ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
今日内容
ORM执行SQL语句
有时候ROM的操作效率可能偏低 我们是可以自己编写sql的
方式1:
models.User.objects.raw('select * from app01_user;')
方式2:
from django.db import connection
cursor = connection.cursor()
cursor.execute('select name from app01_user;')
print(cursor.fetchall())
神奇的双下划线查询
只要是queryset对象就可以无限制的点queryset对象的方法
queryset.filter().values().filter().values_list().filter()...
大于 小于
__gt 大于
__lt 小于
大于等于 小于等于
__gte 大于等于
__lte 小于等于
或1 或2 或3
__in(1,2,3)
在1-10范围内
__range(1,10)
是否含有'j'
__contains='j' #区分大小写
__icontains='j' #不区分大小写
查询注册年份
register_time_year = 2022
'''针对django框架时区问题 是需要配置文件中修改的 后续bbs讲解'''
ORM外键字段的创建
mysql外键关系
一对多
外键字段建在多的一方
多对多
外键字段统一建在第三张表
一对一
任何一方都可以 但是建议建在查询频率高的表中
1.创建四张表
书籍表、出版社表、作者表、作者详情
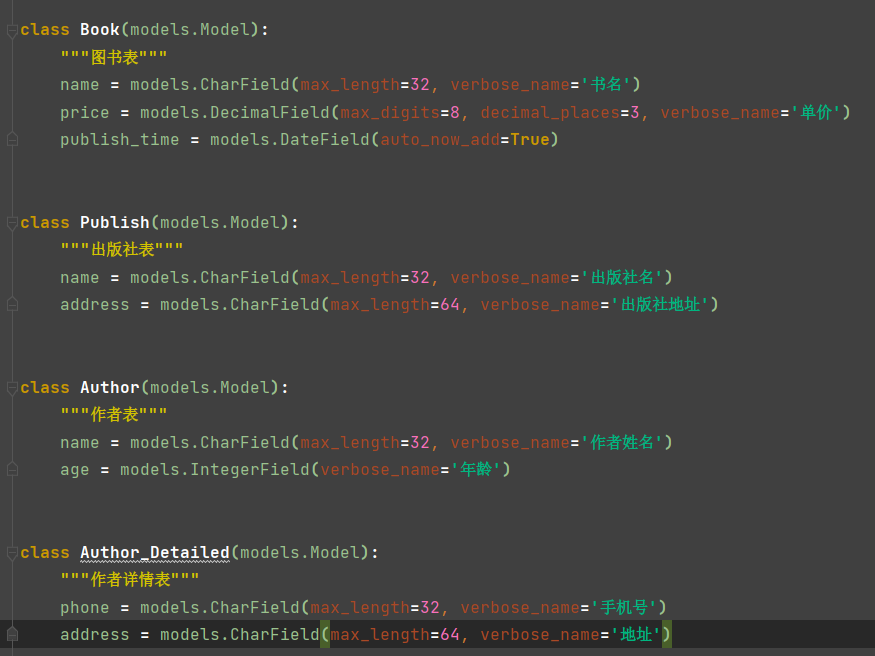
2.确定外键关系
一对多 ORM与MYSQL一致 外键字段建在多的一方
多对多 ORM比MYSQL有变化
1.外键字段可以直接建在某张表中(查询频率较高的)
内部会自动帮你创建第三张关系表
2.自己创建第三张关系表 并创建外键字段
详情后续讲解
一对一 OPM与MYSQL一致 外键字段建在查询较高的一方
3.ORM外键字段的创建
针对一对多和一对一同步到表中会自动加_id的后缀
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
注意:django1.x版本默认外键字段都是级联更新级联删除的 django2.x及以上版本需要自己声明
针对多对多 不会再表中有展示 而是创建第三张表
authors = models.ManyToMangField(to='Author')
外键字段相关操作
针对一对多添加关系
#插入数据可以直接写表中的实际字段
models.Book.objects.create(name='火浒传',price=6.66,publish_id=1)
#插入数据可以直接表中的类中字段名
publish_obj = models.Publish.objects.filter(pk=1).first()
#先获取到对象
models.Book.objects.create(name='四国演义',price=3.33,publish=publish_obj)
#将获取到的对象插入
'''一对一与一对多 一致'''
即可以传数字也可以传对象
针对多对多添加关系
book_obj = models.Book.objects.filter(pk=12).first()
#获取书籍对象
book_obj.authors.add(3)
book_obj.authors.add(3,2)
#在第三张表中给数据对象绑定作者 支持一个或多个 (作者主键)
book_obj =
models.Book.objects.filter(pk=1).first()
author_obj=
models.Author.objects.filter(pk=2).first()
author_obj2=
models.Author.objects.filter(pk=1).first()
book_obj.author.addd(author_obj2)
#(作者对象)
修改关系
book_obj =
models.Book.objects.filter(pk=10).first()
book_obj.authors.set((2,1))
book_obj.authors.set([2,])
#直接传外键 元组要加号
book_obj =
models.Book.objects.filter(pk=10).first()
author_obj=
models.Author.objects.filter(pk=1).first()
book_obj.authors.set((author_obj))
#直接传对象
删除关系
book_obj =
models.Book.objects.filter(pk=12).first()
book_obj.authors.remove(2)
#移除这本书和2的绑定关系
book_obj =
models.Book.objects.filter(pk=12).first()
author_obj=
models.Author.objects.filter(pk=1).first()
book_obj.authors.remove((author_obj))
#直接传数据
book_obj.authors.clear()#把这本书的关系全部清掉
add()\remove() 多个位置参数(数字 对象)
set() 可迭代对象(元组 列表)数字 对象
clear() 清空当前数据对象的关系
ORM跨表查询
mysql跨表查询
子查询
分布操作:
将一条sql语句用括号括起来当作另外一条sql语句的条件
联表操作
先整合多张表之后基于单表查询即可
inner join 内连接
left join 左连接
right join 右连接
正反向查询
正向查询
由外键字段所在的表数据查询关联的表数据
有外键字段 去查别人
反向查询
没有外键字段的表数据查询关联的表数据
没有外键 去查别人
ps:正反向核心就看外键在不在当前的数据表中
ORM跨表查询口诀
正向查询按外键字段
反向查询按表名小写
基于对象的跨表查询
正向查询
1.查询主键为7的书籍对应的出版社名称
book_obj= models.Book.objects.filter(pk=7).first()
print(book_obj.publish.name)
2.查询主键为10的书籍对应的作者
book_obj = models.Book.objects.filter(pk=10).first()
print(book_obj.authors.all().values('name'))
3.查询joyce的电话号码 author_obj=models.Author.objects.filter(name='joyce').first()
print(author_obj.author_detail.phone)
反向查询
1.查询月月出版社出版的书籍名称
publish_obj = models.Publish.objects.filter(name='月月出版社').first()
print(publish_obj.book_set.all().values())
2.查询kevin写过的书
author_obj = models.Author.objects.filter(name='kevin').first()
print(author_obj.book_set.all().values('name'))
3.查询电话号码是33333333333的作者姓名
Author_Detailed_obj = models.Author_Detailed.objects.filter(phone=33333333333).first()
print(Author_Detailed_obj.author.name)
基于上下划线的跨表查询
1.查询主键为7的书籍对应的出版社名称 book_obj=models.Book.objects.filter(pk=7).values('publish__name')
print(book_obj)
2.查询主键为10的书籍对应的作者 book_obj=models.Book.objects.filter(pk=10).values('authors__name')
print(book_obj)
3.查询joyce的电话号码
author_obj=
models.Author.objects.filter(name='joyce').values('author_detail__phone')
print(author_obj)
4.查询月月出版社出版的书籍名称 publish_obj=models.Publish.objects.filter(name='月月出版社').values('book__name')
print(publish_obj)
5.查询kevin写过的书
author_obj = models.Author.objects.filter(name='kevin').values('book__name')
print(author_obj)
6.查询电话号码是33333333333的作者姓名
Author_Detailed_obj = models.Author_Detailed.objects.filter(phone=33333333333).values('author__name')
print(Author_Detailed_obj)
进阶操作
s.Publish.objects.filter(book__pk=7).values('name')
print(res)
# 2.查询主键为10的书籍对应的作者
res = models.Author.objects.filter(book__pk=10).values('name')
print(res)
# 3.查询joyce的电话号码
res = models.Author_Detailed.objects.filter(author__name='joyce').values('phone')
print(res)
# 1.查询月月出版社出版的书籍名称
res = models.Book.objects.filter(publish__name='月月出版社').values('name')
print(res)
# 2.查询kevin写过的书
res = models.Book.objects.filter(authors__name='kevin').values('name')
print(res)
# 3.查询电话号码是33333333333的作者姓名
res = models.Author.objects.filter(author_detail__phone=33333333333).values('name')
print(res)
ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作的更多相关文章
- 12月15日内容总结——ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
目录 一.ORM执行SQL语句 二.神奇的双下划线查询 三.ORM外键字段的创建 复习MySQL外键关系 外键字段的创建 1.创建基础表(书籍表.出版社表.作者表.作者详情) 2.确定外键关系 3.O ...
- Django之ORM执行原生sql语句
django中的ORM提供的操作功能有限,在模型提供的查询API不能满足实际工作需要时,可以在ORM中直接执行原生sql语句. Django 提供两种方法使用原生SQL进行查询:一种是使用raw()方 ...
- ORM执行原生SQL语句
# 1.connectionfrom django.db import connection, connections cursor = connection.cursor() # cursor = ...
- django系列5.4--ORM中执行原生SQL语句, Python脚本中调用django环境
ORM执行原生sql语句 在模型查询API不够用的情况下,我们还可以使用原始的SQL语句进行查询. Django 提供两种方法使用原始SQL进行查询:一种是使用raw()方法,进行原始SQL查询并返回 ...
- python 之 Django框架(orm单表查询、orm多表查询、聚合查询、分组查询、F查询、 Q查询、事务、Django ORM执行原生SQL)
12.329 orm单表查询 import os if __name__ == '__main__': # 指定当前py脚本需要加载的Django项目配置信息 os.environ.setdefaul ...
- orm分组,聚合查询,执行原生sql语句
from django.db.models import Avg from app01 import models annotate:(聚合查询) ret=models.Article.objects ...
- Django中的ORM相关操作:F查询,Q查询,事物,ORM执行原生SQL
一 F查询与Q查询: 1 . F查询: 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较.如果我们要对两个字段的值做比较,那该怎么做呢? Django 提供 F() 来做这样的 ...
- java:Hibernate框架3(使用Myeclipse逆向工程生成实体和配置信息,hql语句各种查询(使用hibernate执行原生SQL语句,占位符和命名参数,封装Vo查询多个属性,聚合函数,链接查询,命名查询),Criteria)
1.使用Myeclipse逆向工程生成实体和配置信息: 步骤1:配置MyEclipse Database Explorer: 步骤2:为项目添加hibernate的依赖: 此处打开后,点击next进入 ...
- Django的F查询和Q查询,事务,ORM执行原生SQL
F查询和Q查询,事务及其他 F查询和Q查询 F查询 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个我们自己设定的常量做比较.如果我们要对两个字段的值做比较,那该怎么做呢? Django ...
随机推荐
- 成功解决IDEA中建立新项目Maven会默认选择配置(图解详细说明)
文章目录 1.File-->Other Settings --> Settings for New Projects 2.选择自己的maven配置 3.效果展示(我这里省略建立新项目的过程 ...
- Debian安装WPS的方法
1.防止安装失败,请尽量重启电脑,关闭系统的软件商店,因为商店的权限可能会锁住pkg的配置文件,导致无法安装wps. 2.将原机残废的WPS卸载干净,卸载方法:手动或命令行操作. sudo apt r ...
- Mybatis 报错Mapper method 'xxx' has an unsupported return type
报错原因: 出现这种错误,说明sql语句执行成功,只是返回类型出了问题. 解决方法: insert.delete.update操作默认返回一个int类型的整数,将增删改的接口改成int或者void即可 ...
- Python基础部分:5、 python语法之变量与常量
目录 python语法之变量与常量 一.什么是变量与常量 1.什么是变量 2.什么是常量 二.变量的基本使用 1.代码中如何记录事物状态 2.变量使用的语法结构与底层原理 3.变量名的命名规范 4.变 ...
- WSL下的Ubuntu 18.04LTS配置软件源和系统更新
WSL下的Ubuntu 18.04LTS配置软件源和系统更新 设置系统语言为中文 # 安装中文支持 sudo apt-get install -y language-pack-zh-hans # 设置 ...
- phpexcel 小技巧
//设置填充的样式和背景色$objPHPExcel->getActiveSheet()->getStyle( 'A1:AU1')->getFill()->setFillType ...
- VS 生成后事件中自动修改文件名插入当前时间
目录 rename 指令 获取当前时间 将当前时间插入名字 rename 指令 VS 生成后事件中使用的是CMD 的语法 我们重命名使用的是Rename 简单用法如下: RENAME (REN) [d ...
- 总算给女盆友讲明白了,如何使用stream流的filter()操作
一.引言 在上一篇文章中<这么简单,还不会使用java8 stream流的map()方法吗?>分享了使用stream的map()方法,不知道小伙伴还有印象吗,先来回顾下要点,map()方法 ...
- 2022年Kubernetes CKA 认证真题解析完整版
第一题 RBAC授权问题权重: 4% 设置配置环境:[student@node-1] $ kubectl config use-context k8s Context为部署管道创建一个新的Cluste ...
- JavaFX入门笔记
JavaFX入门笔记 背景 Java选修课第四次实验 所需工具 IDEA JavaFX插件(需要Maven) JavaFX Scene Builder 参考资料 https://www.yiibai. ...