).社区版时免费的 ...
随机推荐
- Socket内核调用数SYSCALL_DEFINE3
http://blog.chinaunix.net/uid-20788636-id-4408261.html 前言: 对于Linux内核的Socket系列文章都是依据于:Linux-3.14.5的版本 ...
- iis webapi不间隔第一次访问超慢
第一种尝试(正在验证是否有效): 设置网站对应的应用程序池的"闲置超时"为0.如下图所示
- K-string HDU - 4641 (后缀自动机)
K-string \[ Time Limit: 2000 ms\quad Memory Limit: 131072 kB \] 题意 给出长度为 \(n\) 的字符串,接下来跟着 \(m\) 次操作, ...
- 云上的三台主机构建server-proxy-agent取不到数据
4252:20191126:172327.217 cannot send list of active checks to "xxx.190.39.152": host [ppp] ...
- ACM数据结构-线段树
1.维护区间最大最小值模板(以维护最小值为例) #include<iostream> #include<stdio.h> #define LEN 11 #define MAX ...
- Macbook Pro升级10.15后百度网盘无法登陆,网络连接错误(-1001)
兴冲冲升级到10.15,结果百度网盘挂了~QQ 由于长期在境外实验室做研究,百度又封锁了境外登陆,所以客户端是唯一跟家里联络的方式,现在它也挂了感觉整个天都塌下来了. 找了一圈,发现一个特别神奇的解锁 ...
- http响应消息
1. 请求消息:客户端发送给服务器端的数据 * 数据格式: 1. 请求行 2. 请求头 3. 请求空行 4. 请求体 2. 响应消息:服务器端发送给客户端的数据 * 数据格式: 1. 响应行 1. 组 ...
- ffmpeg结合SDL编写播放器(一)
ffmpeg 工具是一个高效快速的命令行工具,进行视音频不同格式之间的转换. ffmpeg命令行 ffmpeg可以读取任意数量的输入“文件”(可以是常规文件,管道,网络流,抓取设备等)读取,由 -i ...
- nginx 反向代理之 proxy_redirect
proxy_redirect 该指令用来修改被代理服务器返回的响应头中的Location头域和“refresh”头域. 语法结构为: proxy_redirect redirect replaceme ...
- mac 使用tesseract识别图片中的中文
安装 tesseractbrew install tesseract 加入环境变量export TESSDATA_PREFIX=/usr/local/Cellar/tesseract/4.1.0/sh ...