MapReduce本地运行模式wordcount实例(附:MapReduce原理简析)
1. 环境配置
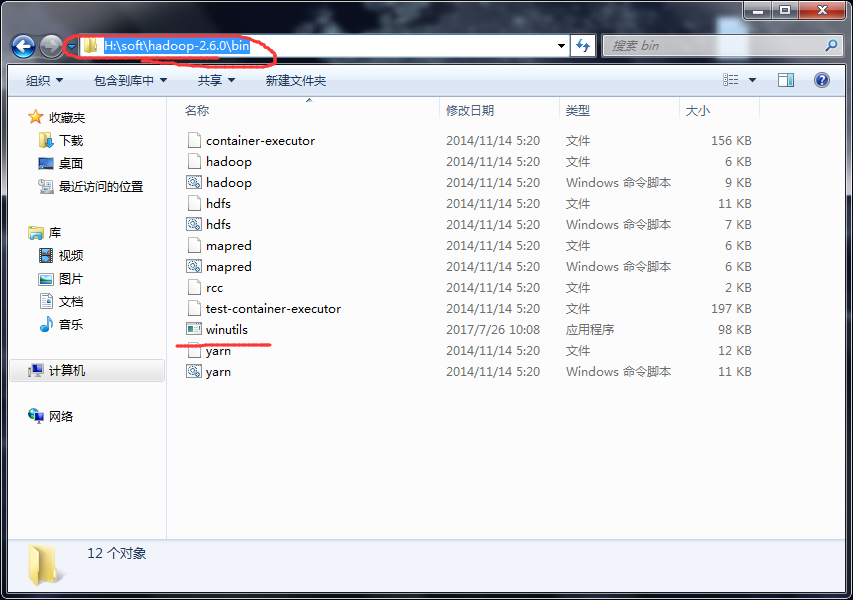
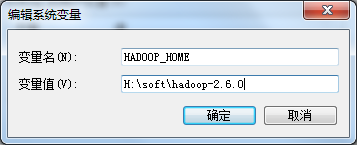
a) 配置系统环境变量HADOOP_HOME
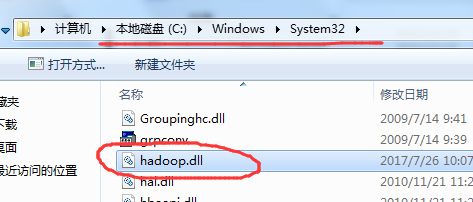
b) 把hadoop.dll文件放到c:/windows/System32目录下
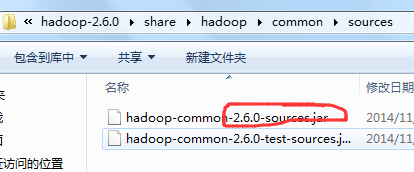
c) hadoop-2.6.0\share\hadoop\common\sources目录下hadoop-common-2.6.0-sources.jar文件中找到org\apache\hadoop\io\nativeio下NativeIO.java文件,复制到对应的Eclipse的project, NativeIO.java文件还要在原来的包名下


d) 修改此文件的557行,替换为return true
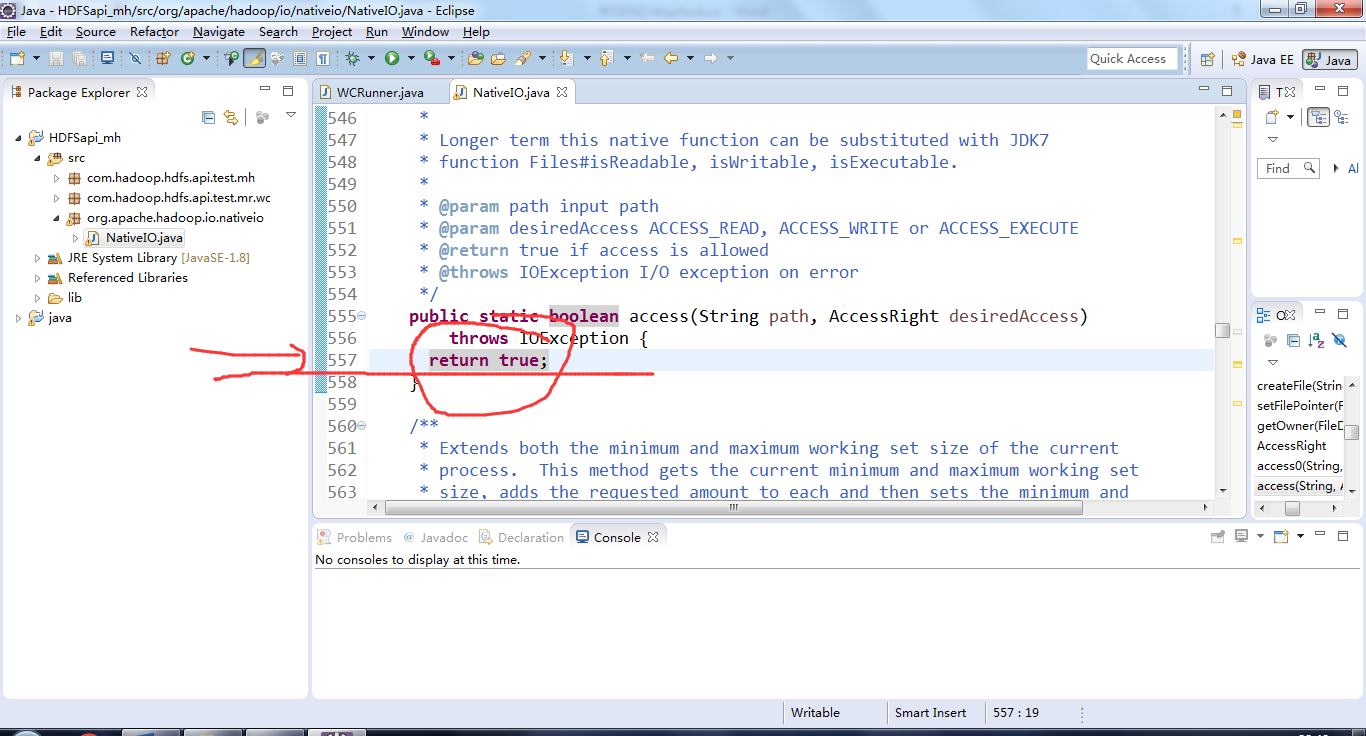
e) 在主机中配置虚拟机的IP和用户名
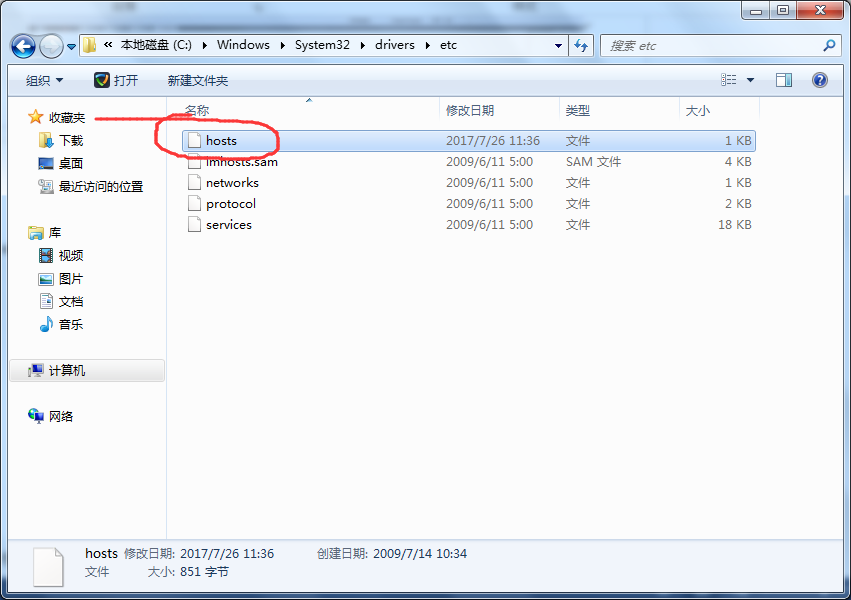
f) 以管理员身份运行eclipse
2. 代码(以wordcount为例)
a) MapReduce分Map和Reduce两部分,加上测试,一共三部分
b) Map里主要解决文件分割的问题;
package com.hadoop.hdfs.api.test.mr.wc;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*
* KEYIN, VALUEIN, 输入的key-value数据类型
*
* KEYOUT, VALUEOUT 输出的key-value数据类型
*
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
/* key:输入的key值,偏移量
value:输入的value,一行的内容
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
//获取一行的内容
String linestr=value.toString();
String[] words=linestr.split(" ");//正则表达式怎么实现这些东西?
for (String word : words) {
//输出写
context.write(new Text(word), new LongWritable(1));
}
}
}
c) 接收map的结果,然后整合输出
package com.hadoop.hdfs.api.test.mr.wc;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/*
* org.apache.hadoop.mapreduce是Hadoop2的api
*/
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
Iterator<LongWritable>iter=values.iterator();
long sum=0;
while(iter.hasNext()){
sum+=iter.next().get();
}
context.write(key, new LongWritable(sum));
}
}
d) 运行文件里只需要配置好路径即可
package com.hadoop.hdfs.api.test.mr.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WCRunner {
public static void main(String[] args) {
Configuration conf =new Configuration();
/* conf.set("hadoop.tmp.dir", "j:/tmp/tmpData");*/
try {
Job job=Job.getInstance(conf);
//指定main方法所在的类
job.setJarByClass(WCRunner.class);
//指定map和reduce类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
//指定map的输出key和value的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reduce的输出key和value的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//指定输入的文件目录,这里可以是文件,也可以是目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定输出的文件目录,这里只能是目录,不能是文件
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//执行job
job.waitForCompletion(true);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
注:数据类型
Value Text类型 Key LongWritable类型
特别声明:Text的包需要特别注意
运行前,传一下路径

Input是读文件的路径,里面的文件就是我们要读的
Output是reduce生成文件存放的地方
特别声明:input路径必须存在,output必须是不存在的
特特特别声明:用户名一定要注意,不要有空格!!!
MapReduce原理
MapReduce分为两大部分,Map(抓取数据、数据分割)和Reduce(处理数据,数据整合,上传数据)。
从单文件看MapReduce:
1. 从HDFS上读取一个文件
2. 为本地主机分配一个Map任务
3. Map作业从输入数据中抽取出键值对
4. 每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
5. 上一阶段中解析出来的每一个键值对,调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map方法会输出零个或者多个键值对。
6. 为本地主机分配一个Reduce任务
7. Reduce任务读取Map任务产生的中间值并排序(因为Map任务产生的键值对可能映射到不同的分区中,当然本地只有一个分区,所以要排序),排序的目的是使相同键的键值对聚集在一起。
8. 遍历排序后中间键值对,将具有相同键的键值对调用一次reduce方法,对每个不同的键分别调用一次reduce方法。
9. reduce函数产生的输出会添加到这个分区的输出文件中。
从集群上看MapReduce
1. 将HDFS上的文件分块,如需要输入的文件为100MB和200MB时,因为块大小为128MB,所以共分为三块,块一:100MB;块二:128MB;块三:72MB
每个块对应一个Map,需要三个Map进程来处理
2. 为集群上空闲的机器分配Map任务,被分配了Map作业的机器,开始读取对应分片的输入数据
3. 与单文件过程类似
4. Map产生的中间键值对分为N个区保存在本地中,每个区对应一个Reduce任务,将这N个区的位置报告给集群中负责调度的机器,让其将位置信息转发给已分配好Reduce任务的机器。
5. 有Reduce任务的机器从刚获取的地址处,读取中间键值对,然后与单文件类似
6. 所有执行完毕后,MapReduce输出放在了N个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这N个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。
注:关于Map和Reduce之间的数据传输过程,MapReduce的核心Shuffle,现在知识有限。只知道它的作用,不知道为什么作用,希望过几天可以整理一下
MapReduce本地运行模式wordcount实例(附:MapReduce原理简析)的更多相关文章
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- hadoop本地运行模式调试
一:简介 最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用:以运行hadoop下wordcount为例子. hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第 ...
- Eclipse Debug模式的开启与关闭问题简析_java - JAVA
文章来源:嗨学网 敏而好学论坛www.piaodoo.com 欢迎大家相互学习 默认情况下,eclipse中右键debug,当运行到设置的断点时会自动跳到debug模式下.但由于我的eclipse环境 ...
- Python实现MapReduce,wordcount实例,MapReduce实现两表的Join
Python实现MapReduce 下面使用mapreduce模式实现了一个简单的统计日志中单词出现次数的程序: from functools import reduce from multiproc ...
- Storm的本地运行模式示例
以word count为例,本地化运行模式(不需要安装zookeeper.storm集群),maven工程, pom.xml文件如下: <project xmlns="http://m ...
- 大数据-Hadoop 本地运行模式
Grep案例 1. 创建在hadoop-2.7.2文件下面创建一个input文件夹 [atguigu@hadoop101 hadoop-2.7.2]$ mkdir input 2. 将Hadoop的x ...
- hive架构原理简析-mapreduce部分
整个处理流程包括主要包括,语法解析(抽象语法树,AST,采用antlr),语义分析(sematic Analyzer生成查询块),逻辑计划生成(OP tree),逻辑计划优化,物理计划生成(Task ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
随机推荐
- Mysql-Percona mysql5.7简单安装
Mysql-Percona mysql5.7简单安装 一.什么是Percona 单从mysql的角度来讲,可以把Percona理解为mysql的一个分支,因为mysql的源码是开源的,Percona就 ...
- Java实习生面试题分享
1.Java有那些基本数据类型,String是不是基本数据类型,他们有何区别. Java语言提供了八种基本类型: 六种数字类型(四个整数型,两个浮点型) 字节型byte 8位 短整型short 16位 ...
- 18 | 为什么这些SQL语句逻辑相同,性能却差异巨大?
在MySQL中,有很多看上去逻辑相同,但性能却差异巨大的SQL语句.对这些语句使用不当的话,就会不经意间导致整个数据库的压力变大. 我今天挑选了三个这样的案例和你分享.希望再遇到相似的问题时,你可以做 ...
- *51nod 1815
从若干个数中选出最大的任意两数取模之后的结果 严格次大值 对于此题 首先缩点 然后拓扑排序 维护到达每个点的最大值与严格次大值 感觉思路与代码都OK啊 then.... #include <io ...
- 怎么联系$zcy$呢?
\(QQ:2939533969\) \(luogu:\)little_sun 窝经常以little_sun,little_sun0331,zcy05331的昵称混迹于各大网站 窝的CSDN blog ...
- AtCoder Grand Contest 001 题解
传送门 \(A\) 咕咕咕 const int N=505; int a[N],n,res; int main(){ scanf("%d",&n); fp(i,1,n< ...
- ROS参数服务器(Parameter Server)
操作演示,对参数服务器的理解:点击打开链接 rosparam使得我们能够存储并操作ROS 参数服务器(Parameter Server)上的数据.参数服务器能够存储整型.浮点.布尔.字符串.字典和列表 ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- C语言中怎样定义能够保存16进制整数的变量
可以通过int 或long int存储,16进制整数说到底还是整数,16进制只是一种记数方式.例如,int x=0x16;十六进制(hexadecimal)只是计算机中数据的一种表示方法,规则是“逢十 ...
- 小程序tabBar的使用
这个selectedIconPath一定要写,否则选中的那个图片是不会显示的 下面是不写的现象: onTabItemTap的使用---下面的现象说明:只有tab值向哪个页面才会触发.