SQL数据同步到ElasticSearch(三)- 使用Logstash+LastModifyTime同步数据
在系列开篇,我提到了四种将SQL SERVER数据同步到ES中的方案,本文将采用最简单的一种方案,即使用LastModifyTime来追踪DB中在最近一段时间发生了变更的数据。
安装Java
安装部分的官方文档在这里:https://www.elastic.co/guide/en/logstash/current/installing-logstash.html
可以直接查看官方文档。
我这里使用的还是之前文章中所述的CentOS来进行安装。
首先需要安装Java(万物源于Java)
输入命令找到的OpenJDK 1.8.X版本(截止我尝试时,在Java11上会有问题):
yum search java | grep -i --color JDK
使用Yum进行安装:
yum install java-1.8.0-openjdk
配置环境变量JAVA_HOME、CLASSPATH、PATH。
打开/etc/profile文件:
vi /etc/profile
将下面几行代码粘贴到该文件的最后:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存并关闭,然后执行下列命令让设置立即生效。
source /etc/profile
可以输入下面的命令查看是否已生效:
java –-version
echo $JAVA_HOME
echo $CLASSPATH
echo $PATH
安装LogStash
首先注册ELK官方的GPG-KEY:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
然后cd /etc/yum.repos.d/文件夹下,创建一个logstash.repo文件,并将下面一段内容粘贴到该文件中保存:
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
然后执行安装命令:
sudo yum install logstash
以上步骤可能比较慢,还有另外一种办法,就是通过下载来安装LogStash:
官方文档在这里:https://www.elastic.co/cn/downloads/logstash
首先在上面的链接中下载LogStash的tar.gz包,这个过程有可能也很慢,我的解决方案是在自己机器上使用迅雷进行下载,完事儿Copy到Linux服务器中。
下载完成后,执行解压操作:
sudo tar -xvf logstash-7.2.0.tar.gz
解压完成后,进入解压后的logstash-7.2.0文件夹。
接着我们安装Logstash-input-jdbc插件:
bin/logstash-plugin install logstash-input-jdbc
下载SQL SERVER jbdc组件,这里我们从微软官网下载:https://docs.microsoft.com/en-us/sql/connect/jdbc/download-microsoft-jdbc-driver-for-sql-server?view=sql-server-2017 ,当然这个链接只是目前的,如果你在尝试时这个链接失效了,那就自行百度搜索吧~
下载完成后,解压到logstash下面的lib目录下,这里我自己为了方便,把微软默认给jdbc外面包的一层语言名称的文件夹给去掉了。
接着,我们到/config文件夹,新建一个logstash.conf文件,内容大概如下:
下面的每一个参数含义都可以在官方文档中找到:
- input->jdbc大括号中的参数文档:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html#plugins-inputs-jdbc-jdbc_fetch_size
- output->elasticsearch 大括号中的文档:https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
input {
jdbc {
jdbc_driver_library => "/usr/local/logstash-7.2.0/lib/mssql-jdbc-7.2.2/mssql-jdbc-7.2.2.jre8.jar" // 这里请灵活应变,能找到我们上一步下载的jdbc jar包即可
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver" // 这个名字是固定的
jdbc_connection_string => "jdbc:sqlserver: //数据库ServerIP:1433;databaseName=数据库名;"
jdbc_user => "数据库账号"
jdbc_password => "数据库密码"
schedule => "* * * * *" // Corn 表达式,请自行百度写法
jdbc_default_timezone => "Asia/Shanghai"
jdbc_page_size => "" // 每一批传输的数量
record_last_run => "true" //是否保存状态
use_column_value => "true" //设置为时true,使用定义的 tracking_column值作为:sql_last_value。设置为时false,:sql_last_value反映上次执行查询的时间。
tracking_column => "LastModificationTime" //配合use_column_value使用
last_run_metadata_path => "/usr/opt/logstash/config/last_id" //记录:sql_last_value的文件
lowercase_column_names => "false" //将DB中的列名自动转换为小写
tracking_column_type => "timestamp" //tracking_column的数据类型,只能是numberic和timestamp
clean_run => "false" //是否应保留先前的运行状态,其实我也不知道这个字段干啥用的~~
statement => "SELECT * FROM 表 WITH(NOLOCK) WHERE LastModificationTime > :sql_last_value" //从DB中抓数据的SQL脚本
}
}
output {
elasticsearch {
index => "test" //ES集群的索引名称
document_id => "%{Id}" //Id是表里面的主键,为了拿这个主键在ES中生成document ID
hosts => ["http://192.168.154.135:9200"]// ES集群的地址
}
}
上面的被注释搞的乱糟糟的,给你们一个可以复制的版本吧:
input {
jdbc {
jdbc_driver_library => "/usr/local/logstash-7.2.0/lib/mssql-jdbc-7.2.2/mssql-jdbc-7.2.2.jre8.jar"
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
jdbc_connection_string => "jdbc:sqlserver://SERVER_IP:1433;databaseName=DBName;"
jdbc_user => "xxx"
jdbc_password => "password"
schedule => "* * * * *"
jdbc_default_timezone => "Asia/Shanghai"
jdbc_page_size => "50000"
record_last_run => "true"
use_column_value => "true"
tracking_column => "LastModificationTime"
last_run_metadata_path => "/usr/local/logstash-7.2.0/config/last_id"
lowercase_column_names => "false"
tracking_column_type => "timestamp"
clean_run => "false"
statement => "SELECT * FROM xxx WITH(NOLOCK) WHERE LastModificationTime > :sql_last_value"
}
}
output {
elasticsearch {
index => "item"
document_id => "%{Id}"
hosts => ["http://ES集群IP:9200"]
}
}
Logstash 整体思路
回头来说一下这个LogStash的整体思路吧,其实我的理解,LogStash就是一个数据搬运工,他的搬运数据,分为三个大的阶段:
- 读取数据(input)
- 过滤数据(filter)
- 输出数据(output)
对应的官方文档:https://www.elastic.co/guide/en/logstash/current/pipeline.html
而这每一个阶段,都是通过一些插件来实现的,比如在上述的配置文件中,我们有:
- 读取数据即input部分,这部分由于我们是需要从数据库读取数据,所以使用了一个可以执行SQL语句的jdbc-input插件,这里如果我们的数据源是其他的部分,就需要使用其他的一些插件来实现。
- 也有输出数据部分,这部分我们是将数据写入到ElasticSearch,所以我们使用了一个elasticsearch-output插件。这里也可以将数据写入到kafka等其他的一些产品中,也是需要一些插件即可搞定。
- 可以发现我们上面的部分没有涉及到filter插件,其实如果我们想对数据做一些过滤、规范化处理等,都可以使用filter插件来进行处理,具体的还需要进一步去探索啦~
执行数据同步
剩下的部分就简单了,切换目录到logstash的目录下,执行命令:
bin/logstash -f config/logstash.conf
最后执行的效果图大概如下:
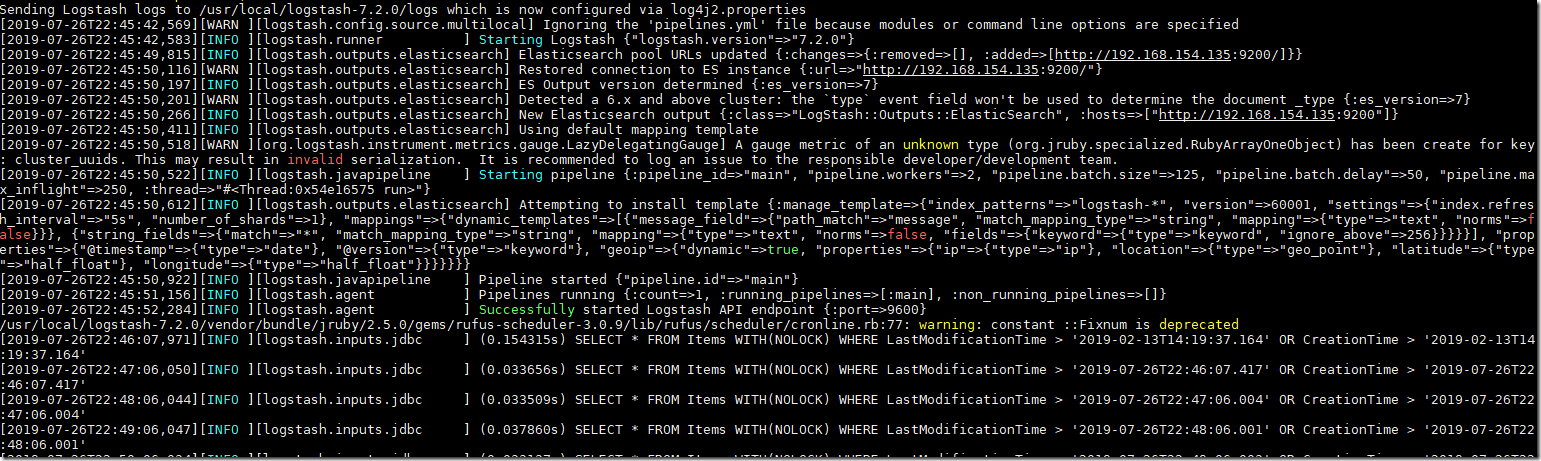
可以使用Elasticsearch-Head等插件来查看是否同步正常:
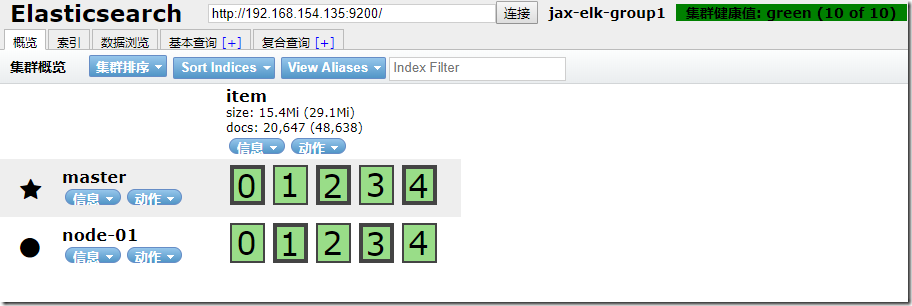
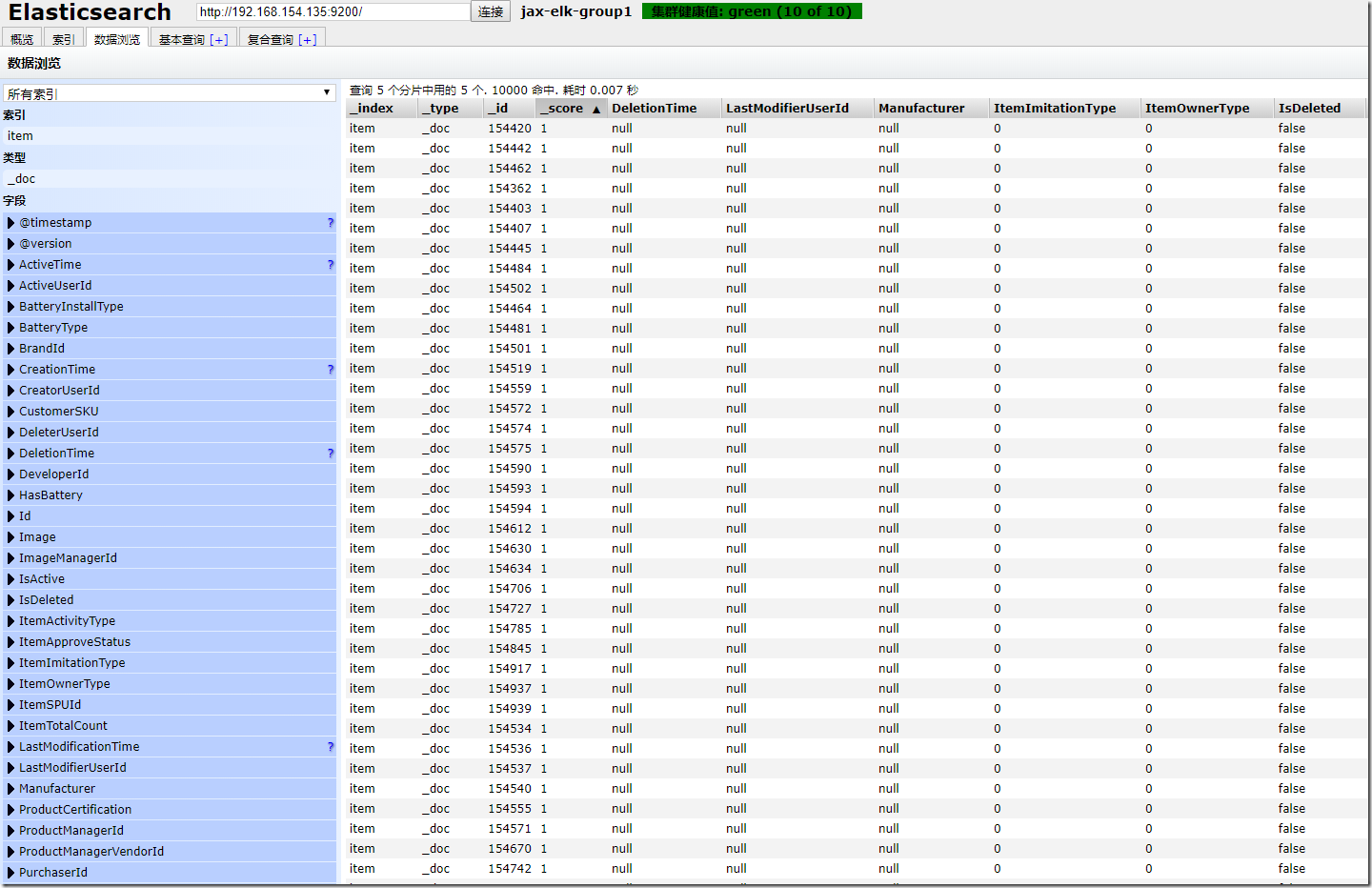
大概就是这样啦,后续我这边会继续尝试使用其他方式来进行数据同步,欢迎大家关注~
SQL数据同步到ElasticSearch(三)- 使用Logstash+LastModifyTime同步数据的更多相关文章
- 一、JDBC的概述 二、通过JDBC实现对数据的CRUD操作 三、封装JDBC访问数据的工具类 四、通过JDBC实现登陆和注册 五、防止SQL注入
一.JDBC的概述###<1>概念 JDBC:java database connection ,java数据库连接技术 是java内部提供的一套操作数据库的接口(面向接口编程),实现对数 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第三篇:logstash_output_kafka:Mysql同步Kafka深入详解
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484411&idx=1&sn=1f5a371 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第二篇:canal 实现Mysql到Elasticsearch实时增量同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484377&idx=1&sn=199bc88 ...
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第五篇:logstash-input-jdbc实现mysql 与elasticsearch实时同步深入详解
文章转载自: https://blog.csdn.net/laoyang360/article/details/51747266 引言: elasticsearch 的出现使得我们的存储.检索数据更快 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第一篇:Debezium实现Mysql到Elasticsearch高效实时同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484358&idx=1&sn=3a78347 ...
- ElasticSearch(1)---Mysql同步数据到ElSearch
ElasticSearch同步Mysql 先讲项目需求:对于资讯模块添加搜索功能 这个搜索功能我就是采用ElasticSearch实现的,功能刚实现完,所以写这篇博客做个记录,让自己在记录下整个步骤和 ...
- 基于nodejs将mongodb的数据实时同步到elasticsearch
一.前言 因公司需要选用elasticsearch做全文检索,持久化存储选用的是mongodb,但是希望mongodb里面的数据发生改变可以实时同步到elasticsearch上,一开始主要使用ela ...
- asp.net core microservices 架构之分布式自动计算(三)-kafka日志同步至elasticsearch和kibana展示
一 kafka consumer准备 前面的章节进行了分布式job的自动计算的概念讲解以及实践.上次分布式日志说过日志写进kafka,是需要进行处理,以便合理的进行展示,分布式日志的量和我们对日志的重 ...
随机推荐
- appium入门篇之desired capabilities(2)
目录 1.appium工作原理 desired capabilities 2.准备工作 3.第一个appium脚本 获取包名和启动的activity 编写脚本 运行结果 1.appium工作原理 启动 ...
- vuex中使用对象展开运算符
使用场景 当需要进行vuex进行数据状态管理的时候,会使用到mapGetters,mapState,还有自身的计算属性的时候,这个时候就会用到这个了! 1.首先需要安装 npm install bab ...
- (1)Linux文件系统的目录组成
记忆秘诀:BBDEH OPRLM TLSUV 宝贝的恩惠 欧派入联盟 偷了suv,19 目录 英文释义 简写 详解 1 / 根目录 整个文件系统的唯一根目录 2 /bin Binary 普通命 ...
- python统计字符串里每个字符的次数
方法一: 推导式 dd="ewq4aewtaSDDSFDTFDSWQrtewtyufashas" print {i:dd.count(i) for i in dd} 方法二: co ...
- Ruby中的数值
数值类型 Ruby中所有数值都是Numeric类的子类对象,数值都是不可变对象. 数值类型的继承关系如下: Integer是整数,Float是浮点数类型,Rational是分数. 对于整数,要么是Fi ...
- BFS(一):广度优先搜索的基本思想
广度优先搜索BFS(Breadth First Search)也称为宽度优先搜索,它是一种先生成的结点先扩展的策略. 在广度优先搜索算法中,解答树上结点的扩展是按它们在树中的层次进行的.首先生成第一层 ...
- js深入(四)万脸懵圈的this指向
作为一个js菜鸡的我而言,在之前讲到过那么多的js链式查找机制,比如说原型链,作用域链等等,想当然的把这个机制带入到了this指向上边,结果就是这个this指向指的我万脸懵逼(标题换字了,担心被河蟹) ...
- java获取config下文件
private static final String keystore="keystore.jks"; InputStream is=Thread.currentThread() ...
- 浅谈 JavaScript 中 Array 类型的方法使用
前言:Array 类型是 JavaScript 中除了 Object 类型以外最常用的类型. 一.创建数组 JavaScript 中的数组与其他语言中的数组有着很大的区别.例如Java.PHP等语言中 ...
- django基础知识之csrf:
csrf 全称Cross Site Request Forgery,跨站请求伪造 某些恶意网站上包含链接.表单按钮或者JavaScript,它们会利用登录过的用户在浏览器中的认证信息试图在你的网站上完 ...