SQL数据同步到ElasticSearch(三)- 使用Logstash+LastModifyTime同步数据
在系列开篇,我提到了四种将SQL SERVER数据同步到ES中的方案,本文将采用最简单的一种方案,即使用LastModifyTime来追踪DB中在最近一段时间发生了变更的数据。
安装Java
安装部分的官方文档在这里:https://www.elastic.co/guide/en/logstash/current/installing-logstash.html
可以直接查看官方文档。
我这里使用的还是之前文章中所述的CentOS来进行安装。
首先需要安装Java(万物源于Java)
输入命令找到的OpenJDK 1.8.X版本(截止我尝试时,在Java11上会有问题):
yum search java | grep -i --color JDK
使用Yum进行安装:
yum install java-1.8.0-openjdk
配置环境变量JAVA_HOME、CLASSPATH、PATH。
打开/etc/profile文件:
vi /etc/profile
将下面几行代码粘贴到该文件的最后:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存并关闭,然后执行下列命令让设置立即生效。
source /etc/profile
可以输入下面的命令查看是否已生效:
java –-version
echo $JAVA_HOME
echo $CLASSPATH
echo $PATH
安装LogStash
首先注册ELK官方的GPG-KEY:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
然后cd /etc/yum.repos.d/文件夹下,创建一个logstash.repo文件,并将下面一段内容粘贴到该文件中保存:
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
然后执行安装命令:
sudo yum install logstash
以上步骤可能比较慢,还有另外一种办法,就是通过下载来安装LogStash:
官方文档在这里:https://www.elastic.co/cn/downloads/logstash
首先在上面的链接中下载LogStash的tar.gz包,这个过程有可能也很慢,我的解决方案是在自己机器上使用迅雷进行下载,完事儿Copy到Linux服务器中。
下载完成后,执行解压操作:
sudo tar -xvf logstash-7.2.0.tar.gz
解压完成后,进入解压后的logstash-7.2.0文件夹。
接着我们安装Logstash-input-jdbc插件:
bin/logstash-plugin install logstash-input-jdbc
下载SQL SERVER jbdc组件,这里我们从微软官网下载:https://docs.microsoft.com/en-us/sql/connect/jdbc/download-microsoft-jdbc-driver-for-sql-server?view=sql-server-2017 ,当然这个链接只是目前的,如果你在尝试时这个链接失效了,那就自行百度搜索吧~
下载完成后,解压到logstash下面的lib目录下,这里我自己为了方便,把微软默认给jdbc外面包的一层语言名称的文件夹给去掉了。
接着,我们到/config文件夹,新建一个logstash.conf文件,内容大概如下:
下面的每一个参数含义都可以在官方文档中找到:
- input->jdbc大括号中的参数文档:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html#plugins-inputs-jdbc-jdbc_fetch_size
- output->elasticsearch 大括号中的文档:https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
input {
jdbc {
jdbc_driver_library => "/usr/local/logstash-7.2.0/lib/mssql-jdbc-7.2.2/mssql-jdbc-7.2.2.jre8.jar" // 这里请灵活应变,能找到我们上一步下载的jdbc jar包即可
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver" // 这个名字是固定的
jdbc_connection_string => "jdbc:sqlserver: //数据库ServerIP:1433;databaseName=数据库名;"
jdbc_user => "数据库账号"
jdbc_password => "数据库密码"
schedule => "* * * * *" // Corn 表达式,请自行百度写法
jdbc_default_timezone => "Asia/Shanghai"
jdbc_page_size => "" // 每一批传输的数量
record_last_run => "true" //是否保存状态
use_column_value => "true" //设置为时true,使用定义的 tracking_column值作为:sql_last_value。设置为时false,:sql_last_value反映上次执行查询的时间。
tracking_column => "LastModificationTime" //配合use_column_value使用
last_run_metadata_path => "/usr/opt/logstash/config/last_id" //记录:sql_last_value的文件
lowercase_column_names => "false" //将DB中的列名自动转换为小写
tracking_column_type => "timestamp" //tracking_column的数据类型,只能是numberic和timestamp
clean_run => "false" //是否应保留先前的运行状态,其实我也不知道这个字段干啥用的~~
statement => "SELECT * FROM 表 WITH(NOLOCK) WHERE LastModificationTime > :sql_last_value" //从DB中抓数据的SQL脚本
}
}
output {
elasticsearch {
index => "test" //ES集群的索引名称
document_id => "%{Id}" //Id是表里面的主键,为了拿这个主键在ES中生成document ID
hosts => ["http://192.168.154.135:9200"]// ES集群的地址
}
}
上面的被注释搞的乱糟糟的,给你们一个可以复制的版本吧:
input {
jdbc {
jdbc_driver_library => "/usr/local/logstash-7.2.0/lib/mssql-jdbc-7.2.2/mssql-jdbc-7.2.2.jre8.jar"
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
jdbc_connection_string => "jdbc:sqlserver://SERVER_IP:1433;databaseName=DBName;"
jdbc_user => "xxx"
jdbc_password => "password"
schedule => "* * * * *"
jdbc_default_timezone => "Asia/Shanghai"
jdbc_page_size => "50000"
record_last_run => "true"
use_column_value => "true"
tracking_column => "LastModificationTime"
last_run_metadata_path => "/usr/local/logstash-7.2.0/config/last_id"
lowercase_column_names => "false"
tracking_column_type => "timestamp"
clean_run => "false"
statement => "SELECT * FROM xxx WITH(NOLOCK) WHERE LastModificationTime > :sql_last_value"
}
}
output {
elasticsearch {
index => "item"
document_id => "%{Id}"
hosts => ["http://ES集群IP:9200"]
}
}
Logstash 整体思路
回头来说一下这个LogStash的整体思路吧,其实我的理解,LogStash就是一个数据搬运工,他的搬运数据,分为三个大的阶段:
- 读取数据(input)
- 过滤数据(filter)
- 输出数据(output)
对应的官方文档:https://www.elastic.co/guide/en/logstash/current/pipeline.html
而这每一个阶段,都是通过一些插件来实现的,比如在上述的配置文件中,我们有:
- 读取数据即input部分,这部分由于我们是需要从数据库读取数据,所以使用了一个可以执行SQL语句的jdbc-input插件,这里如果我们的数据源是其他的部分,就需要使用其他的一些插件来实现。
- 也有输出数据部分,这部分我们是将数据写入到ElasticSearch,所以我们使用了一个elasticsearch-output插件。这里也可以将数据写入到kafka等其他的一些产品中,也是需要一些插件即可搞定。
- 可以发现我们上面的部分没有涉及到filter插件,其实如果我们想对数据做一些过滤、规范化处理等,都可以使用filter插件来进行处理,具体的还需要进一步去探索啦~
执行数据同步
剩下的部分就简单了,切换目录到logstash的目录下,执行命令:
bin/logstash -f config/logstash.conf
最后执行的效果图大概如下:
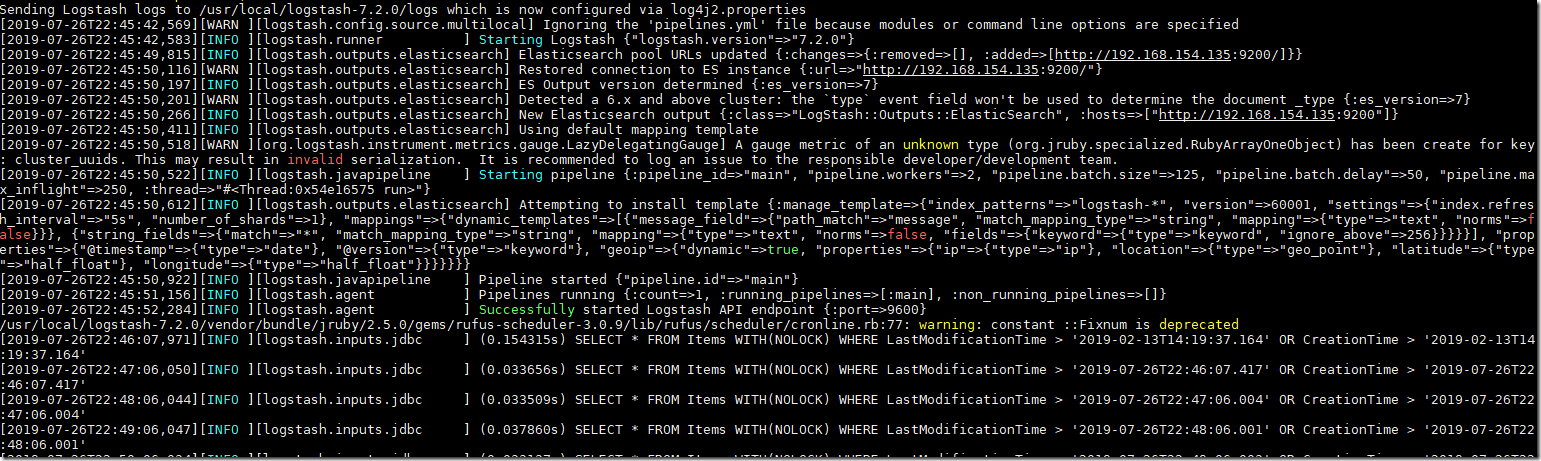
可以使用Elasticsearch-Head等插件来查看是否同步正常:
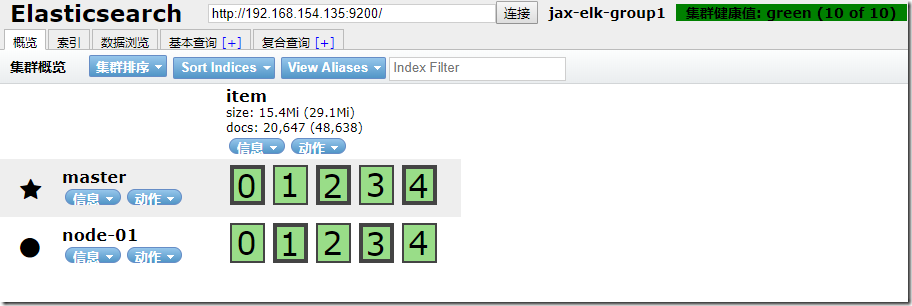
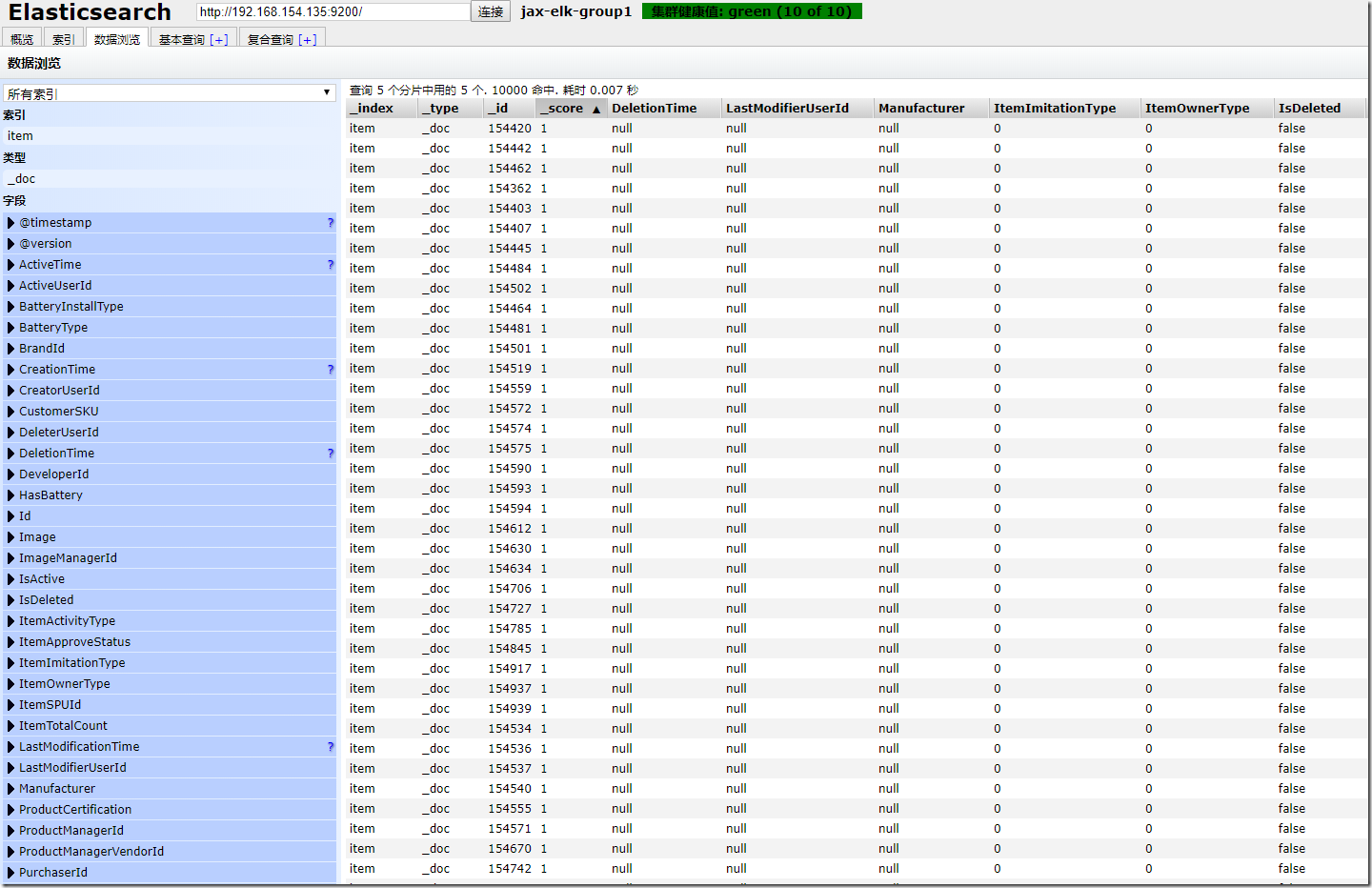
大概就是这样啦,后续我这边会继续尝试使用其他方式来进行数据同步,欢迎大家关注~
SQL数据同步到ElasticSearch(三)- 使用Logstash+LastModifyTime同步数据的更多相关文章
- 一、JDBC的概述 二、通过JDBC实现对数据的CRUD操作 三、封装JDBC访问数据的工具类 四、通过JDBC实现登陆和注册 五、防止SQL注入
一.JDBC的概述###<1>概念 JDBC:java database connection ,java数据库连接技术 是java内部提供的一套操作数据库的接口(面向接口编程),实现对数 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第三篇:logstash_output_kafka:Mysql同步Kafka深入详解
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484411&idx=1&sn=1f5a371 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第二篇:canal 实现Mysql到Elasticsearch实时增量同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484377&idx=1&sn=199bc88 ...
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第五篇:logstash-input-jdbc实现mysql 与elasticsearch实时同步深入详解
文章转载自: https://blog.csdn.net/laoyang360/article/details/51747266 引言: elasticsearch 的出现使得我们的存储.检索数据更快 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第一篇:Debezium实现Mysql到Elasticsearch高效实时同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484358&idx=1&sn=3a78347 ...
- ElasticSearch(1)---Mysql同步数据到ElSearch
ElasticSearch同步Mysql 先讲项目需求:对于资讯模块添加搜索功能 这个搜索功能我就是采用ElasticSearch实现的,功能刚实现完,所以写这篇博客做个记录,让自己在记录下整个步骤和 ...
- 基于nodejs将mongodb的数据实时同步到elasticsearch
一.前言 因公司需要选用elasticsearch做全文检索,持久化存储选用的是mongodb,但是希望mongodb里面的数据发生改变可以实时同步到elasticsearch上,一开始主要使用ela ...
- asp.net core microservices 架构之分布式自动计算(三)-kafka日志同步至elasticsearch和kibana展示
一 kafka consumer准备 前面的章节进行了分布式job的自动计算的概念讲解以及实践.上次分布式日志说过日志写进kafka,是需要进行处理,以便合理的进行展示,分布式日志的量和我们对日志的重 ...
随机推荐
- 测试链接服务器sql 语句
sp_addlinkedsrvlogin 创建或更新本地 Microsoft® SQL Server™ 实例上的登录与链接服务器上远程登录之间的映射. 语法 sp_addlinkedsrvlogin ...
- canvas的进阶 - 学习利用canvas做一个炫酷的倒计时功能
先给大家贴一张图片,因为我不会上传视频( ̄□ ̄||) ,请大家谅解了~ 如果有知道怎么上传视频的大神还请指点指点 ^_^ ~ 然后看一下代码: html部分 : <!DOCTYPE html ...
- 远程控制卡配置和RAID基本知识
一.远程控制卡配置(戴尔R710)ctrl+eLAN Parameters ==>>远程连接IP地址配置LAN User Configuration ==>>远程连接账号密码配 ...
- 继承Comparable接口来实现排序
1.java代码里进行排序(若sql能排序,就不要用代码排序) 可以继承Comparable接口来实现,若是在类中,可以声明Comparator对象,来进行比较 List<Map> map ...
- 第六章 Fisco Bcos 多服务器分布式部署
想了解相关区块链开发,技术提问,请加QQ群:538327407 前提概要 前面几章,我们通过单机部署,在单台服务器上搭建四个节点,完成Fisco Bcos 底层搭建,并完成相关合约开发.sdk 开发. ...
- OSI参考模型---网络基础篇(1)
什么是网络 网络就是将分布在不同地理位置,具有独立功能的终端(一切联网的设备都叫终端:例如电脑,手机,智能家电等等联网的设备),通过通信线路(双绞线.光纤.电话线等等)和通信设备(例如:交换机.路由器 ...
- 使用SpringSecurity搭建授权认证服务(1) -- 基本demo认证原理
使用SpringSecurity搭建授权认证服务(1) -- 基本demo 登录认证是做后台开发的最基本的能力,初学就知道一个interceptor或者filter拦截所有请求,然后判断参数是否合理, ...
- Codeforces Gym101246J:Buoys(三分搜索)
http://codeforces.com/gym/101246/problem/J 题意:给出n个点坐标,要使这些点间距相同的话,就要移动这些点,问最少的需要的移动距离是多少,并输出移动后的坐标. ...
- 如何实现LRU算法?
1.什么是LRU算法? LRU是一种缓存淘汰机制策略. 计算机的缓存容量有限,如果缓存满了就要删除一些内容,给新的内容腾位置.但是要删除哪些内容呢?我们肯定希望删掉那些没有用的缓存,而把有用的数据继续 ...
- MYSQL语句强化练习
之前发现自己写sql不怎么得心应手,总是百度零零散散的学习一下,所以在空闲的时候自己就专门找一下mysql的强化题敲一下练习一下,简要记录一下,sql写着写着就会越来越熟练,总之要自己加油! 表结构 ...