(十) 数据库查询处理之排序(sorting)
1. 为什么我们需要对数据排序
- 可以支持对于重复元素的清除(支持DISTINCT)
- 可以支持GROUP BY 操作
- 对于关系运算中的一些运算能够得到高效的实现
2. 引入外部排序算法
对于不能全部放在内存中的关系的排序。就需要引入外排序,其中最常用的技术就是外部归并排序。
外部排序分为两个阶段
Phase1 - Sorting
对主存中的数据块进行排序,然后将排序后的数据块写回磁盘。
Phase2 - Merging
将已排序的子文件合并成一个较大的文件
2.1 N-way 外部归并排序
从2路归并排序开始。来引出N路归并排序算法
可以见下图


对于简单的二路归并。我们有两个buffer可以用。一个用来放输入进行排序得到归并块。而另一个则用来放输出
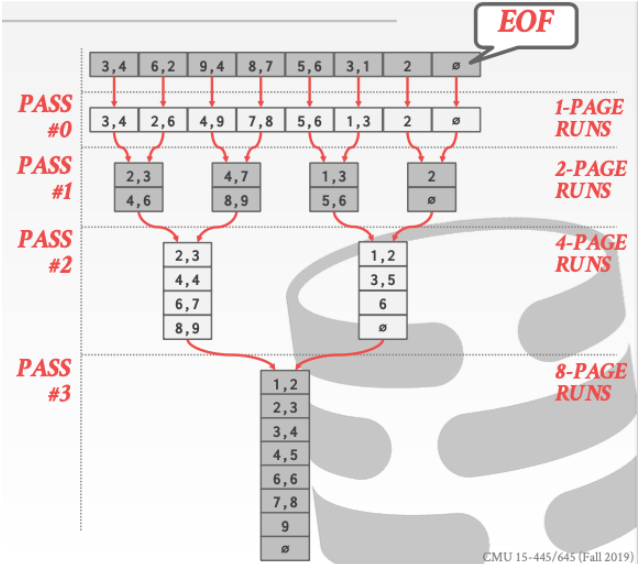
下面来分析一下二路归并的时间复杂度
在每一个阶段我们都需要把归并块从磁盘中读入。然后在写回磁盘因此总共的I/O次数就是阶段数 * 2
阶段数可以很容易的得到为

可以很容易的发现上面的问题主要出现在。由于我们的输入缓冲区只能放一个page。所以这导致了我们不停的进行换入换出导致了io次数变得非常多。优化方法就是加大缓冲区大小。减少阶段数。这就需要我们归并路数增大。
使用B buffer pages 这样我们的输入缓冲区就可以放B - 1个page。这样我们的阶段数就可以减少了。

2.2 利用索引进行加速
如果我们的table中已经有了B+树索引。那么我们可以利用它进行优化。
这里有两种情况需要被考虑
聚簇索引
数据的物理地址顺序和索引的顺序是一致的。
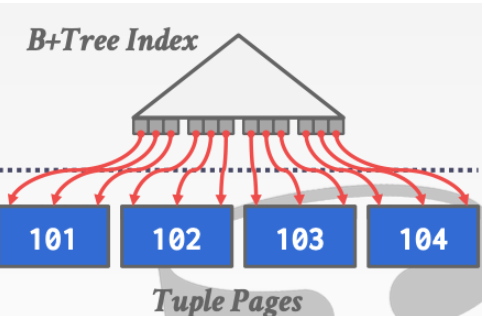
这种方法比外部排序要好,因为它没有额外的计算。比如不需要进行sort。不需要进行归并。而且所有的磁盘访问都是顺序的。
非聚簇索引
数据的物理地址顺序和索引的顺序是不一致的。
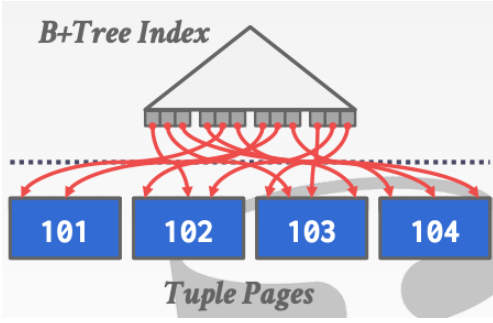
如果是这样的索引。就利用外部排序就好。
2.3 AGGREGATIONS
将多个元组折叠为单个标量值。有两种实现方法
1. 排序
排序之后相同的元素就会在排在一起。这样就可以去除冗余元素

2. hash
但是如果我们不要求数据是有序的。这样我们排序就相当于浪费了时间。因为排序起码要花费nlogn的时间。比如GROUP BY
和DISTINCT操作。在这种情况下。hashing就是一个更好的选择
1. Partition
假设我们有B buffers。其中B - 1个buffer用来partitions而1个buffer用来存储输出data。
第一阶段就是利用一个hash函数。把tuple哈希到不同的桶中。

2. Rehash
由于阶段1之后。拥有相同cid值的tuple都被映射到了相同的桶内。这个阶段我们对不同的桶在进行一次hash。就可以完成我们的去重操作。
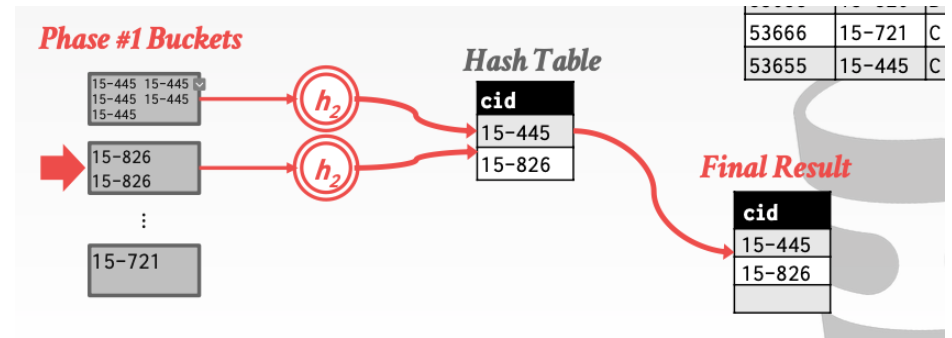
当然利用hash操作不仅可以进行去重还可以进行其他的操作。如MAX、MIN、AVG、COUNT、SUM等
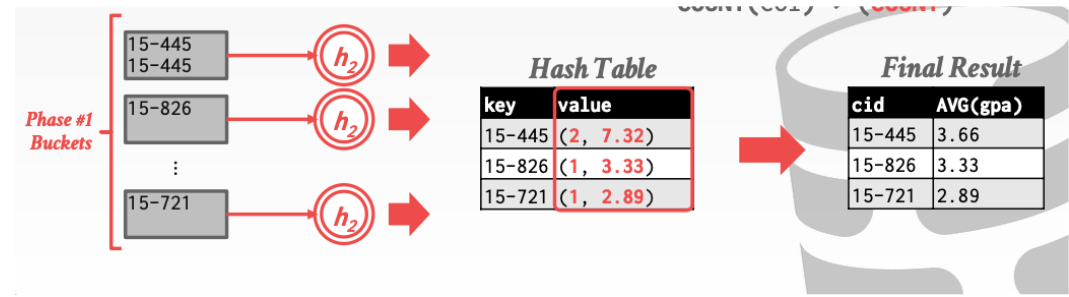
下面这张图演示了count操作和sum操作。
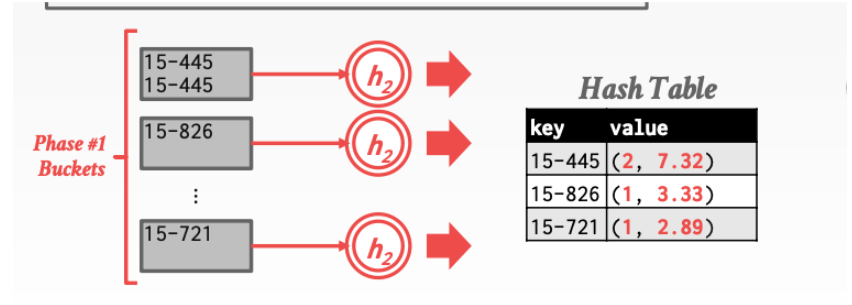
这张图演示了avg操作就是利用 sum / count
这个算是结合cmu15-445课程和对应的教材、ppt进行的总结。顺序从10开始是因为现在正好看到这里。而之前忘了整理了。会在后面所有的都看完之后进行整理的。
(十) 数据库查询处理之排序(sorting)的更多相关文章
- (十二)数据库查询处理之Query Execution(1)
(十二)数据库查询处理之Query Execution(1) 1. 写在前面 这一大部分就是为了Lab3做准备的 每一个query plan都要实现一个next函数和一个init函数 对于next函数 ...
- MySQL 按照数据库表字段动态排序 查询列表信息
MySQL 按照数据库表字段动态排序 查询列表信息 背景描述 项目中数据列表分页展示的时候,前端使用的Table组件,每列自带对当前页的数据进行升序或者降序的排序. 但是客户期望:随机点击某一列的时候 ...
- 第九十九天上课 PHP TP框架 数据库查询和增加
在Model文件夹下创建模型,文件命名规则 : 表名Model.class.php <?php namespace Home\Model; use Think\Model; class yong ...
- mysql数据库查询过程探究和优化建议
查询过程探究 我们先看一下向mysql发送一个查询请求时,mysql做了什么? 如上图所示,查询执行的过程大概可分为6个步骤: 客户端向MySQL服务器发送一条查询请求 服务器首先检查查询缓存,如果命 ...
- 下面介绍一下 Yii2.0 对数据库 查询的一些简单的操作
下面介绍一下 Yii2.0 对数据库 查询的一些简单的操作 User::find()->all(); 此方法返回所有数据: User::findOne($id); 此方法返回 主键 id=1 的 ...
- 50种方法优化SQL Server数据库查询
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
- 优化SQL Server数据库查询方法
SQL Server数据库查询速度慢的原因有很多,常见的有以下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列 ...
- mysql 数据库查询与实例。
资料是从教材弄下来的,加上了我的理解.主要内容是练习实例,在写博文中学习命令行,当然也希望这篇博文能帮助其他人学习mysq数据库命令 SELECT 语句可以从一个或多个表中选取特定的行和列 SELEC ...
- 转载 50种方法优化SQL Server数据库查询
原文地址 http://www.cnblogs.com/zhycyq/articles/2636748.html 50种方法优化SQL Server数据库查询 查询速度慢的原因很多,常见如下几种: 1 ...
随机推荐
- 设计模式(六)——建造者模式(源码StringBuilder分析)
建造者模式 1 盖房项目需求 1) 需要建房子:这一过程为打桩.砌墙.封顶 2) 房子有各种各样的,比如普通房,高楼,别墅,各种房子的过程虽然一样,但是要求不要相同的. 3) 请编写程序,完成需求. ...
- Java排序算法(四)希尔排序1
希尔排序交换法:分组+冒泡排序组合 一.测试类SortTest import java.util.Arrays; public class SortTest { private static fina ...
- vue-cli3移动端自适应配置 Vant组件库
module.exports = { presets: [ '@vue/app' ], plugins: [ ['import', { libraryName: 'vant', libraryDire ...
- hdu 6704 K-th occurrence(后缀数组+可持久化线段树)
Problem Description You are given a string S consisting of only lowercase english letters and some q ...
- 2. Linear Regression with One Variable
Speaker:Andrew Ng 这一次主要讲解的是单变量的线性回归问题. 1.Model Representation 先来一个现实生活中的例子,这里的例子是房子尺寸和房价的模型关系表达. 通过学 ...
- Educational Codeforces Round 84 (Div. 2)
Educational Codeforces Round 84 (Div. 2) 读题读题读题+脑筋急转弯 = =. A. Sum of Odd Integers 奇奇为奇,奇偶为偶,所以n,k奇偶性 ...
- Codeforces Round #646 (Div. 2) C. Game On Leaves(树上博弈)
题目链接:https://codeforces.com/contest/1363/problem/C 题意 有一棵 $n$ 个结点的树,每次只能取叶子结点,判断谁能最先取到结点 $x$ . 题解 除非 ...
- 仿ATM程序软件
一.目标: ATM仿真软件 1 系统的基本功能 ATM的管理系统其基本功能如下:密码验证机制:吞锁卡机制:存取款功能:账户查询功能:转账功能等. 要求 要能提供以下几个基本功能: (1)系统内的相关信 ...
- hdu3480 Division
Problem Description Little D is really interested in the theorem of sets recently. There's a problem ...
- kubernetes实战-配置中心(三)配置服务使用apollo配置中心
使用配置中心,需要开发对代码进行调整,将一些配置,通过变量的形式配置到apollo中,服务通过配置中心来获取具体的配置 在配置中心修改新增如下配置: 项目信息: 配置: 重新打包镜像,使用apollo ...