爬取百度页面代码写入到文件+web请求过程解析
一、爬取百度页面代码写入到文件
代码示例:
from urllib.request import urlopen #导入urlopen包 url="http://www.baidu.com" #需要爬取网页的网址
resp=urlopen(url)
with open("mybaidu.html",mode="w",encoding="utf-8") as f: #encoding="utf-8"防乱码
f.write(resp.read().decode())#将爬取到的代码写入到文件中,decode()用于解码,防止中文乱码
print("爬取完成!")
二、 web请求过程解析
1.服务器渲染:在服务器直接将数据和html整合在一起,特点为在html源代码中可以看到数据。
例:在百度中搜索“李白”,得到的页面及解析如下:
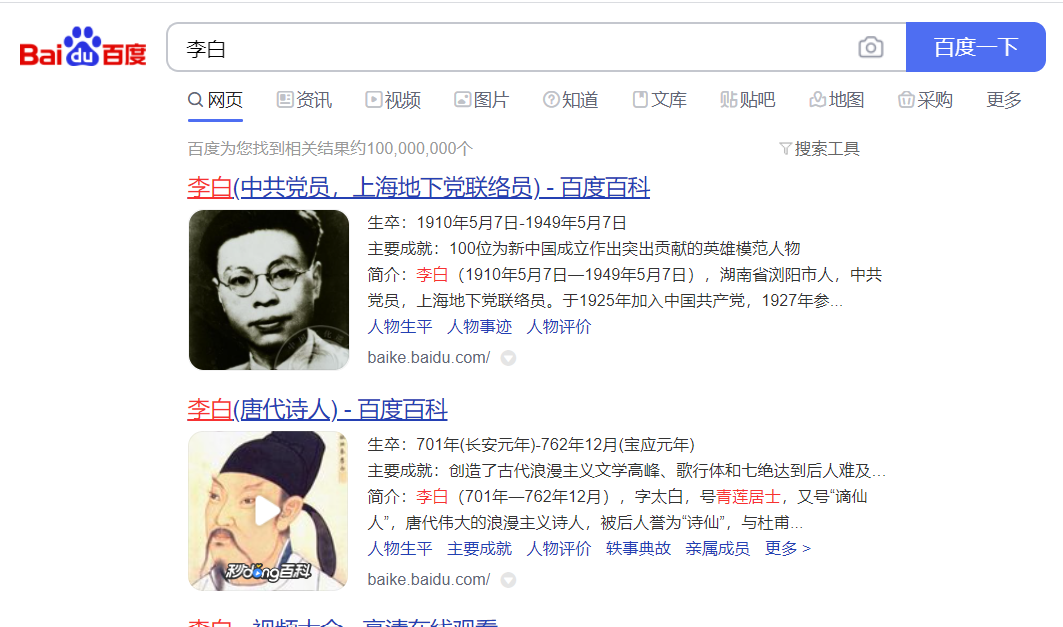

很明显在html源代码中可以看到数据。
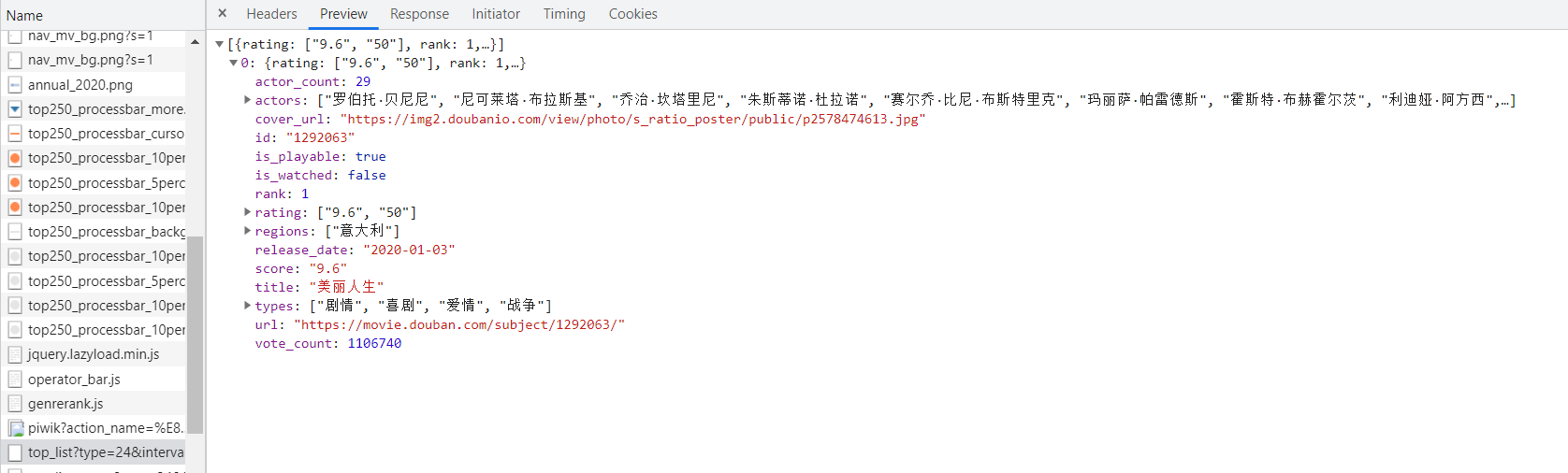
2.客户端渲染:客户端发送两次请求,第一次请求得到html代码,第二次得到数据,在客户端中将二者整合呈现给用户。
特点:在html源代码中无法看到数据
例:查看豆瓣分类排行榜页面,其预览中并没有展示数据,由此可见其源代码中没有数据。

在下面的请求中可以看到数据:
爬取百度页面代码写入到文件+web请求过程解析的更多相关文章
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- '/test.txt'; // 把抓取的代码写入该文件
将获得的代码直接写入某个文件 代码如下:<?php $urls = array( 'http://www.sina.com.cn/', 'http://www.sohu.com/', 'ht ...
- 假期学习【十一】Python爬取百度词条写入csv格式 python 2020.2.10
今天主要完成了根据爬取的txt文档,从百度分类从信息科学类爬取百度词条信息,并写入CSV格式文件. txt格式文件如图: 为自己爬取内容分词后的结果. 代码如下: import requests fr ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- python爬取百度贴吧帖子
最近偶尔学下爬虫,放上第二个demo吧 #-*- coding: utf-8 -*- import urllib import urllib2 import re #处理页面标签类 class Too ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
随机推荐
- C语言形参和实参的区别(非常详细)
如果把函数比喻成一台机器,那么参数就是原材料,返回值就是最终产品:从一定程度上讲,函数的作用就是根据不同的参数产生不同的返回值.这一节我们先来讲解C语言函数的参数,下一节再讲解C语言函数的返回值.C语 ...
- PCB常用低速、高速板材参数性能(2)
- 用纯RUST手撸一个开源流媒体服务(RTMP/HTTPFLV/HLS)XIU
作者工作目前在音视频流媒体行业,用了大概一年的业余时间学习Rust,并且实现了一个简单的音视频流媒体服务,虽然据说Rust已经连续多年被评为最受程序员喜欢的语言,但是在国内还是比较冷门,作者比较看好R ...
- 阿里云、腾讯云、CentOS下的MySQL的安装与配置详解
一. 安装 查看是否已安装 # 查看MySQL版本 mysql --version # 查看MySQL相关文件 whereis mysql 若已安装,卸载方法如下 # 卸载MySQL yum remo ...
- 用JS写一个计算器(兼容手机端)
先看成果:1.PC端2. 首先确立html,有哪些东西我们要知道.布局大概的样子在心里有个数 <!DOCTYPE html> <html> <head> <m ...
- 用 JWT 实现小程序本地用户标识
panda-chat-room 继上节「理解小程序 session」 ,本节我们以 jsonwebtoken 来实现小程序端的用户状态标识.如果你对小程序用户登录流程及 session 管理还有些疑惑 ...
- CCF201812-2小明放学
题目背景 汉东省政法大学附属中学所在的光明区最近实施了名为"智慧光明"的智慧城市项目.具体到交通领域,通过"智慧光明"终端,可以看到光明区所有红绿灯此时此刻的状 ...
- 单例设计模式(Singleton)
一.单例设计模式介绍 所谓类的单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例, 并且该类只提供一个取得其对象实例的方法(静态方法) 例如:Hibernate的Se ...
- windows下右键新建md文件
windows下右键新建md文件 打开注册表 win键+R打开运行对话框, 输入regedit, 打开注册表编辑器. 修改注册表 在磁盘的任意位置新建一个文件, 后缀名为reg, 并写入一下内容 [H ...
- LC-242
利用ASCII码构成哈希表来映射 和这题类似: https://leetcode-cn.com/problems/minimum-window-substring/solution/li-yong-a ...