洗礼灵魂,修炼python(53)--爬虫篇—urllib模块
urllib
1.简介:
urllib 模块是python的最基础的爬虫模块,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象。urllib 支持各种 web 协议,例如:HTTP、FTP、Gopher;同时也支持对本地文件进行访问。但一般而言多用来进行爬虫的编写。
2.方法/属性:

3.常用的方法/属性解析:
urllib.urlopen(url[, data[, proxies[, context]]]):打开网页
创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。参数url表示远程数据的路径,一般是网址;参数data表示以post方式提交到url的数据(玩过web的人应该知道提交数据的两种方式:post与get。如果你不清楚,也不必太在意,一般情况下很少用到这个参数);参数proxies用于设置代理(这里不详细讲怎么使用代理,感兴趣的看客可以去翻阅Python手册urllib模块)。urlopen返回 一个类文件对象(前面说过的,不再赘述)
- url : 一个完整的远程资源路径,一般都是一个网站,比如前面用到的http://www.baidu.com。(注意,要包含协议头,例如:http://www.baidu.com/,此处的 http:// 不能省略), 如果该URL没有指明协议类型,或者其协议标识符,则该函数会打开本地文件。如果无法打开远程地址,则会触发IOError异常。
- data :是一个可选的参数,如果使用的是 http:// 协议,用于指定一个 POST 请求(默认使用的是 GET 方法)。这个参数必须使用标准的 application/x-www-form-urlencoded 格式。可以使用 urlencode() 方法来快速生成。
- proxies : 设置代理,详细的参照官方文档
最常用的方法已经说过,带data参数这里暂时不解析,见下一篇博文urllib2模块
urllib.urlretrieve(url[, filename[, reporthook[, data]]]):下载数据
urlretrieve方法直接将远程数据下载到本地。参数filename指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);参数reporthook是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函 数来显示当前的下载进度,下面的例子会展示。参数data指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。下面通过例子来演示一下这个方法的使用,这个例子将新浪首页的html抓取到本地,保存在D:/sina.html文件中,同时显示下载的进度
- url : 目标 url 。
- filename : 下载到本地后保存的文件名, 可以是决对路径或相对路径形式。如果没有给,将缓存到一个临时文件夹中。
- reporthook:一个回调函数,方法会在连接建立时和下载完成时调用这个函数。同时会向函数传递三个参数:1.目前为止下载了多少数据块;2.数据块的大小(单位是字节);3.文件的总大小;
- data:一个可选的参数(同上面的data)
这个其实很少用,并且还要定义一个回调函数,用到的时候再做解析吧。
urllib.urlcleanup():清楚urllib.urlretrieve()的缓存
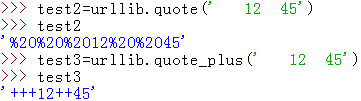
urllib.quote(string[, safe]):对字符串进行编码,参数safe指定了不需要编码的字符。
url中是不能出现一些特殊的符号的,有些符号有特殊的用途。我们知道以get方式提交数据的时候,会在url中添加key=value这样的字符串,所以在value中是不允许有’=’,因此要对其进行编码;与此同时服务器接收到这些参数的时候,要进行解码,还原成原始的数据
例:

urllib.quote_plus(string[, safe]):同urllib.quote(),唯一区别是会把空格转为【+】,而quote()用’%20’来代替空格
urllib.unquote(string):对字符串进行解码,urllib.quote()的逆操作

注意:这里要说一下,由于python2默认编码是ASCII,所以对中文解码就是这样的,这不是一个问题,姑且不管吧,后面写爬虫还会遇到很多
urllib.unquote_plus(string):对字符串进行解码,urllib.quote_plus()的逆操作,类似quote()
urllib.urlencode(query[, doseq]):将dict或者包含两个元素的元组列表转换成url请求参数
例:

注意:一旦urlopen设置的 data,就意味使用 POST 请求,如果要使用 GET 请求,请在 url 的后面加上?号才能把数据放进去
GET
import urllib
dict1= urllib.urlencode({'x': 1, 'y': 2, 'z': 3})
html= urllib.urlopen("http://www.baidu.com?%s" %dict1)
print html.read()
POST
import urllib
dict1= urllib.urlencode({'x': 1, 'y': 2, 'z': 3})
html= urllib.urlopen("http://www.baidu.com", dict1)
print html.read()
urllib.pathname2url(path):将本地路径转换成url路径
urllib.url2pathname(path):将url路径转换成本地路径

免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站站长有异议,请联系我立即删除
洗礼灵魂,修炼python(53)--爬虫篇—urllib模块的更多相关文章
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- Python内置的urllib模块不支持https协议的解决办法
Django站点使用django_cas接入SSO(单点登录系统),配置完成后登录,抛出“urlopen error unknown url type: https”异常.寻根朔源发现是python内 ...
- 练手爬虫用urllib模块获取
练手爬虫用urllib模块获取 有个人看一段python2的代码有很多错误 import re import urllib def getHtml(url): page = urllib.urlope ...
- 洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1)
爬虫篇前面的某一章了,我们要爬取网站页面源代码的数据,要从中获取到我们想要的数据,是不是感觉很费力,确实费力对吧?那么有没有什么有利的工具来解决这个问题呢?那就是这一篇博文的主题—— 正则表达式简介 ...
- 洗礼灵魂,修炼python(54)--爬虫篇—urllib2模块
urllib2 1.简介 urllib2模块定义的函数和类用来获取URL(主要是HTTP的),他提供一些复杂的接口用于处理: 基本认证,重定向,Cookies等.urllib2和urllib差不多,不 ...
- 04.Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- 爬虫之urllib模块
1. urllib模块介绍 python自带的一个基于爬虫的模块. 作用:可以使用代码模拟浏览器发起请求. 经常使用到的子模块:request,parse. 使用流程: 指定URL. 针对指定的URL ...
随机推荐
- Go语言之Interface(一)
Go语言之Interface(一) 什么是interface 在面向对象语言中接口是:接口定义了一个对象的行为,但在Go中接口就是方法签名的集合,当一个类型提供了这个接口中的所有的方法,就可以说这个类 ...
- Linux 软件安装到 /usr,/usr/local/ 还是 /opt 目录?
转自:https://blog.csdn.net/aqxin/article/details/48324377 Linux 的软件安装目录是也是有讲究的,理解这一点,在对系统管理是有益的 /usr:系 ...
- maven snapshot和release版本的区别
Maven的Snapshot版本与Release版本 1. Snapshot版本代表不稳定.尚处于开发中的版本 2. Release版本则代表稳定的版本 3. 什么情况下该用SNAPSHOT? 协同开 ...
- SpringMVC之文件上传异常处理
一般情况下,对上传的文件会进行大小的限制.如果超过指定大小时会抛出异常,一般会对异常进行捕获并友好的显示出来.以下用SpringMVC之文件上传进行完善. 首先配置CommonsMultipartRe ...
- Mysql 5.7 基于组复制(MySQL Group Replication) - 运维小结
之前介绍了Mysq主从同步的异步复制(默认模式).半同步复制.基于GTID复制.基于组提交和并行复制 (解决同步延迟),下面简单说下Mysql基于组复制(MySQL Group Replication ...
- PHP 正则表达式资料
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串.将匹配的子串做替换或者从某个串中取出符合某个条件的子串等. 举例来说,正则表达式的一个 ...
- 共享内存 - shmget填坑记
1. 问题引出 最近有个项目,需要两个进程之间传递大量的数据,因此考虑采用了共享 内存机制+信号同步,两个进程,笔者和另外一程序员开发,协议都定好了,开发很顺利. 等到我们联合调试的时候,问题出现了, ...
- C# QuartZ使用实例写成服务
官方学习文档:http://www.quartz-scheduler.net/documentation/index.html 官方的源代码下载:http://sourceforge.net/proj ...
- ASP.NET Web API 启用跨域访问
自定义特性 要在WebApi中实现JSONP,一种方式是实现自定义特性 http://stackoverflow.com/questions/9421312/jsonp-with-asp-net-w ...
- IdentityServer4-Resource定义-翻译
资源定义(Defining Resource) 通常,第一件事是定义那些你想保护的资源.这些资源可能是你的用户信息,比如个人数据,电子邮件或者对Api的访问. Note: 你可以用C#实体类来定义资源 ...