Spark源码剖析 - SparkContext的初始化(七)_TaskScheduler的启动
7. TaskScheduler的启动
第五节介绍了TaskScheduler的创建,要想TaskScheduler发挥作用,必须要启动它,代码:

TaskScheduler在启动的时候,实际调用了backend的start方法,即同时启动了backend。local模式下,这里的backend是localSchedulerBackend。在TaskScheduler初始化时传入localSchedulerBackend。以LocalSchedulerBackend为例,启动LocalSchedulerBackend时向RpcEnv注册了LocalEndpoint。
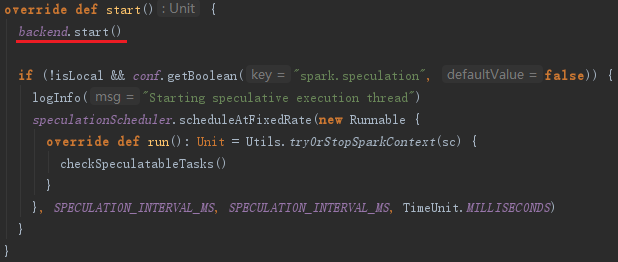
7.1 创建LocalEndpoint
创建LocalEndpoint的过程主要是构建本地的Executor,见代码如下:
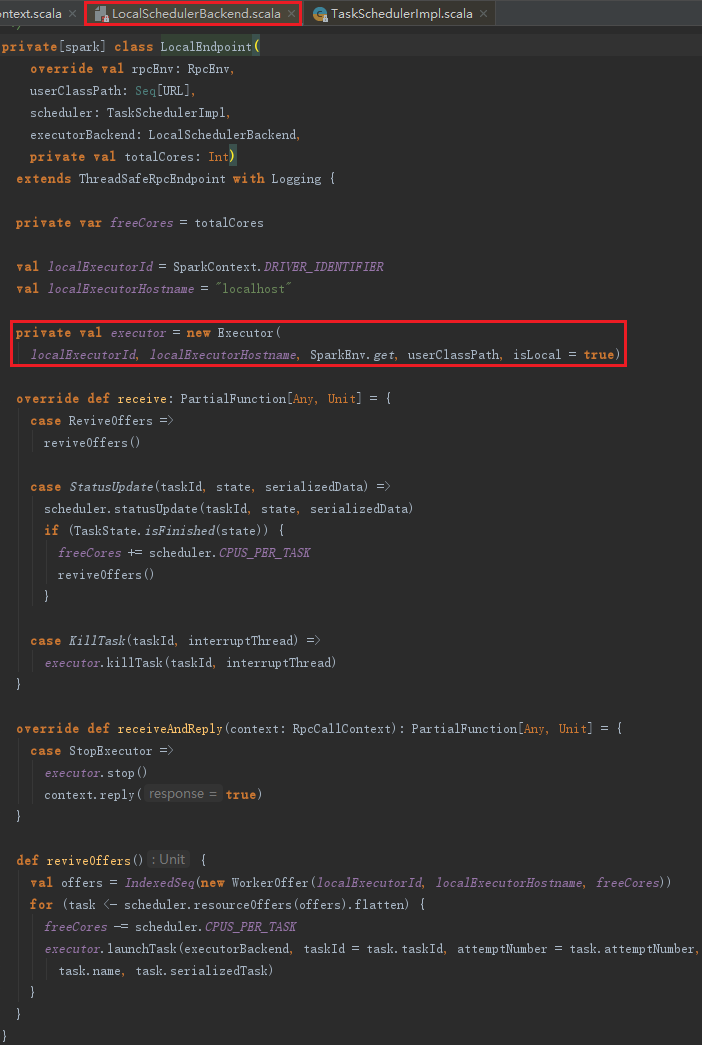
Executor的构建,主要包括以下步骤:
1) 创建并注册ExecutorSource。
2) 获取SparkEnv。如果是非local模式,Worker上的CoarseGrainedExecutorBackend向Driver上的CoarseGrainedExecutorBackend注册Executor时,则需要新建SparkEnv。可以修改属性spark.executor.port(默认为0,表示随机生成)来配置Executor中的RpcEnv的端口号。
3) urlClassLoader的创建。为什么需要创建这个ClassLoader?在非local模式中,Driver或者Worker上都会有多个Executor,每个Executor都设置自身的urlClassLoader,用于加载任务上传的jar包中的类,有效对任务的类加载环境进行隔离。
4) 创建Executor执行Task的线程池threadPool。此线程池用于执行任务。
5) 启动Executor的心跳线程heartbeater。此线程用于向Driver发送心跳。
此外,还包括Rpc发送消息的帧大小(10485760字节)、结果总大小的字节限制(1073741824字节)、正在运行的task的列表、设置serializer的默认ClassLoader为创建的ClassLoader等。
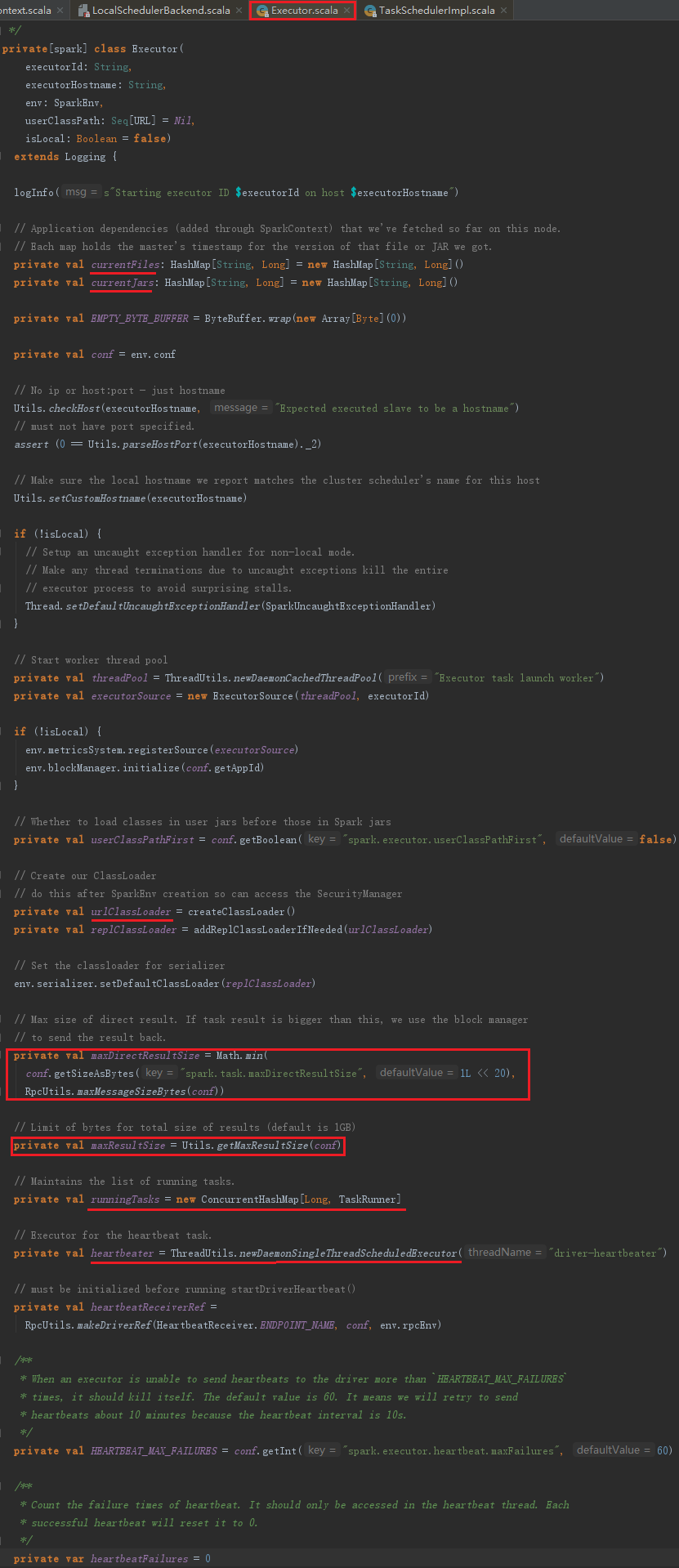
7.2 ExecutorSource的创建与注册
ExecutorSource用于测量系统。通过metricRegistry的register方法注册计量,这些计量信息包括threadpool.activeTasks、threadpool.completeTasks、threadpool.currentPool_size、threadpool.maxPool_size、filesystem.hdfs.write_bytes、filesystem.hdfs.read_ops、filesystem.file.write_bytes、filesystem.hdfs.largeRead_ops、filesystem.hdfs.write_ops等,ExecutorSource的实现见代码:
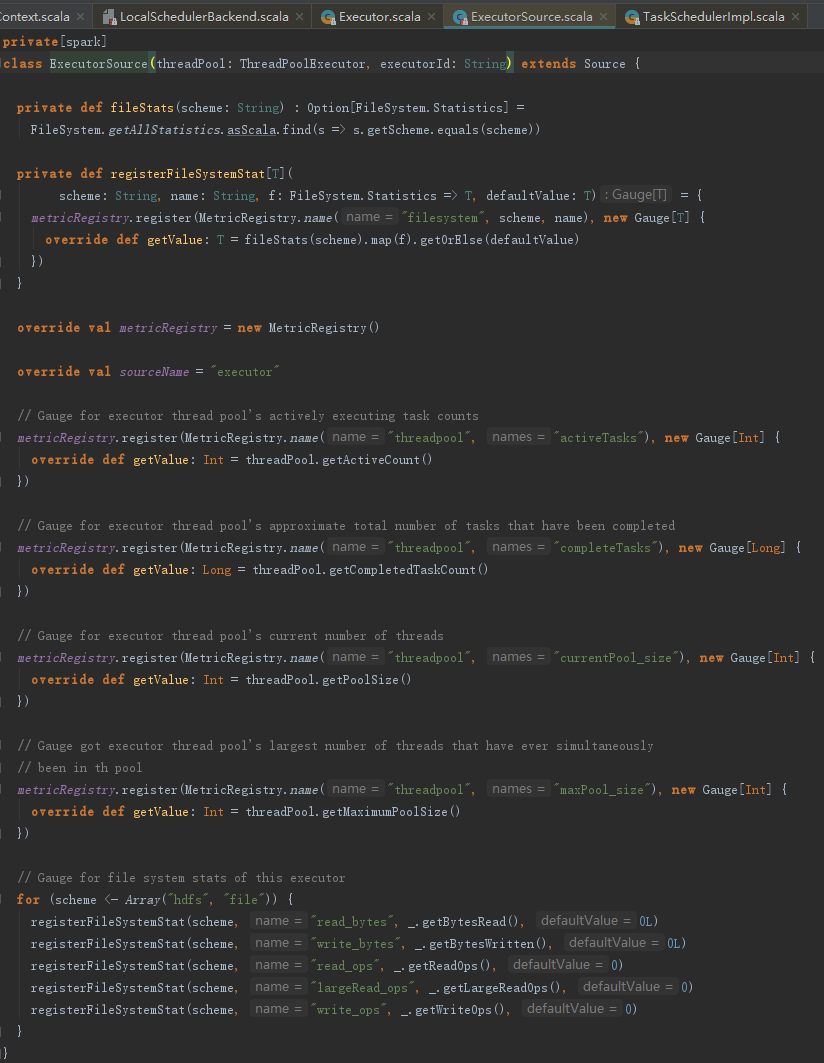
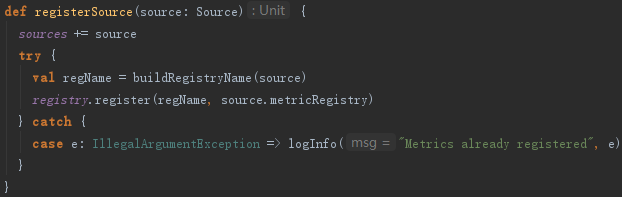
创建完ExecutorSource后,调用MetricsSystem的registerSource方法将ExecutorSource注册到MetricsSystem。registerSource方法使用MetricRegistry的register方法,将source注册到MetricRegistry,见代码:
7.3 Spark自身urlClassLoader的创建
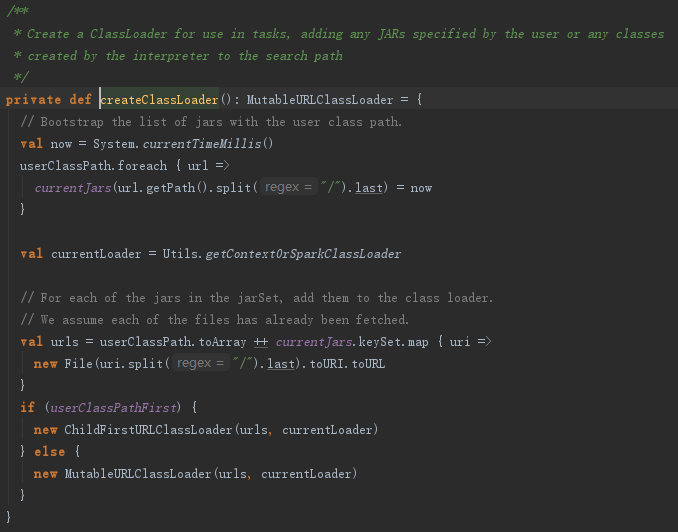
获取要创建的ClassLoader的父加载器currentLoader,然后根据currentJars生成URL数组,spark.files.userClassPathFirst属性指定加载类时是否先从用户的classpath下加载,最后创建ExecutorURLClassLoader或者ChildExecutorURLClassLoader,见代码:

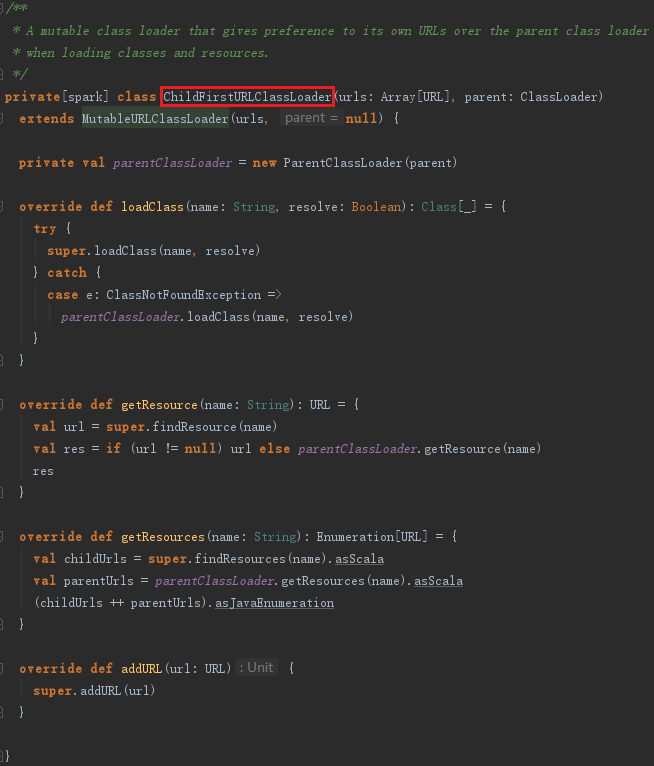
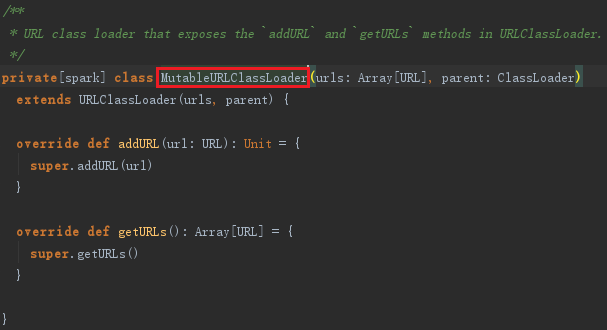
MutableURLClassLoader或者ChildFirstURLClassLoader实际上都继承了URLClassLoader,见代码:
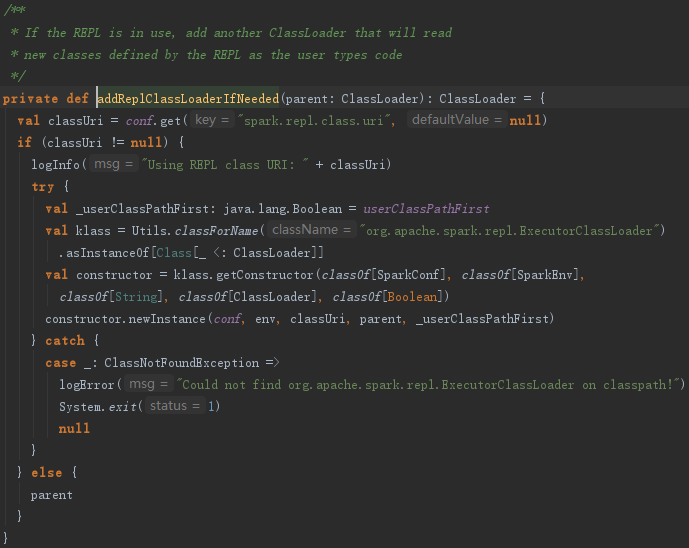
如果需要REPL交互,还会调用addReplClassLoaderIfNeeded创建replClassLoader,见代码:
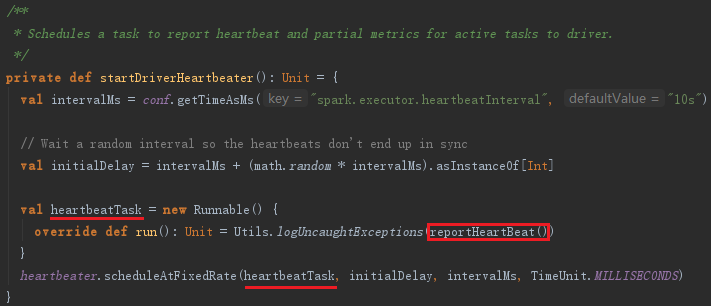
7.4 启动Executor的心跳线程
Executor的心跳由startDriverHeartbeater启动。Executor心跳线程的间隔由属性spark.executor.heartbeatInterval配置,默认是10000毫秒。此外,超时时间是30秒,超时重试次数是3次,重试间隔是3000毫秒。此线程从runningTasks获取最新的有关Task的测量信息,将其与executorId、blockManagerId封装为Heartbeat消息,向HearbeatReceiverRef发送Heartbeat消息。
这个心跳线程的作用是什么呢?其作用有两个:
- 更新正在处理的任务的测量信息;
- 通知BlockManagerMaster,此Executor上的BlockManager依然活着。
下面对心跳线程的实现详细分析下:
初始化TaskSchedulerImpl后会创建心跳接收器HeartbeatReceiver。HeartbeatReceiver接收所有分配给当前Driver Application的Executor的心跳,并将Task、Task计量信息、心跳等交给TaskSchedulerImpl和DAGScheduler作进一步处理。创建心跳接收器的代码如下:

HeartbeatReceiver在收到心跳信息后,会调用TaskScheduler的executorHeartbeatReceived方法,代码如下:
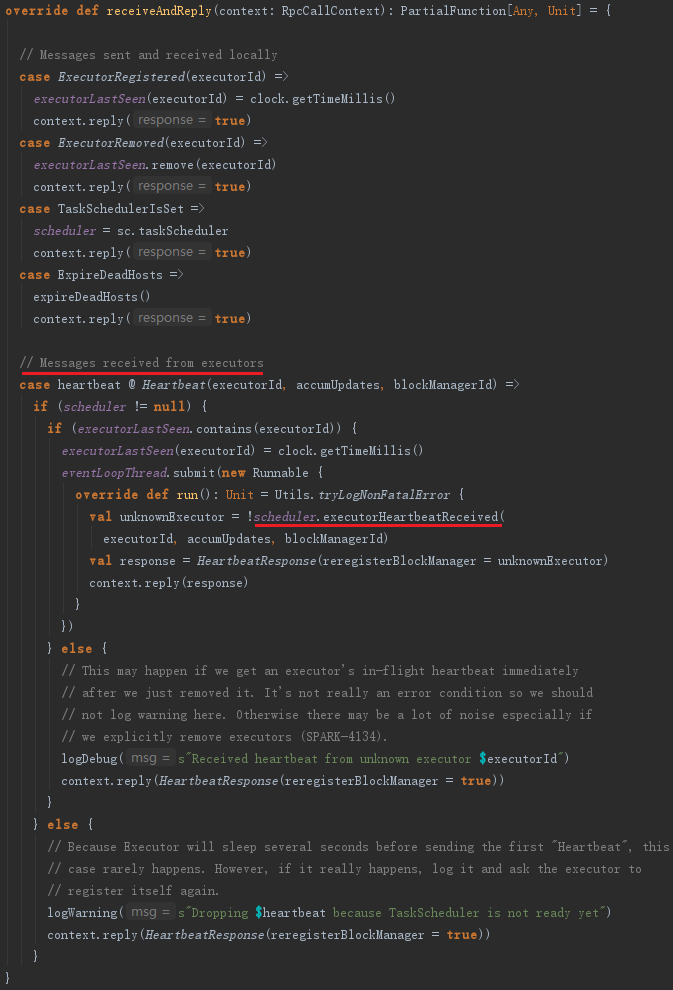
executorHeartbeatReceived的实现代码如下:
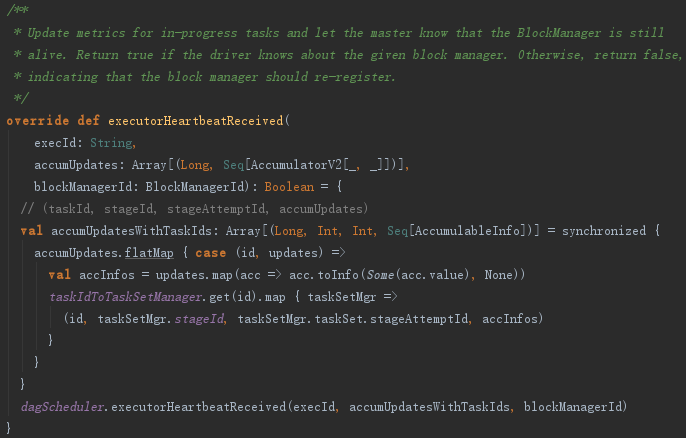
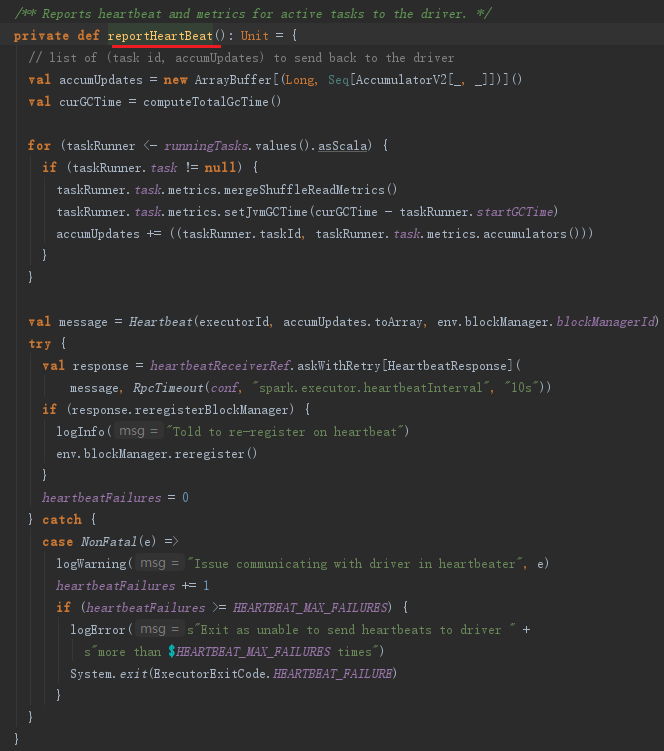
这段程序通过遍历accumUpdates,依据taskIdToTaskSetId找到TaskSetManager。然后将taskId、TaskSetManager.stageId、TaskSetManager.taskSet.stageAttemptId、accInfos封装到类型为Array[(Long, Int, Int,Seq[AccumulableInfo])]的数组accumUpdatesWithTaskIds中。最后调用了dagScheduler的executorHeartbeatReceived方法,其实现如下:
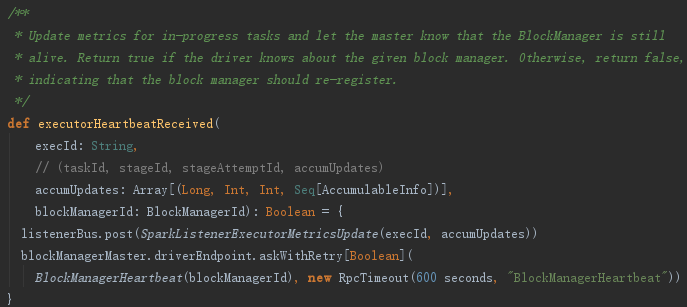
dagScheduler将executorId、accumUpdates封装为SparkListenerExecutorMetricsUpdate事件,并post到listenerBus中,此事件用于更新Stage的各种测量数据。最后给BlockManagerMaster持有的BlockManagerMasterEndpoint发送BlockManagerHeartbeat消息。BlockManagerMasterEndpoint在接收到消息后会匹配执行heartbeatReceived方法。heartbeatReceived最终更新BlockManagerMaster对BlockManager的最后可见时间(即更新BlockManagerId对应的BlockManagerInfo的_lastSeenMs)。
Spark源码剖析 - SparkContext的初始化(七)_TaskScheduler的启动的更多相关文章
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
- Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI 任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单.高效的方式.SparkUI就是这样的服务. 在大型分布式系统中,采用 ...
- Spark源码剖析 - SparkContext的初始化(十)_Spark环境更新
12. Spark环境更新 在SparkContext的初始化过程中,可能对其环境造成影响,所以需要更新环境,代码如下: SparkContext初始化过程中,如果设置了spark.jars属性,sp ...
- Spark源码剖析 - SparkContext的初始化(一)
1. SparkContext概述 注意:SparkContext的初始化剖析是基于Spark2.1.0版本的 Spark Driver用于提交用户应用程序,实际可以看作Spark的客户端.了解Spa ...
- Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler
5. 创建任务调度器TaskScheduler TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度.TaskScheduler也可以看作 ...
- Spark源码剖析 - SparkContext的初始化(八)_初始化管理器BlockManager
8.初始化管理器BlockManager 无论是Spark的初始化阶段还是任务提交.执行阶段,始终离不开存储体系.Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息.计算结 ...
- Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem
9. 启动测量系统MetricsSystem MetricsSystem使用codahale提供的第三方测量仓库Metrics.MetricsSystem中有三个概念: Instance:指定了谁在使 ...
- Spark源码剖析 - SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量
4. Hadoop相关配置及Executor环境变量的设置 4.1 Hadoop相关配置信息 默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下: 获 ...
- Spark源码剖析 - SparkContext的初始化(六)_创建和启动DAGScheduler
6.创建和启动DAGScheduler DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stag ...
随机推荐
- How to intall and configure Haproxy on Centos
Install Haproxy CentOS/RHEL 5 , 32 bit:# rpm -Uvh http://dl.fedoraproject.org/pub/epel/5/i386/epel-r ...
- hihoCoder #1646 : Rikka with String II(容斥原理)
题意 给你 \(n\) 个 \(01\) 串 \(S\) ,其中有些位置可能为 \(?\) 表示能任意填 \(0/1\) .问对于所有填法,把所有串插入到 \(Trie\) 的节点数之和(空串看做根节 ...
- 【BZOJ4868】[六省联考2017]期末考试(贪心)
[BZOJ4868][六省联考2017]期末考试(贪心) 题面 BZOJ 洛谷 题解 显然最终的答案之和最后一个公布成绩的课程相关. 枚举最后一天的日期,那么维护一下前面有多少天可以向后移,后面总共需 ...
- pip 安装第三方包提示Unknown or unsupported command 'install'
Unknown or unsupported command 'install' Unknown or unsupported command 'show' Unknown or unsupporte ...
- jquery扩展写法
如何制作自己的Jquery插件,内容参考学习了网上的讲解,如下 使用这两个方法 jQuery.fn.extend(object) jQuery.extend(object) jQuery.extend ...
- semantic ui框架学习笔记三
网格系统 基本网格 <div class="ui grid"> <div class="column"></div> < ...
- surfer画世界频率分布图(等高线、地点标注)
以surfer 12版本为例: 1.下载世界地图,这里我随便提供一个范例(侵删,忘记出处了): 2.进入surfer软件,选择“MAP”——“NEW”——“BASE MAP”. 以此按照以上步骤,在弹 ...
- Java如何判断文件或者文件夹是否在?不存在如何创建?
Java如何判断文件或者文件夹是否在?不存在如何创建? 1. 首先明确一点的是:test.txt文件可以和test文件夹同时存在同一目录下:test文件不能和test文件夹同时存在同一目录下. 原 ...
- POJ 2449 Remmarguts' Date (第k短路径)
Remmarguts' Date Time Limit: 4000MS Memory Limit: 65536K Total Submissions:35025 Accepted: 9467 ...
- Java 引用数据类型
引用数据类型 * A: 数据类型 * a: java中的数据类型分为:基本类型和引用类型 * B: 引用类型的分类 * a: Java为我们提供好的类,比如说:Scanner,Random等. * C ...