python爬虫之PyQuery的基本使用
PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严格实现。语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了。
官网地址:http://pyquery.readthedocs.io/en/latest/
jQuery参考文档: http://jquery.cuishifeng.cn/
1、字符串的初始化
from pyquery import PyQuery as pq html = '''<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
print(doc)
print(type(doc))
print(doc('li'))
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<class 'pyquery.pyquery.PyQuery'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
运行结果
2、打开html文件
注意路劲问题
from pyquery import PyQuery as pq
doc = pq(filename='index.html')
print(doc)
print(doc('head'))
<title>Title</title>
</head>
<body>
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>'''
</body>
</html>
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
运行结果
3、打开某个网站
doc = pq('https://www.baidu.com')
# doc1 = pq(url='https://www.baidu.com')
print(doc)
print(doc('head'))
4、基于CSS选择器查找
from pyquery import PyQuery as pq html = '''<div>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
print(doc)
#id等于haha下面的class等于item-0下的a标签下的span标签(注意层级关系以空格隔开)
print(doc('#haha .item-0 a span'))
<div>
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<span class="bold">third item</span>
运行结果
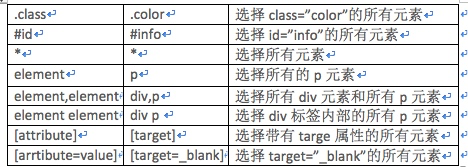
5、可以通过已经查找的标签,查找这个标签下的子标签或者父标签,而不用从头开始查找。
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
item = doc('div ul')
print(item)
#我们可以通过已经查找到的标签,再此查找这个标签下面的标签
print(item.parent())
print(item.children())
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
<div class="‘content’">
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
运行结果
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
item = doc('div ul')
print(item)
#注意这里查找ul标签的所有子标签,也就是li标签,下面是查找class属性的标签,如果你把class换成href肯定不行,它指的只是儿子并不是子子孙孙
print(item.children('[class]'))
6、获取属性值
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
#注意class=item-0 active是一个class的属性,但是在pyquery里面要是中间也是空格隔开的话,
#就变成了item-0下的active标签下的a标签了,所以这里空格必须改成点
item = doc(".item-0.active a")
print(type(item))
print(item)
#获取属性值的两种方法
print(item.attr.href)
print(item.attr('href'))
<class 'pyquery.pyquery.PyQuery'>
<a href="link3.html"><span class="bold">third item</span></a>
link3.html
link3.html
运行结果
7、获取标签的内容
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
a = doc("a").text()
print(a)
#结果很有趣,他是找到所有标签的值,然后给连到一起打出来,就像一段话
second item third item fourth item fifth item
运行结果
8、Dom操作
1、属性的增加删除操作
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
li = doc('.item-0.active')
print(li)
#删除classactive
print(li.removeClass('active'))
#增加class属性haha
print(li.addClass('haha'))
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 haha"><a href="link3.html"><span class="bold">third item</span></a></li>
运行结果
2、attrs和css
注意:下列操作有则改之,无则加之。
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.attr('id','id_test'))
print(li.css('font-size','20px'))
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 active" id="id_test"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 active" id="id_test" style="font-size: 20px"><a href="link3.html"><span class="bold">third item</span></a></li>
运行结果
3、删除某个标签,在爬去过程中我们通常爬去一下标签或者内容下来的时候总会有些不想要的标签,这个时候我们可以用下面的类似方法删除这个标签。
from pyquery import PyQuery as pq html = '''<div class='content'>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
data = doc('.content')
print(data.text())
#删除所有a标签
data.find('a').remove()
#再次打印
print(data.text())
first item second item third item fourth item fifth item
first item
运行结果
python爬虫之PyQuery的基本使用的更多相关文章
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- python爬虫神器PyQuery的使用方法
你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有了一些 ...
- python爬虫之pyquery学习
相关内容: pyquery的介绍 pyquery的使用 安装模块 导入模块 解析对象初始化 css选择器 在选定元素之后的元素再选取 元素的文本.属性等内容的获取 pyquery执行DOM操作.css ...
- 【Python爬虫】PyQuery解析库
PyQuery解析库 阅读目录 初始化 基本CSS选择器 查找元素 遍历 获取信息 DOM操作 伪类选择器 PyQuery 是 Python 仿照 jQuery 的严格实现.语法与 jQuery 几乎 ...
- Python爬虫之pyquery库的基本使用
# 字符串初始化 html = ''' <div> <ul> <li class = "item-0">first item</li> ...
- Python爬虫系列-PyQuery详解
强大又灵活的网页解析库.如果你觉得正则写起来太麻烦,如果你觉得BeautifulSoup语法太难记,如果你熟悉jQuery的语法,那么PyQuery就是你的最佳选择. 安装 pip3 install ...
- python爬虫之PyQuery
# -*- coding: UTF-8 -*- from pyquery import PyQuery as pq import re from datetime import datetime,ti ...
- Python爬虫利器六之PyQuery的用法
前言 你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有 ...
- 小白学 Python 爬虫(23):解析库 pyquery 入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- js按照特定的中文字进行排序的方法
之前遇到过按照中文字符排序的需求很顺利的解决了,这次是按照特定的中文字进行排序,比如按照保守型,稳健型,平衡型,成长型,进取型进行排序. 可以使用localeCompare() 方法来实现中文按照拼音 ...
- UVA11584-Partitioning by Palindromes(动态规划基础)
Problem UVA11584-Partitioning by Palindromes Accept: 1326 Submit: 7151Time Limit: 3000 mSec Problem ...
- java 生成txt文件
FileWriter fileWriter = new FileWriter("C:/Users/li/Desktop/a.txt"); fileWriter.write(“aaa ...
- 上下文管理协议with open as
我们知道在操作文件对象的时候可以这么写 with open('a.txt') as f: '代码块' 上述叫做上下文管理协议,即with语句,为了让一个对象兼容with语句,必须在这个对象的类中声明_ ...
- Spring Security(十一):4. Samples and Guides (Start Here)
If you are looking to get started with Spring Security, the best place to start is our Sample Applic ...
- sk_buff Structure
The structure has changed many times in the history of the kernel,both to add new options and to reo ...
- 外部python脚本调用django 手动清理session
调试orm 在django项目根目录下创建文件test_orm.py,它和manage.py是同级的 import os if __name__ == "__main__": # ...
- 性能调优2:CPU
关系型数据库严重依赖底层的硬件资源,CPU是服务器的大脑,当CPU开销很高时,内存和硬盘系统都会产生不必需要的压力.CPU的性能问题,直观来看,就是任务管理器中看到的CPU利用率始终处于100%,而侦 ...
- ASP.Net Core 中使用Zookeeper搭建分布式环境中的配置中心系列一:使用Zookeeper.Net组件演示基本的操作
前言:马上要过年了,祝大家新年快乐!在过年回家前分享一篇关于Zookeeper的文章,我们都知道现在微服务盛行,大数据.分布式系统中经常会使用到Zookeeper,它是微服务.分布式系统中必不可少的分 ...
- java中的代码块是什么意思,怎么用
代码块是一种常见的代码形式.他用大括号“{}”将多行代码封装在一起,形成一个独立的代码区,这就构成了代码块.代码块的格式如下: 方法/步骤 普通代码块:是最常见的代码块,在方法里用一对“{ ...