[机器学习]-SVD奇异值分解的基本原理和运用
SVD奇异值分解:
SVD是一种可靠的正交矩阵分解法。可以把A矩阵分解成U,∑,VT三个矩阵相乘的形式。(Svd(A)=[U*∑*VT],A不必是方阵,U,VT必定是正交阵,S是对角阵<以奇异值为对角线,其他全为0>)
用途:
信息检索(LSA:隐性语义索引,LSA:隐性语义分析),分解后的奇异值代表了文章的主题或者概念,信息检索的时候同义词,或者说同一主题下的词会映射为同一主题,这样就可以提高搜索效率
数据压缩:通过奇异值分解,选择能量较大的前N个奇异值来代替所有的数据信息,这样可以降低噪声,节省空间。
推荐系统:主要是降噪,矩阵变换至低维空间,方便计算(目前没有意识到它对推荐精确度的提升有什么具体作用)。
原理:矩阵分解,矩阵变换,数据降维
基于协同过滤的推荐系统(相关知识):
相似度计算:A(a1,a2,a3),B(b1,b2,b3)
1.欧氏距离相似度:点到点的距离在多维空间的推广 ,||A-B||表示A-B的2范数。
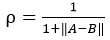 ,
,
2.皮尔逊相关系数:

3.余玄相似度:

SVD的矩阵空间变换:
1.奇异值分解
2.奇异值选择,数据矩阵重构:
协同过滤算法,就是在重构后的矩阵空间上做相似度计算。
下面就《机器学习实战》来看一下具体矩阵分解和奇异值选择的操作(后面会附上具体的代码,大家一看就懂,很多东西都被Python封装好了,直接调用):
原始数据data1:每一列代表一种商品,每一行代表一个用户,数据是用户对商品的评价
Data:(M*N)7*5

奇异值分解:
U:(M*M)7*7

∑:(M*N对角矩阵,前N*N是对角矩阵,对角线时奇异值,后M-N是0)7*5

VT:(N*N)5*5

奇异值选择:
∑=(e1,e2,e3...em)
从上图 分解后的∑可以看出前2个奇异值之和远大于后面的奇异值,所以说,前两个奇异值中代表的信息足以描述整个数据。我们可以计算前x个奇异值得平方和占所有奇异值的平方和的比例,如果大于90%,我们就选这x个奇异值重构矩阵(剩余的数据代表的可能是噪声,无用数据)

我们通过矩阵重构来看一下理论是否正确
矩阵重构:

U:(M*X)7*2

∑:(X*X)2*2,以前X个奇异值构建对角矩阵

VT:(x*n)2*5

A’:重构后的U*∑*VT

可以发现原始数据中非零的部分都完整的保存了下来,说明选择的奇异值几乎完整地保存了所有有用信息。其他部分都是近似为零的小数,将他们损失精度,强转成整形后就是0强转之后如下图:

原始数据Data:

可以看到相比较于原始数据出现了部分损失,这是由于强转后将损失信息放大所致,在浮点数情况下这些微小的损失被忽略掉了(个人理解)。
基于以下数据data2做商品推荐:行:用户,列:商品(由于上一个数据集维数较低已经用于展示了这个步骤中的操作,下面就直接放代码实现)

步骤:
1.进行矩阵奇异值分解
2.矩阵进行低维空间的映射 降维后的数据A’
降维后的数据A’
3.在低维空间做相似度计算,并进行估计评分
贴代码:(没有代码说个卵呀!,最后会放上源码)python(才开始用可能风格有点怪异),代码是机器学习实战的内容,注释也很多,不做多说了


Exp: 用户A,评价了1,2,3,4,5这5个商品中的1,2,3
用户B,评价了1,2,3,4,5这5个商品中的1,3,4
现在要给A做推荐4,5号商品(未评价过的才需要推荐),首先我们遍历A评价过得商品的每一列(在矩阵中代表其他用户对这个商品的评价),然后和指定的4号商品所在的列做相似度计算。
在这里就是1,2,3,列分别于第四列做相似度计算给出一个评分。然后1,2,3列再与第5列做相似度评分。最终我们比较4,5的估计评分值,谁大,我们就说,喜欢1,2,3号商品的用户可能也喜欢4号。
就以上的说明并没有用到SVD,我们再取数据的列的时候并不是从原矩阵中去取,而是从利用SVD降维后的矩阵中去取(这是唯一用到SVD的部分)。
根据评分推荐:

遍历所有未评分的商品,进行评分,然后排序取TOPN(这里选三个),输出的结果就是给这个用户推荐的商品。
基于SVD实现的数据压缩:
SVD数据压缩说白了就是奇异值分解后,

A可以近似的用U’*∑’*VT’表示A,原始的A需要M*N个存储空间,我们现在只需要存储U’,∑’,VT’三个矩阵在使用的时候做乘积就可以得到A,而且U’,∑’,VT’需要的空间M*X+X*X+X*N远小于M*N,这就实现了数据压缩。从M*N压缩到了M*X+X*X+X*N
Exp:对一个图像数据进行压缩:32*32的图像数据 总空间需要:32*32=1024
压缩前:

压缩后还原:可以发现有微小的差异

压缩后的三个矩阵:sigma(2),VT(2*32),U(32*2)总空间=130相比1024极大缩小了占有空间

源代码:(py2.7可直接运行)
# -*- coding:utf-8 -*-
# Filename: svd.py
# Author:Ljcx from numpy import* class Svd(object): def loadExData(self):
data = [[0, 0, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1],
[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 1, 0, 0]]
return data def loadExData2(self):
"""
列表示商品,行表示用户的评分
"""
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]] # 相似度计算:inA,inB为列向量还是行向量,基于我们需要计算相似的维度
def ecludSim(self, inA, inB):
"""norm()求范数
范数表示数值平方开方,inA-inB的范数 = inA和inB的欧氏距离
"""
return 1.0 / (1.0 + linalg.norm(inA - inB)) def pearsSim(self, inA, inB):
"""corrcoef()求皮尔逊相关系数 [-1,1]
皮尔逊相关系数:0.5+0.5*corrcoef()规范化到[0,1]
"""
if len(inA) < 3:
return 1.0
return 0.5 + 0.5 * corrcoef(inA, inB, rowvar=0)[0][1] def cosSim(self, inA, inB):
"""
余玄相似度:即两个向量的余玄夹角值[-1,1]
"""
num = float(inA.T * inB)
denom = linalg.norm(inA) * linalg.norm(inB)
return 0.5 + 0.5 * (num / denom) # 奇异值分解==》矩阵重构:可用于图像压缩
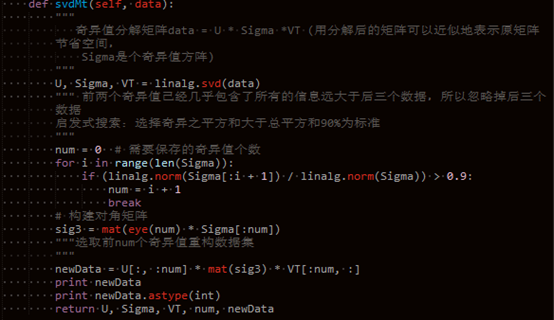
def svdMt(self, data):
"""
奇异值分解矩阵data = U * Sigma *VT (用分解后的矩阵可以近似地表示原矩阵
节省空间,
Sigma是个奇异值方阵)
"""
U, Sigma, VT = linalg.svd(data)
""" 前两个奇异值已经几乎包含了所有的信息远大于后三个数据,所以忽略掉后三个
数据
启发式搜索:选择奇异之平方和大于总平方和90%为标准
"""
num = 0 # 需要保存的奇异值个数
for i in range(len(Sigma)):
if (linalg.norm(Sigma[:i + 1]) / linalg.norm(Sigma)) > 0.9:
num = i + 1
break
# 构建对角矩阵
sig3 = mat(eye(num) * Sigma[:num])
"""选取前num个奇异值重构数据集
"""
newData = U[:, :num] * mat(sig3) * VT[:num, :]
print newData
print newData.astype(int)
return U, Sigma, VT, num, newData """
基于相似度的推荐引擎:
只需要对用户所购商品和其他商品做相似度计算,选取TOPn个作为推荐
基于SVD的推荐引擎:
先进行奇异值分解,选取前n个奇异值(能量之和大于90%,奇异之平方和大于总平方和
90%为标准),作为需要降维的维数,原数据往低维空间投影。Data.T*U[:,:n]*Sigma[:,:4]
寻找指定一个商品的所有评分x[,,,]和每一个商品的所有评分做相似度计算,相似度求和
""" # 相似度推荐
def standEst(self):
pass def svdEst(self, dataMat, xformedItems, user, simMeas, item):
"""计算相似度并计算评分
# dataMat:原始数据
# user:用户编号
# simMeas:相似度计算方法
# item:商品编号
# xformedItems:降维后的数据
"""
n = shape(dataMat)[1] # 获取列,多少个商品
simTotal = 0.0
ratSimTotal = 0.0
# 计算指定用户评价过的商品与其他所有用户的评价过的商品做相似度计算,来估计
# 指定的未评价商品item的评分
for j in range(n):
userRating = dataMat[user, j]
if userRating == 0 or j == item:
continue
similarity = simMeas(xformedItems[item, :].T, xformedItems[j, :].T)
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity # 相似度求和
ratSimTotal += similarity * userRating # 相似度乘以评分在求和
if simTotal == 0:
return 0
else:
return ratSimTotal / simTotal # 根据相似度对一个指定商品给一个评分 def recommend(self, dataMat, user, N=3, simMeas=cosSim, estMethod=svdEst):
"""
# 根据SVD空间评分推荐:寻找所有该用户未评分的商品,对每个商品进行评分估计()
"""
unratedItems = nonzero(dataMat[user, :].A == 0)[1] # findunrated items
if len(unratedItems) == 0:
return 'you rated everything'
U, Sigma, VT, num, newData = self.svdMt(dataMat)
sig = mat(eye(num) * Sigma[:num]) # 构建对角矩阵
xformedItems = dataMat.T * U[:, :num] * sig.I # 数据投影降维
print "----xform---"
print xformedItems
itemScores = []
for item in unratedItems:
estimatedScore = estMethod(
dataMat, xformedItems, user, simMeas, item) # 评分
itemScores.append((item, estimatedScore))
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N] def loadImageData(self):
"""
加载图像数据
"""
fp = open("image.txt", "r")
imageData = []
for line in fp.readlines():
lineData = []
for i in range(len(line) - 1):
lineData.append(int(line[i]))
imageData.append(lineData)
return mat(imageData) def imageCompress(self):
"""svd图像压缩 == 分解矩阵之后 选择几个重要的奇异值对U ,Sigma ,VT 进行切割,
切割后的矩阵的乘积仍可以表示原矩阵,我们只需存储这三个矩阵就可以在使用的时候
还原原矩阵了
"""
data = self.loadImageData()
self.printMat(data, 0.8) # 压缩前数据
print"---------------------------------------------------------"
U, Sigma, VT, num, newData = self.svdMt(data)
self.printMat(newData, 0.8) # 压缩后还原的数据
print Sigma
print "num:" + str(num)
print '前 %d 个奇异值的平方和达到了所有奇异值平方和的0.9以上则2个奇异值重构矩阵可表示原矩阵:' % (num)
U = U[:, :num]
Sigma = Sigma[:num]
VT = VT[:num, :]
print "U:" + str(shape(U))
print U
print "Sigma:" + str(shape(Sigma))
print Sigma
print "VT:" + str(shape(VT))
print VT
print "压缩前存储空间:", str(shape(data)[0] * shape(data)[1])
print "压缩后存储空间:", str(shape(U)[0] * shape(U)[1]
+ shape(Sigma)[0] * shape(Sigma)[0]
+ shape(VT)[0] * shape(VT)[1]) def printMat(self, inMat, thresh=0.8):
for i in range(32):
for k in range(32):
if float(inMat[i, k]) > thresh:
print 1,
else:
print 0,
print '' if __name__ == "__main__":
sd = Svd()
data = sd.loadExData2()
sd.recommend(mat(data), 2, 3, sd.cosSim, sd.svdEst)
sd.imageCompress()
[机器学习]-SVD奇异值分解的基本原理和运用的更多相关文章
- SVD奇异值分解的基本原理和运用
SVD奇异值分解: SVD是一种可靠的正交矩阵分解法.可以把A矩阵分解成U,∑,VT三个矩阵相乘的形式.(Svd(A)=[U*∑*VT],A不必是方阵,U,VT必定是正交阵,S是对角阵<以奇异值 ...
- 简单易学的机器学习算法—SVD奇异值分解
简单易学的机器学习算法-SVD奇异值分解 一.SVD奇异值分解的定义 假设M是一个的矩阵,如果存在一个分解: 其中的酉矩阵,的半正定对角矩阵,的共轭转置矩阵,且为的酉矩阵.这样的分解称为M的奇 ...
- SVD奇异值分解的几何物理意义资料汇总
学习SVD奇异值分解的网上资料汇总: 1. 关于svd的一篇概念文,这篇文章也是后续几篇文章的鼻祖~ http://www.ams.org/samplings/feature-column/fcarc ...
- 『科学计算_理论』SVD奇异值分解
转载请声明出处 SVD奇异值分解概述 SVD不仅是一个数学问题,在工程应用中的很多地方都有它的身影,比如前面讲的PCA,掌握了SVD原理后再去看PCA那是相当简单的,在推荐系统方面,SVD更是名声大噪 ...
- 机器学习(十七)— SVD奇异值分解
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域.是 ...
- [机器学习笔记]奇异值分解SVD简介及其在推荐系统中的简单应用
本文先从几何意义上对奇异值分解SVD进行简单介绍,然后分析了特征值分解与奇异值分解的区别与联系,最后用python实现将SVD应用于推荐系统. 1.SVD详解 SVD(singular value d ...
- 机器学习之-奇异值分解(SVD)原理详解及推导
转载 http://blog.csdn.net/zhongkejingwang/article/details/43053513 在网上看到有很多文章介绍SVD的,讲的也都不错,但是感觉还是有需要补充 ...
- 机器学习降维--SVD奇异值分解
奇异值分解是有着很明显的物理意义,将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性,让机器学会抽取重要的特征,SVD是一个重要的方法. 所以SVD不仅是一个 ...
- 机器学习SVD笔记
机器学习中SVD总结 矩阵分解的方法 特征值分解. PCA(Principal Component Analysis)分解,作用:降维.压缩. SVD(Singular Value Decomposi ...
随机推荐
- OpenCV学习C++接口 Mat像素遍历详解
OpenCV学习C++接口 Mat像素遍历详解
- navicat 创建查询失败 can not create file
数据库连接很正常, 却无法创建查询, 不知道啥毛病 竟然是存储路径问题,点开连接属性,修改高级里面的保存路径,删掉“:3308”, OK了.冒号是个windows保留的盘符,应该就是这个原因
- [UOJ#276][清华集训2016]汽水[分数规划+点分治]
题意 给定一棵 \(n\) 个点的树,给定 \(k\) ,求 \(|\frac{\sum w(路径长度)}{t(路径边数)}-k|\)的最小值. \(n\leq 5\times 10^5,k\leq ...
- 阿里云centos 安装禅道
下载 我的阿里云服务器系统是 centos6.8 64 位,下载的禅道版本是 Linux 64位一键安装包(适用于Linux 64位) 由于阿里云服务器没桌面,所以下载用不了浏览器,可考虑在本地下载后 ...
- shell实现压缩多个文件
Linux环境下写一个脚本 从键盘让用户输入几个文件,脚本能够将此几个文件归档压缩成一个文件: 1.首先介绍一下case语句格式 case SWITCH in value1) statement .. ...
- java的struts2项目实现网站首页只显示域名不显示index.do的做法
自己的网站快做完了,发现首页显示的时候总是跳转到http://www.xxxxxx.com/index.do 而我想让http://www.xxxxxx.com/ 这样的方式来访问,不想带有后边的in ...
- SimpleDateFormat的一些常用用法
/** SimpleDateFormat函数语法: G 年代标志符 y 年 M 月 d 日 h 时 在上午或下午 (1~12) H 时 在一天中 (0~23) m 分 s 秒 S 毫秒 E 星期 D ...
- (第十二周)Debug阶段成员贡献分
项目名:食物链教学工具 组名:奋斗吧兄弟 组长:黄兴 组员:李俞寰.杜桥.栾骄阳.王东涵 个人贡献分=基础分+表现分 基础分=5*5*0.5/5=2.5 成员得分如下: 成员 基础分 表现分 个人贡献 ...
- 每日scrum(5)
进入冲刺第五天,软件的界面设计成为主打,收集学校的很多美图是我们组的任务: 问题在于软件已很难有很大的改进,大方向也都是变不了的 任务看板: 燃尽图:
- Beta版本冲刺(四)
目录 组员情况 组员1(组长):胡绪佩 组员2:胡青元 组员3:庄卉 组员4:家灿 组员:恺琳 组员6:翟丹丹 组员7:何家伟 组员8:政演 组员9:黄鸿杰 组员10:刘一好 组员11:何宇恒 展示组 ...