百度开源分布式id生成器uid-generator源码剖析
百度uid-generator源码
https://github.com/baidu/uid-generator
snowflake算法
uid-generator是基于Twitter开源的snowflake算法实现的。
snowflake将long的64位分为了3部分,时间戳、工作机器id和序列号,位数分配如下。
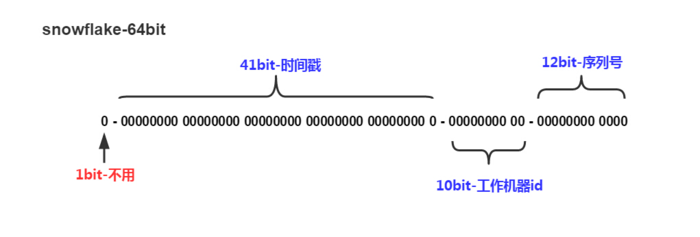
其中,时间戳部分的时间单位一般为毫秒。也就是说1台工作机器1毫秒可产生4096个id(2的12次方)。
源码实现分析
与原始的snowflake算法不同,uid-generator支持自定义时间戳、工作机器id和序列号等各部分的位数,以应用于不同场景。默认分配方式如下。

sign(1bit)
固定1bit符号标识,即生成的UID为正数。delta seconds (28 bits)
当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年(注意:1. 这里的单位是秒,而不是毫秒! 2.注意这里的用词,是“最多”可支持8.7年,为什么是“最多”,后面会讲)worker id (22 bits)
机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。sequence (13 bits)
每秒下的并发序列,13 bits可支持每秒8192个并发。(注意下这个地方,默认支持qps最大为8192个)
DefaultUidGenerator
DefaultUidGenerator的产生id的方法与基本上就是常见的snowflake算法实现,仅有一些不同,如以秒为为单位而不是毫秒。
DefaultUidGenerator的产生id的方法如下。
protected synchronized long nextId() {
long currentSecond = getCurrentSecond();
// Clock moved backwards, refuse to generate uid
if (currentSecond < lastSecond) {
long refusedSeconds = lastSecond - currentSecond;
throw new UidGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds);
}
// At the same second, increase sequence
if (currentSecond == lastSecond) {
sequence = (sequence + 1) & bitsAllocator.getMaxSequence();
// Exceed the max sequence, we wait the next second to generate uid
if (sequence == 0) {
currentSecond = getNextSecond(lastSecond);
}
// At the different second, sequence restart from zero
} else {
sequence = 0L;
}
lastSecond = currentSecond;
// Allocate bits for UID
return bitsAllocator.allocate(currentSecond - epochSeconds, workerId, sequence);
}
CachedUidGenerator
CachedUidGenerator支持缓存生成的id。
基本实现原理
关于CachedUidGenerator,文档上是这样介绍的。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
【采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费】

使用RingBuffer缓存生成的id。RingBuffer是个环形数组,默认大小为8192个,里面缓存着生成的id。
获取id
会从ringbuffer中拿一个id,支持并发获取
填充id
RingBuffer填充时机
程序启动时,将RingBuffer填充满,缓存着8192个id
在调用getUID()获取id时,检测到RingBuffer中的剩余id个数小于总个数的50%,将RingBuffer填充满,使其缓存8192个id
定时填充(可配置是否使用以及定时任务的周期)
【UidGenerator通过借用未来时间来解决sequence天然存在的并发限制】
因为delta seconds部分是以秒为单位的,所以1个worker 1秒内最多生成的id书为8192个(2的13次方)。
从上可知,支持的最大qps为8192,所以通过缓存id来提高吞吐量。
为什么叫借助未来时间?
因为每秒最多生成8192个id,当1秒获取id数多于8192时,RingBuffer中的id很快消耗完毕,在填充RingBuffer时,生成的id的delta seconds 部分只能使用未来的时间。
(因为使用了未来的时间来生成id,所以上面说的是,【最多】可支持约8.7年)
源码剖析
获取id
@Override
public long getUID() {
try {
return ringBuffer.take();
} catch (Exception e) {
LOGGER.error("Generate unique id exception. ", e);
throw new UidGenerateException(e);
}
}
RingBuffer缓存已生成的id
(注意:这里的RingBuffer不是Disruptor框架中的RingBuffer,但是借助了很多Disruptor中RingBuffer的设计思想,比如使用缓存行填充解决伪共享问题)
RingBuffer为环形数组,默认容量为sequence可容纳的最大值(8192个),可以通过boostPower参数设置大小。
tail指针、Cursor指针用于环形数组上读写slot:
Tail指针
表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicyCursor指针
表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。

public class RingBuffer {
private static final Logger LOGGER = LoggerFactory.getLogger(RingBuffer.class);
/** Constants */
private static final int START_POINT = -1;
private static final long CAN_PUT_FLAG = 0L; //用于标记当前slot的状态,表示可以put一个id进去
private static final long CAN_TAKE_FLAG = 1L; //用于标记当前slot的状态,表示可以take一个id
public static final int DEFAULT_PADDING_PERCENT = 50; //用于控制何时填充slots的默认阈值:当剩余的可用的slot的个数,小于bufferSize的50%时,需要生成id将slots填满
/** The size of RingBuffer's slots, each slot hold a UID */
private final int bufferSize; //slots的大小,默认为sequence可容量的最大值,即8192个
private final long indexMask;
private final long[] slots; //slots用于缓存已经生成的id
private final PaddedAtomicLong[] flags; //flags用于存储id的状态(是否可填充、是否可消费)
/** Tail: last position sequence to produce */
//Tail指针
//表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicy
private final AtomicLong tail = new PaddedAtomicLong(START_POINT); //
/** Cursor: current position sequence to consume */
//表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
private final AtomicLong cursor = new PaddedAtomicLong(START_POINT);
/** Threshold for trigger padding buffer*/
private final int paddingThreshold; //用于控制何时填充slots的阈值
/** Reject put/take buffer handle policy */
//当slots满了,无法继续put时的处理策略。默认实现:无法进行put,仅记录日志
private RejectedPutBufferHandler rejectedPutHandler = this::discardPutBuffer;
//当slots空了,无法继续take时的处理策略。默认实现:仅抛出异常
private RejectedTakeBufferHandler rejectedTakeHandler = this::exceptionRejectedTakeBuffer;
/** Executor of padding buffer */
//用于运行【生成id将slots填满】任务
private BufferPaddingExecutor bufferPaddingExecutor;
RingBuffer填充时机
程序启动时,将RingBuffer填充满,缓存着8192个id
在调用getUID()获取id时,检测到RingBuffer中的剩余id个数小于总个数的50%,将RingBuffer填充满,使其缓存8192个id
定时填充(可配置是否使用以及定时任务的周期)
填充RingBuffer
/**
* Padding buffer fill the slots until to catch the cursor
*/
public void paddingBuffer() {
LOGGER.info("Ready to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer); // is still running
if (!running.compareAndSet(false, true)) {
LOGGER.info("Padding buffer is still running. {}", ringBuffer);
return;
} // fill the rest slots until to catch the cursor
boolean isFullRingBuffer = false;
while (!isFullRingBuffer) {
//获取生成的id,放到RingBuffer中。
List<Long> uidList = uidProvider.provide(lastSecond.incrementAndGet());
for (Long uid : uidList) {
isFullRingBuffer = !ringBuffer.put(uid);
if (isFullRingBuffer) {
break;
}
}
} // not running now
running.compareAndSet(true, false);
LOGGER.info("End to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);
}
生成id(上面代码中的uidProvider.provide调用的就是这个方法)
/**
* Get the UIDs in the same specified second under the max sequence
*
* @param currentSecond
* @return UID list, size of {@link BitsAllocator#getMaxSequence()} + 1
*/
protected List<Long> nextIdsForOneSecond(long currentSecond) {
// Initialize result list size of (max sequence + 1)
int listSize = (int) bitsAllocator.getMaxSequence() + 1;
List<Long> uidList = new ArrayList<>(listSize); // Allocate the first sequence of the second, the others can be calculated with the offset
//这里的实现很取巧
//因为1秒内生成的id是连续的,所以利用第1个id来生成后面的id,而不用频繁调用snowflake算法
long firstSeqUid = bitsAllocator.allocate(currentSecond - epochSeconds, workerId, 0L);
for (int offset = 0; offset < listSize; offset++) {
uidList.add(firstSeqUid + offset);
} return uidList;
}
填充缓存行解决“伪共享”
关于伪共享,可以参考这篇文章《伪共享(false sharing),并发编程无声的性能杀手》
//数组在物理上是连续存储的,flags数组用来保存id的状态(是否可消费、是否可填充),在填入id和消费id时,会被频繁的修改。
//如果不进行缓存行填充,会导致频繁的缓存行失效,直接从内存中读数据。
private final PaddedAtomicLong[] flags; //tail和cursor都使用缓存行填充,是为了避免tail和cursor落到同一个缓存行上。
/** Tail: last position sequence to produce */
private final AtomicLong tail = new PaddedAtomicLong(START_POINT); /** Cursor: current position sequence to consume */
private final AtomicLong cursor = new PaddedAtomicLong(START_POINT)
/**
* Represents a padded {@link AtomicLong} to prevent the FalseSharing problem<p>
*
* The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:<br>
* 64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value)
* @author yutianbao
*/
public class PaddedAtomicLong extends AtomicLong {
private static final long serialVersionUID = -3415778863941386253L; /** Padded 6 long (48 bytes) */
public volatile long p1, p2, p3, p4, p5, p6 = 7L; /**
* Constructors from {@link AtomicLong}
*/
public PaddedAtomicLong() {
super();
} public PaddedAtomicLong(long initialValue) {
super(initialValue);
} /**
* To prevent GC optimizations for cleaning unused padded references
*/
public long sumPaddingToPreventOptimization() {
return p1 + p2 + p3 + p4 + p5 + p6;
} }
PaddedAtomicLong为什么要这么设计?
可以参考下面文章
一个Java对象到底占用多大内存?https://www.cnblogs.com/magialmoon/p/3757767.html
写Java也得了解CPU--伪共享 https://www.cnblogs.com/techyc/p/3625701.html
百度开源分布式id生成器uid-generator源码剖析的更多相关文章
- 美团分布式ID生成框架Leaf源码分析及优化改进
本文主要是对美团的分布式ID框架Leaf的原理进行介绍,针对Leaf原项目中的一些issue,对Leaf项目进行功能增强,问题修复及优化改进,改进后的项目地址在这里: Leaf项目改进计划 https ...
- 常用的分布式ID生成器
为何需要分布式ID生成器 **本人博客网站 **IT小神 www.itxiaoshen.com **拿我们系统常用Mysql数据库来说,在之前的单体架构基本是单库结构,每个业务表的ID一般从1增,通过 ...
- Python源码剖析|百度网盘免费下载|Python新手入门|Python新手学习资料
百度网盘免费下载:Python源码剖析|新手免费领取下载 提取码:g78z 目录 · · · · · · 第0章 Python源码剖析——编译Python0.1 Python总体架构0.2 Pyth ...
- OpenMPI源码剖析1:MPI_Init初探
OpenMPI的底层实现: 我们知道,OpenMPI应用起来还是比较简单的,但是如果让我自己来实现一个MPI的并行计算,你会怎么设计呢?————这就涉及到比较底层的东西了. 回想起我们最简单的代码,通 ...
- 分布式ID生成器的解决方案总结
在互联网的业务系统中,涉及到各种各样的ID,如在支付系统中就会有支付ID.退款ID等.那一般生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种适合自己的解决方案是十分重要 ...
- 如何快速开发一个支持高效、高并发的分布式ID生成器
ID生成器是指能产生不重复ID服务的程序,在后台开发过程中,尤其是分布式服务.微服务程序开发过程中,经常会用到,例如,为用户的每个请求产生一个唯一ID.为每个消息产生一个ID等等,ID生成器也是进行无 ...
- go语言实现分布式id生成器
本文:https://chai2010.cn/advanced-go-programming-book/ch6-cloud/ch6-01-dist-id.html 分布式id生成器 有时我们需要能够生 ...
- 分布式ID生成器及redis,etcd分布式锁
分布式id生成器 有时我们需要能够生成类似MySQL自增ID这样不断增大,同时又不会重复的id.以支持业务中的高并发场景.比较典型的,电商促销时,短时间内会有大量的订单涌入到系统,比如每秒10w+.明 ...
- c#分布式ID生成器
c#分布式ID生成器 简介 这个是根据twitter的snowflake来写的.这里有中文的介绍. 如上图所示,一个64位ID,除了最左边的符号位不用(固定为0,以保证生成的ID都是正数),还剩余 ...
随机推荐
- 2017-2018-2 20165330实验二《Java面向对象程序设计》实验报告
实验内容 初步掌握单元测试和TDD 理解并掌握面向对象三要素:封装.继承.多态 初步掌握UML建模 熟悉S.O.L.I.D原则 了解设计模式 实验步骤 (一)单元测试 三种代码 伪代码:从意图层面来解 ...
- 2017 Multi-University Training Contest - Team 6—HDU6098&&HDU6106&&HDU6103
HDU6098 Inversion 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6098 题目意思:题目很短,给出一个数组,下标从1开始,现在输出一个 ...
- python中的itertools
在量化数据处理中,经常使用itertools来完成数据的各种排列组合以寻找最优参数 import itertools #1. permutations: 考虑顺序组合元素 items = [1, 2, ...
- 重点:怎样正确的使用QThread类(很多详细例子的对比,注意:QThread 中所有实现的函数是被创建它的线程来调用的,不是在线程中)good
背景描述: 以前,继承 QThread 重新实现 run() 函数是使用 QThread唯一推荐的使用方法.这是相当直观和易于使用的.但是在工作线程中使用槽机制和Qt事件循环时,一些用户使用错了.Qt ...
- LeetCode_Insertion Sort List
题目:Sort a linked list using insertion sort,即仿照插入排序(直接插入排序)对一个链表排序. 插入排序的思想:总共进行n-1趟排序,在排列第i个元素时,前面的i ...
- CDH部署日志
CDH部署时出现如图所示的错误 可去服务器查看:/opt/cm-5.5.0/run/cloudera-scm-agent/process/ccdeploy_hbase-conf_etchbasecon ...
- Android Volley全然解析(四),带你从源代码的角度理解Volley
版权声明:本文出自郭霖的博客,转载必须注明出处. https://blog.csdn.net/sinyu890807/article/details/17656437 转载请注明出处:http://b ...
- 转 Merkle Tree(默克尔树)算法解析
Merkle Tree概念 Merkle Tree,通常也被称作Hash Tree,顾名思义,就是存储hash值的一棵树.Merkle树的叶子是数据块(例如,文件或者文件的集合)的hash值.非叶节 ...
- C语言中const和数组
C语言中const的用法 const:在定义变量时,如果使用关键字const,那就表示限制这个变量值不允许被改变. (1) 修饰变量 const离谁越近,谁的值就不能改变. int const ...
- 压力测试工具MySQL mysqlslap
MySQL mysqlslap压测 2016-09-12 17:49 by pursuer.chen, 771 阅读, 0 评论, 收藏, 编辑 介绍 mysqlslap是mysql自带的一个性能压测 ...