pandas-缺失值处理
import pandas as pd
import numpy as np
Step 1.加载数据集
# header=0以第一行作为列名
tip = pd.read_csv("lianx.csv",sep=',',header=0)
tip.head()
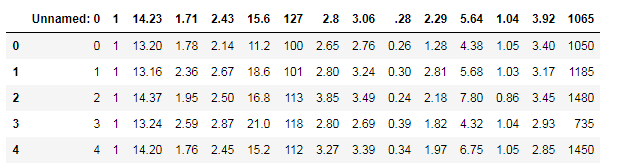
Step 2.删除第 1,4,7,9,11,13,14列,保存修改
a = list(tip.columns)
print(a)
b = []
c = 0
for i in a:
c= c+1
if c in [1,4,7,9,11,13,14]:
b.append(i)
# print(b)
# 删除列
tip = tip.drop(b,axis=1)
tip.head()
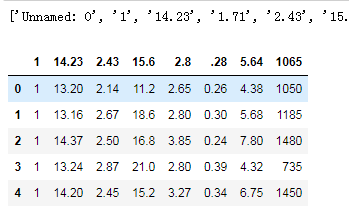
step 3.重命名列列索引依次为
1) alcohol
2) malic_acid
3) alcalinity_of_ash
4) magnesium
5) flavanoids
6) proanthocyanins
7) hue
c = ['alcohol','malic_acid','alcalinity_of_ash','magnesium','flavanoids','proanthocyanins','hue']
b = list(tip.columns[:7])
b2 = list(tip.columns)
print(b)
print(b2)
d = dict(zip(b,c))
print(d)
tip.rename(columns=d,inplace=True)
tip.head()

step 4.将alcohol 这一列的前三行改为NaN
#tip.iloc[:3,0]=np.nan
tip.iloc[:3,0]=np.nan
tip.head()
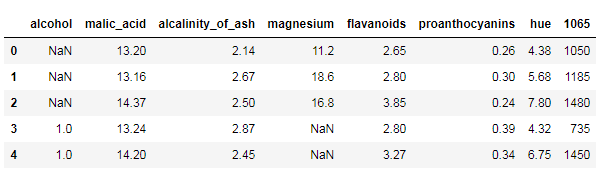
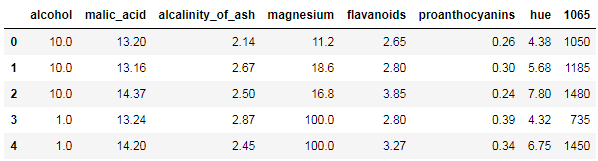
step 6. 将 alcohol 和 magnesium列的缺失值分别用10和100进行填充
tip['alcohol'] = tip['alcohol'].fillna(10)
tip['magnesium'] = tip['magnesium'].fillna(100)
tip.head()
step 7.创建10以内的10个随机整数
import random
seven = np.random.randint(0,10,10)
seven

step 8.根据上面的随机数,作为行索引,选取alcohol列,赋值为NaN
tip.iloc[seven,0]=np.nan
tip.head()
step 9.统计缺失值得个数
tip.isnull().sum()

Step 10.删除包含缺失值得行
tip.dropna()

Step 11. 让索引重新从0开始
a = list(tip.index)
b = list(range(len(a)))
c = dict(zip(a,b))
tip.rename(index=c)# 映射操作

pandas-缺失值处理的更多相关文章
- pandas缺失值处理
1.检查缺失值 为了更容易地检测缺失值(以及跨越不同的数组dtype),Pandas提供了isnull()和notnull()函数,它们也是Series和DataFrame对象的方法 - 示例1 im ...
- Python数据分析(二)pandas缺失值处理
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e' ...
- Python—关于Pandas缺失值问题(国内唯一)
获取文中的CSV文件用于代码编程以及文章首发地址,请点击下方超链接 获取CSV,用于编程调试请点这 在本文中,我们将使用Python的Pandas库逐步完成许多不同的数据清理任务.具体而言,我们将重点 ...
- Pandas系列(六)-时间序列详解
内容目录 1. 基础概述 2. 转换时间戳 3. 生成时间戳范围 4. DatetimeIndex 5. DateOffset对象 6. 与时间序列相关的方法 6.1 移动 6.2 频率转换 6.3 ...
- Pandas 时间序列
# 导入相关库 import numpy as np import pandas as pd 在做金融领域方面的分析时,经常会对时间进行一系列的处理.Pandas 内部自带了很多关于时间序列相关的工具 ...
- Python 基础(五)
pandas缺失值处理 import pandas as pd importrandom df01 = pd.DataFrame(np.random.randint(1,9),size = (4,4) ...
- Pandas系列(三)-缺失值处理
内容目录 1. 什么是缺失值 2. 丢弃缺失值 3. 填充缺失值 4. 替换缺失值 5. 使用其他对象填充 数据准备 import pandas as pd import numpy as np in ...
- 【学习】数据处理基础知识(缺失值处理)【pandas】
缺失数据(missing data)大部分数据分析应用中非常常见.pd设计目标之一就是让缺失数据的处理任务尽量轻松. pd 使用浮点值NaN(Not a Number) 表示浮点和非浮点数组中的缺失数 ...
- Python Pandas找到缺失值的位置
python pandas判断缺失值一般采用 isnull(),然而生成的却是所有数据的true/false矩阵,对于庞大的数据dataframe,很难一眼看出来哪个数据缺失,一共有多少个缺失数据,缺 ...
- pandas判断缺失值的办法
参考这篇文章: https://blog.csdn.net/u012387178/article/details/52571725 python pandas判断缺失值一般采用 isnull(),然而 ...
随机推荐
- Go 变量(var) & 常量(const)
变量 声明变量格式: var var_name var_type 变量在声明时会自动初始化: 数字: 0 string: "" bool: false 引用类型: nil 结构体: ...
- ClickHouse
ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告 1 安装前的准备1.1 Cent ...
- Paper | Adaptive Computation Time for Recurrent Neural Networks
目录 1. 网络资源 2. 简介 3. 自适应运算时间 3.1 有限运算时间 3.2 误差梯度 1. 网络资源 这篇文章的写作太随意了,读起来不是很好懂(掺杂了过多的技术细节).因此有作者介绍会更好. ...
- 第04组 Beta冲刺(5/5)
队名:new game 组长博客 作业博客 组员情况 鲍子涵(队长) 过去两天完成了哪些任务 动画优化 接下来的计划 等待答辩 还剩下哪些任务 让游戏本体运行 遇到了哪些困难 时间太少了 有哪些收获和 ...
- 百度开源的分布式唯一ID生成器UidGenerator,解决了时钟回拨问题
UidGenerator是百度开源的Java语言实现,基于Snowflake算法的唯一ID生成器.而且,它非常适合虚拟环境,比如:Docker.另外,它通过消费未来时间克服了雪花算法的并发限制.Uid ...
- Python的定时器与线程池
定时器执行循环任务: 知识储备 Timer(interval, function, args=None, kwargs=None) interval ===> 时间间隔 单位为s functio ...
- 推荐 | 中文文本标注工具Chinese-Annotator(转载)
自然语言处理的大部分任务是监督学习问题.序列标注问题如中文分词.命名实体识别,分类问题如关系识别.情感分析.意图分析等,均需要标注数据进行模型训练.深度学习大行其道的今天,基于深度学习的 NLP 模型 ...
- operator ->重载是怎么做到的?
https://stackoverflow.com/questions/8777845/overloading-member-access-operators-c struct client { in ...
- Elasticsearch 6.x版本全文检索学习之倒排索引与分词、Mapping 设置
Beats,Logstash负责数据收集与处理.相当于ETL(Extract Transform Load).Elasticsearch负责数据存储.查询.分析.Kibana负责数据探索与可视化分析. ...
- Redisson实现分布式锁(3)—项目落地实现
Redisson实现分布式锁(3)-项目落地实现 有关Redisson实现分布式锁前面写了两篇博客作为该项目落地的铺垫. 1.Redisson实现分布式锁(1)---原理 2.Redisson实现分布 ...