第4章 SparkSQL数据源
第4章 SparkSQL数据源
4.1 通用加载/保存方法
4.1.1 手动指定选项
Spark SQL的DataFrame接口支持多种数据源的操作。一个DataFrame可以进行RDDs方式的操作,也可以被注册为临时表。把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询。
Spark SQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项spark.sql.sources.default,可修改默认数据源格式。
val df = spark.read.load("examples/src/main/resources/users.parquet") df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
当数据源格式不是parquet格式文件时,需要手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),如果数据源格式为内置格式,则只需要指定简称定json, parquet, jdbc, orc, libsvm, csv, text来指定数据的格式。
可以通过SparkSession提供的read.load方法用于通用加载数据,使用write和save保存数据。
val peopleDF = spark.read.format("json").load("examples/src/main/resources/people.json")
peopleDF.write.format("parquet").save("hdfs://hadoop102:9000/namesAndAges.parquet")
除此之外,可以直接运行SQL在文件上:
val sqlDF = spark.sql("SELECT * FROM parquet.`hdfs://hadoop102:9000/namesAndAges.parquet`")
sqlDF.show()
scala> val peopleDF = spark.read.format("json").load("examples/src/main/resources/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.write.format("parquet").save("hdfs://hadoop102:9000/namesAndAges.parquet")
scala> peopleDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
scala> val sqlDF = spark.sql("SELECT * FROM parquet.`hdfs://master01:9000/namesAndAges.parquet`")
17/09/05 04:21:11 WARN ObjectStore: Failed to get database parquet, returning NoSuchObjectException
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> sqlDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
4.1.2 文件保存选项
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。需要注意的是,这些保存模式不使用任何锁定,不是原子操作。此外,当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。SaveMode详细介绍如下表:

4.2 Parquet文件
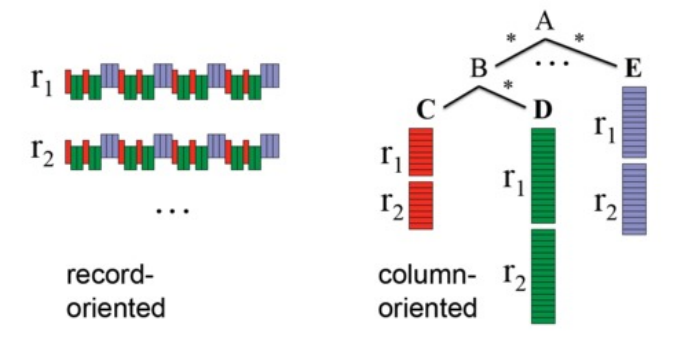
Parquet是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。
4.2.1 Parquet读写
Parquet格式经常在Hadoop生态圈中被使用,它也支持Spark SQL的全部数据类型。Spark SQL 提供了直接读取和存储 Parquet 格式文件的方法。
// Encoders for most common types are automatically provided by importing spark.implicits._
import spark.implicits._ val peopleDF = spark.read.json("examples/src/main/resources/people.json") // DataFrames can be saved as Parquet files, maintaining the schema information
peopleDF.write.parquet("hdfs://master01:9000/people.parquet") // Read in the parquet file created above
// Parquet files are self-describing so the schema is preserved
// The result of loading a Parquet file is also a DataFrame
val parquetFileDF = spark.read.parquet("hdfs://master01:9000/people.parquet") // Parquet files can also be used to create a temporary view and then used in SQL statements
parquetFileDF.createOrReplaceTempView("parquetFile")
val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 13 AND 19")
namesDF.map(attributes => "Name: " + attributes(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
4.2.2 解析分区信息
对表进行分区是对数据进行优化的方式之一。在分区的表内,数据通过分区列将数据存储在不同的目录下。Parquet数据源现在能够自动发现并解析分区信息。例如,对人口数据进行分区存储,分区列为gender和country,使用下面的目录结构:
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...
通过传递path/to/table给 SQLContext.read.parquet或SQLContext.read.load,Spark SQL将自动解析分区信息。返回的DataFrame的Schema如下:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
需要注意的是,数据的分区列的数据类型是自动解析的。当前,支持数值类型和字符串类型。自动解析分区类型的参数为:spark.sql.sources.partitionColumnTypeInference.enabled,默认值为true。如果想关闭该功能,直接将该参数设置为disabled。此时,分区列数据格式将被默认设置为string类型,不再进行类型解析。
4.2.3 Schema合并
像ProtocolBuffer、Avro和Thrift那样,Parquet也支持Schema evolution(Schema演变)。用户可以先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。现在Parquet数据源能自动检测这种情况,并合并这些文件的schemas。
因为Schema合并是一个高消耗的操作,在大多数情况下并不需要,所以Spark SQL从1.5.0开始默认关闭了该功能。可以通过下面两种方式开启该功能:
当数据源为Parquet文件时,将数据源选项mergeSchema设置为true
设置全局SQL选项spark.sql.parquet.mergeSchema为true
示例如下:
// sqlContext from the previous example is used in this example.
// This is used to implicitly convert an RDD to a DataFrame.
import spark.implicits._ // Create a simple DataFrame, stored into a partition directory
val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.write.parquet("hdfs://master01:9000/data/test_table/key=1") // Create another DataFrame in a new partition directory,
// adding a new column and dropping an existing column
val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple")
df2.write.parquet("hdfs://master01:9000/data/test_table/key=2") // Read the partitioned table
val df3 = spark.read.option("mergeSchema", "true").parquet("hdfs://master01:9000/data/test_table")
df3.printSchema() // The final schema consists of all 3 columns in the Parquet files together
// with the partitioning column appeared in the partition directory paths.
// root
// |-- single: int (nullable = true)
// |-- double: int (nullable = true)
// |-- triple: int (nullable = true)
// |-- key : int (nullable = true)
4.3 Hive数据库
Apache Hive是Hadoop上的SQL引擎,Spark SQL编译时可以包含Hive支持,也可以不包含。包含Hive支持的Spark SQL可以支持Hive表访问、UDF(用户自定义函数)以及 Hive 查询语言(HiveQL/HQL)等。需要强调的 一点是,如果要在Spark SQL中包含Hive的库,并不需要事先安装Hive。一般来说,最好还是在编译Spark SQL时引入Hive支持,这样就可以使用这些特性了。如果你下载的是二进制版本的 Spark,它应该已经在编译时添加了 Hive 支持。
若要把Spark SQL连接到一个部署好的Hive上,你必须把hive-site.xml复制到 Spark的配置文件目录中($SPARK_HOME/conf)。即使没有部署好Hive,Spark SQL也可以运行。 需要注意的是,如果你没有部署好Hive,Spark SQL会在当前的工作目录中创建出自己的Hive 元数据仓库,叫作 metastore_db。此外,如果你尝试使用 HiveQL 中的 CREATE TABLE (并非 CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的 /user/hive/warehouse 目录中(如果你的 classpath 中有配好的 hdfs-site.xml,默认的文件系统就是 HDFS,否则就是本地文件系统)。
import java.io.File import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession case class Record(key: Int, value: String) // warehouseLocation points to the default location for managed databases and tables
val warehouseLocation = new File("spark-warehouse").getAbsolutePath val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate() import spark.implicits._
import spark.sql sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src") // Queries are expressed in HiveQL
sql("SELECT * FROM src").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ... // Aggregation queries are also supported.
sql("SELECT COUNT(*) FROM src").show()
// +--------+
// |count(1)|
// +--------+
// | 500 |
// +--------+ // The results of SQL queries are themselves DataFrames and support all normal functions.
val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key") // The items in DataFrames are of type Row, which allows you to access each column by ordinal.
val stringsDS = sqlDF.map {
case Row(key: Int, value: String) => s"Key: $key, Value: $value"
}
stringsDS.show()
// +--------------------+
// | value|
// +--------------------+
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// ... // You can also use DataFrames to create temporary views within a SparkSession.
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records") // Queries can then join DataFrame data with data stored in Hive.
sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
// +---+------+---+------+
// |key| value|key| value|
// +---+------+---+------+
// | 2| val_2| 2| val_2|
// | 4| val_4| 4| val_4|
// | 5| val_5| 5| val_5|
4.3.1 内嵌Hive应用
如果要使用内嵌的Hive,什么都不用做,直接用就可以了。 --conf : spark.sql.warehouse.dir=
注意:如果你使用的是内部的Hive,在Spark2.0之后,spark.sql.warehouse.dir用于指定数据仓库的地址,如果你需要是用HDFS作为路径,那么需要将core-site.xml和hdfs-site.xml 加入到Spark conf目录,否则只会创建master节点上的warehouse目录,查询时会出现文件找不到的问题,这是需要向使用HDFS,则需要将metastore删除,重启集群。
4.3.2 外部Hive应用
如果想连接外部已经部署好的Hive,需要通过以下几个步骤。
1) 将Hive中的hive-site.xml拷贝或者软连接到Spark安装目录下的conf目录下。
2) 打开spark shell,注意带上访问Hive元数据库的JDBC客户端
$ bin/spark-shell --master spark://hadoop102:7077 --jars mysql-connector-java-5.1.27-bin.jar
4.4 JSON数据集
Spark SQL 能够自动推测 JSON数据集的结构,并将它加载为一个Dataset[Row]. 可以通过SparkSession.read.json()去加载一个 Dataset[String]或者一个JSON 文件.注意,这个JSON文件不是一个传统的JSON文件,每一行都得是一个JSON串。
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
// Primitive types (Int, String, etc) and Product types (case classes) encoders are
// supported by importing this when creating a Dataset.
import spark.implicits._
// A JSON dataset is pointed to by path.
// The path can be either a single text file or a directory storing text files
val path = "examples/src/main/resources/people.json"
val peopleDF = spark.read.json(path)
// The inferred schema can be visualized using the printSchema() method
peopleDF.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people")
// SQL statements can be run by using the sql methods provided by spark
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
// +------+
// | name|
// +------+
// |Justin|
// +------+
// Alternatively, a DataFrame can be created for a JSON dataset represented by
// a Dataset[String] storing one JSON object per string
val otherPeopleDataset = spark.createDataset(
"""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val otherPeople = spark.read.json(otherPeopleDataset)
otherPeople.show()
// +---------------+----+
// | address|name|
// +---------------+----+
// |[Columbus,Ohio]| Yin|
// +---------------+----+
4.5 JDBC
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
注意,需要将相关的数据库驱动放到spark的类路径下。
$ bin/spark-shell --master spark://hadoop102:7077 --jars mysql-connector-java-5.1.27-bin.jar // Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://master01:3306/rdd").option("dbtable", " rddtable").option("user", "root").option("password", "hive").load() val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "hive")
val jdbcDF2 = spark.read
.jdbc("jdbc:mysql://master01:3306/rdd", "rddtable", connectionProperties) // Saving data to a JDBC source
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:mysql://master01:3306/rdd")
.option("dbtable", "rddtable2")
.option("user", "root")
.option("password", "hive")
.save() jdbcDF2.write
.jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties) // Specifying create table column data types on write
jdbcDF.write
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)
第4章 SparkSQL数据源的更多相关文章
- 第3章 SparkSQL解析
第3章 SparkSQL解析 3.1 新的起始点SparkSession 在老的版本中,SparkSQL提供两种SQL查询起始点,一个叫SQLContext,用于Spark自己提供的SQL查询,一个叫 ...
- Spark SQL 编程API入门系列之SparkSQL数据源
不多说,直接上干货! SparkSQL数据源:从各种数据源创建DataFrame 因为 spark sql,dataframe,datasets 都是共用 spark sql 这个库的,三者共享同样的 ...
- 关于自定义sparkSQL数据源(Hbase)操作中遇到的坑
自定义sparkSQL数据源的过程中,需要对sparkSQL表的schema和Hbase表的schema进行整合: 对于spark来说,要想自定义数据源,你可以实现这3个接口: BaseRelatio ...
- 《手写Mybatis》第5章:数据源的解析、创建和使用
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 管你吃几碗粉,有流量就行! 现在我们每天所接收的信息量越来越多,但很多的个人却没有多 ...
- 《Mybatis 手撸专栏》第6章:数据源池化技术实现
作者:小傅哥 博客:https://bugstack.cn - 手写Mybatis系列文章 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 码农,只会做不会说? 你有发现吗,其实很大一部分码农 ...
- 【大数据】SparkSql学习笔记
第1章 Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和 DataSet,并且作为分布式 ...
- Spark RDDs vs DataFrames vs SparkSQL
简介 Spark的 RDD.DataFrame 和 SparkSQL的性能比较. 2方面的比较 单条记录的随机查找 aggregation聚合并且sorting后输出 使用以下Spark的三种方式来解 ...
- 以慕课网日志分析为例-进入大数据Spark SQL的世界
下载地址.请联系群主 第1章 初探大数据 本章将介绍为什么要学习大数据.如何学好大数据.如何快速转型大数据岗位.本项目实战课程的内容安排.本项目实战课程的前置内容介绍.开发环境介绍.同时为大家介绍项目 ...
- 以某课网日志分析为例 进入大数据 Spark SQL 的世界
第1章 初探大数据 本章将介绍为什么要学习大数据.如何学好大数据.如何快速转型大数据岗位.本项目实战课程的内容安排.本项目实战课程的前置内容介绍.开发环境介绍.同时为大家介绍项目中涉及的Hadoop. ...
随机推荐
- ajax快速入门
一.ajax简单入门 1.Ajax的实现步骤 // 1.创建ajax对象var xhr = new XMLHttpRequest();// 2.高数ajax请求地址及请求方式//第一个参数就是请求方式 ...
- 解决element上传功能清除单个文件的问题
今天,在使用 element 实现一个上传文件的功能. 接下来,要对上传的文件列表,实现删除单文件的功能. 看了 element 开发文档,发现 on-remove 没有特别的详细的说明,刚开始使用 ...
- Python JSON的基本使用
Python JSON的基本使用 一.json格式介绍 JSON(JavaScript Object Notation) 通用的数据类型,易于人阅读和编写. 跟字典有些类似,形式也是key-value ...
- iOS 高效灵活地配置可复用视图组件的主题
本文首发于 Ficow Shen's Blog,原文地址: iOS 高效灵活地配置可复用视图组件的主题. 内容概览 前言 如何配置主题? 如何更高效地配置主题? 面向协议/接口的方案 ...
- PHP date_sub() 函数
------------恢复内容开始------------ 实例 从 2013 年 3 月 15 日减去 40 天: <?php$date=date_create("2013-03- ...
- PHP fputs() 函数
定义和用法 fputs() 函数将内容写入一个打开的文件中. 函数会在到达指定长度或读到文件末尾(EOF)时(以先到者为准),停止运行. 如果函数成功执行,则返回写入的字节数.如果失败,则返回 FAL ...
- luogu P2252 威佐夫博弈 模板 博弈
LINK:威佐夫博弈 四大博弈 我都没有好好整理 不过大致可以了解一下. 在这个博弈中 存在一些局面 先手遇到必胜. 不过由于后手必胜的局面更具规律性这里研究先手遇到的局面后手必胜的情况. 这些局面分 ...
- 回首Java——再回首JDK
如果你是刚要被Java军训的新兵,可有几时对环境搭建而不知所措?又如若你是驰骋Java战场多年的老将,可曾拿起陪伴你许久的82年的JDK回味一番?今天我们就来道一道JDK,重新来认识认识这个既熟悉又陌 ...
- 在不同网段使用 VLAN 通信 - SVI,单臂路由
在 VLAN 这篇文章中知道,设置 VLAN 目的是隔离大型的广播域,将其分成很小的广播域,从而更好的管理.但也就带来了一些问题:如流量不能在不同的 VLAN 间通信. 而为了解决这个问题,可以采用如 ...
- Chrome划词翻译-Saladict
Saladict 沙拉查词是一款专业划词翻译扩展,为交叉阅读而生.大量权威词典涵盖中英日韩法德西语,支持复杂的 划词操作.网页翻译.生词本.PDF,以及 Vimium 全键盘操作 . 迄今为止最好用的 ...