scrapy爬虫登录edusrc查看漏洞列表
scrapy登录界面的难点在于登录时候的验证码,我们通过使用scrapy.FormRequest向目标网站提交数据(表单提交),同时将验证码显示在本地,手动输入,进而登录。

验证码是类似于这种的,才可以通过此方式登录,如网站是通过滑块验证登录的话,此方法就不再适用
因为要找到这种验证码登录的网站一时之间没找到,本想用学校教务系统的登录网站进行测试,但是测试后发现验证码是动态加载的,故放弃,找了一会,就用提交教育漏洞的edusrc网站作为练习登录爬虫的站点
登录url是:https://src.sjtu.edu.cn/login/
我们先登录一下,查看需要post哪些数据

可以看到,这里POST表单里面我们提交了username,password,captcha_1,captcha_0以及csrfmiddlewaretoken
username和password是我们的登录邮箱和密码,captcha_1是输入的验证码,captcha_0我猜测是每次登录的时候都会根据网站算法而更新的一个值,csrfmiddlewaretoken也是一个根据算法更新的值,从名字可以看出是防止csrf攻击而生成的令牌值,告诉网站来到这个页面的用户的权限。
而提交的数据中,captcha_0和csrfmiddlewaretoken都是直接从页面中获取的,我们先用xpath从页面中获取这两个值


使用xpath语法对这两个值进行提取:
formdata={
'username': '',
'password': ''
}
captcha_0=response.xpath('//input[@name="captcha_0"]/@value').get()
formdata['captcha_0']=captcha_0
csrfmiddlewaretoken=response.xpath('//input[@name="csrfmiddlewaretoken"]/@value').get()
formdata['csrfmiddlewaretoken']=csrfmiddlewaretoken
其中username和password需要自己输入,这个时候就只剩下captcha_1即验证码没有获取了
查看源代码 之后可知:

验证码存在一个url,这个url里面的验证码每次刷新之后都会改变,但是url也在不断变化,使用xpath提取这个url,然后我们进一步进行处理
captcha_url = response.xpath('//img/@src').get()
captcha_url = 'https://src.sjtu.edu.cn/' + captcha_url
print captcha_url
captcha = self.check_captcha(captcha_url)
check_captcha函数就是我们用来处理captcha_url即验证码url的
def check_captcha(self,image_url):
urllib.urlretrieve(image_url,'captcha.jpg')
image=Image.open('captcha.jpg')
image.show()
captcha=raw_input('please input captcha:')
return captcha
我们使用了urlretrieve函数来下载远程url的数据,这里就是将验证码图片下载在了本地我们查看
python2和python3都可以使用urlretrieve函数,使用方法略有不同,我使用的是python2,参考这篇博客修改的:
https://blog.csdn.net/drdairen/article/details/61934598?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
获取到的验证码图片会保存在当前文件夹下,接着我们使用Image打开该图片同时show,看到验证码图片的我们关闭图片后输入验证码字符串并返回该字符串
formdata['captcha_1'] = captcha
yield scrapy.FormRequest(url=self.login_url,formdata=formdata,callback=self.parse_after_login)
将captcha_1加入到formdata之后,我们向login_url提交formdata,同时为了检测我们是否成功登录,回调函数是parse_after_login
def parse_after_login(self,response):
if response.url=="https://src.sjtu.edu.cn/":
yield scrapy.FormRequest(self.bug_url,callback=self.parse_bug)
print "login successful!"
else:
print "login failed!"
自己尝试登录之后,可以知道登录了之后网站会自动将我们302重定向到https://src.sjtu.edu.cn/,所以我们只需要检测response.url是否跟https://src.sjtu.edu.cn/相同即可
我们登录了之后去bugurl即https://src.sjtu.edu.cn/list/?page=1页面第一页提取bug_list信息打印出来,证明可以做到登录之后的操作即可,因为为了避免信息泄露,漏洞列表里登录后和没登录看到的漏洞信息是不一样的,侧面可以反映我们是否登录成功
def parse_bug(self,response):
print response.url
if response.url==self.bug_url:
print "join bug_list successful!" bug_list=response.xpath('//td/a[contains(@href,"/post/")]/text()').getall()
for bug in bug_list:
print bug
else:
print "join bug_list failed!"
现在主要的部分就写好了,填入username和password运行试试
运行之后跳出验证码图片

输入验证码之后输出第一页的漏洞列表:
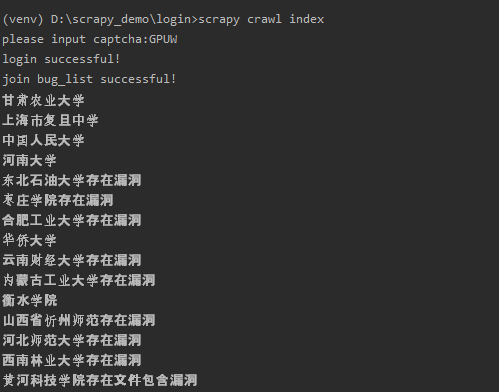
可以看到跟登录之后的漏洞信息显示相同
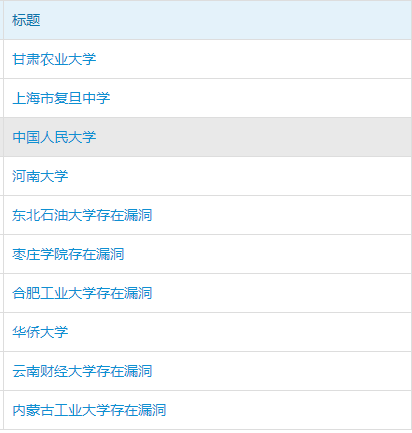
如果没登录的话,显示的信息是这样的:

其实我感觉没登录的时候看到的信息要多一些:)
可以看出我们登录成功了。
这个代码主要是识别验证码和POST提交formdata数据比较重要
代码放在github上面了:
https://github.com/Cl0udG0d/scrapy_demo
参考链接:
https://blog.csdn.net/drdairen/article/details/61934598?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
http://binxiaoer.top/blog/detail/88
scrapy爬虫登录edusrc查看漏洞列表的更多相关文章
- scrapy爬虫系列之四--爬取列表和详情
功能点:如何爬取列表页,并根据列表页获取详情页信息? 爬取网站:东莞阳光政务网 完整代码:https://files.cnblogs.com/files/bookwed/yangguang.zip 主 ...
- python爬虫之scrapy模拟登录
背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎 ...
- python爬虫scrapy之登录知乎
下面我们看看用scrapy模拟登录的基本写法: 注意:我们经常调试代码的时候基本都用chrome浏览器,但是我就因为用了谷歌浏览器(它总是登录的时候不提示我用验证码,误导我以为登录时不需要验证码,其实 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapy爬虫入门Request和Response(请求和响应)
开发环境:Python 3.6.0 版本 (当前最新)Scrapy 1.3.2 版本 (当前最新) 请求和响应 Scrapy的Request和Response对象用于爬网网站. 通常,Request对 ...
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
豆瓣有些电影页面需要登录才能查看. 目录 [隐藏] 1 创建工程 2 定义Item 3 编写爬虫(Spider) 4 存储数据 5 配置文件 6 艺搜参考 创建工程 scrapy startproj ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
随机推荐
- Java8 新特性 —— Stream 流式编程
本文部分摘自 On Java 8 流概述 集合优化了对象的存储,大多数情况下,我们将对象存储在集合是为了处理他们.使用流可以帮助我们处理对象,无需迭代集合中的元素,即可直接提取和操作元素,并添加了很多 ...
- Pandas_数据读取与存储数据(全面但不精炼)
Pandas 读取和存储数据 目录 读取 csv数据 读取 txt数据 存储 csv 和 txt 文件 读取和存储 json数据 读取和存储 excel数据 一道练习题 参考 Numpy基础(全) P ...
- [tmp]__URL
常用排序算法稳定性.时间复杂度分析(转,有改动) http://www.cnblogs.com/nannanITeye/archive/2013/04/11/3013737.html http://w ...
- close wait 状态的随想
今天在新入职的公司处理waf 的问题时,突然看到了一个tcp状态close-wait 想一想 close-wait 是怎样产生的???? 被动收到FIN 关闭请求,协议栈主动发出ACK, 等待 本端主 ...
- linux 调试&各种知识收集2(持续更新)
1.查看netlink socket 丢包 cat /proc/net/netlink sk Eth Pid Groups Rmem Wmem Dump Locks Drops Inode c91ed ...
- facl权限(getfacl/setfacl)
file access control list:文件访问控制列表 查看facl: [root@localhost test]# getfacl hei # file: hei # owner: ro ...
- AQS详解,并发编程的半壁江山
千呼万唤始出来,终于写到AQS这个一章了,其实为了写这一章,前面也是做了很多的铺垫,比如之前的 深度理解volatile关键字 线程之间的协作(等待通知模式) JUC 常用4大并发工具类 CAS 原子 ...
- Docker版EKL安装记录文档
Docker版EKL安装记录文档 拉取已下三个镜像 docker.io/logstash 7.5.2 b6518c95ed2f 6 months ago 805 MB docker.io/kibana ...
- python爬虫分析报告
在python课上布置的作业,第一次进行爬虫,走了很多弯路,也学习到了很多知识,借此记录. 1. 获取学堂在线合作院校页面 要求: 爬取学堂在线的计算机类课程页面内容. 要求将课程名称.老师.所属学校 ...
- spring boot配置MySQL8.0 Druid数据源
创建spring boot项目,在pom中添加相应依赖 <!--web--> <dependency> <groupId>org.springframework.b ...