Spark源码剖析 - SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量
4. Hadoop相关配置及Executor环境变量的设置
4.1 Hadoop相关配置信息
默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下:

获取的配置信息包括:
- 将Amazon S3文件系统的AccessKeyId和SecretAccessKey加载到Hadoop的Configuration;
- 将SparkConf中所有以spark.hadoop. 开头的属性都复制到Hadoop的Configuration;
- 将SparkConf的属性spark.buffer.size复制为Hadoop的Configuration的配置io.file.buffer.size;
注意:如果指定了SPARK_YARN_MODE属性,则会使用YarnSparkHadoopUtil,否则默认为SparkHadoopUtil。
4.2 Executor环境变量
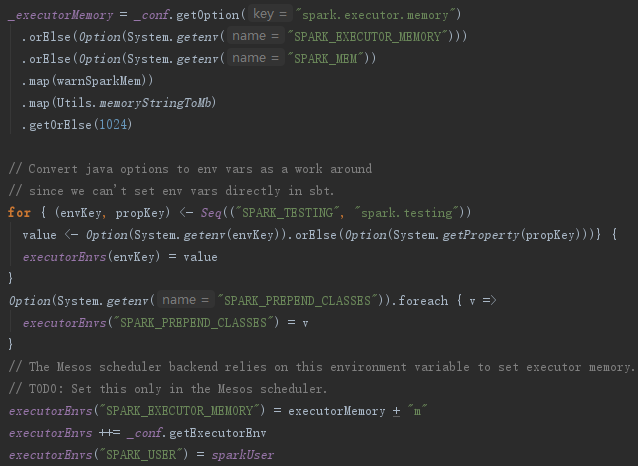
对Executor的环境变量的处理,见代码如下。executorEnvs包含的环境变量将会在注册应用的过程中发送给Master,Master给Worker发送调度后,Worker最终使用executorEnvs提供的信息启动Executor,可以通过配置spark.executor.memory指定Executor占用的内存大小,也可以配置系统变量SPARK_EXECUTOR_MEMORY或者SPARK_MEM对其大小进行设置。代码如下:
Spark源码剖析 - SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量的更多相关文章
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
- Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI 任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单.高效的方式.SparkUI就是这样的服务. 在大型分布式系统中,采用 ...
- Spark源码剖析 - SparkContext的初始化(一)
1. SparkContext概述 注意:SparkContext的初始化剖析是基于Spark2.1.0版本的 Spark Driver用于提交用户应用程序,实际可以看作Spark的客户端.了解Spa ...
- Spark源码剖析 - SparkContext的初始化(十)_Spark环境更新
12. Spark环境更新 在SparkContext的初始化过程中,可能对其环境造成影响,所以需要更新环境,代码如下: SparkContext初始化过程中,如果设置了spark.jars属性,sp ...
- Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem
9. 启动测量系统MetricsSystem MetricsSystem使用codahale提供的第三方测量仓库Metrics.MetricsSystem中有三个概念: Instance:指定了谁在使 ...
- Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler
5. 创建任务调度器TaskScheduler TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度.TaskScheduler也可以看作 ...
- Spark源码剖析 - SparkContext的初始化(八)_初始化管理器BlockManager
8.初始化管理器BlockManager 无论是Spark的初始化阶段还是任务提交.执行阶段,始终离不开存储体系.Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息.计算结 ...
- Spark源码剖析 - SparkContext的初始化(七)_TaskScheduler的启动
7. TaskScheduler的启动 第五节介绍了TaskScheduler的创建,要想TaskScheduler发挥作用,必须要启动它,代码: TaskScheduler在启动的时候,实际调用了b ...
- Spark源码剖析 - SparkContext的初始化(六)_创建和启动DAGScheduler
6.创建和启动DAGScheduler DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stag ...
随机推荐
- github 快速部署
在github上 新建一个项目后,并且未提交任何代码,会有一个页面提示我们如何快速部署.在此备份一下那个页面 Quick setup — if you’ve done this kind of thi ...
- 「POJ - 2318」TOYS (叉乘)
BUPT 2017 summer training (16) #2 A 题意 有一个玩具盒,被n个隔板分开成左到u右n+1个区域,然后给每个玩具的坐标,求每个区域有几个玩具. 题解 依次用叉积判断玩具 ...
- 【题解】 bzoj2982: combination (Lucas定理)
题面戳我 Solution 板子题 Code //It is coded by ning_mew on 7.25 #include<bits/stdc++.h> #define LL lo ...
- 【LOJ#6029】市场(线段树)
[LOJ#6029]市场(线段树) 题面 LOJ 题解 看着就是一个需要势能分析的线段树. 不难发现就是把第二个整除操作化为减法. 考虑一下什么时候整除操作才能变成减法. 假设两个数为\(a,b\). ...
- rt-thread是如何做到通过menuconfig配置将相应文件加入工程和从工程中除去
@2019-01-25 [小记] 添加与删除文件的机制是: menuconifg 所显示的菜单是由一系列 Kconfig 文件构成的,这些菜单实际就是一系列的宏控制,而这些宏又控制着一系列的 SCon ...
- JMeter5.1企业级应用应用常用功能详解(含插件安装)
apache jmeter是100%的java桌面应用程序,它被设计用来加载被测试软件功能特性.度量被测试软件的性能.jmeter可以模拟大量的服务器负载,并且jmeter提供图形化的性能分析. JM ...
- 【git】git撤销与回滚
git的撤销与回滚在平时使用中还是比较多的,比如说我们想将某个修改后的文件撤销到上一个版本,或者是想撤销某次多余的提交,都要用到git的撤销和回滚操作.撤销分两种情况,一个是commit之前,一个是c ...
- 关于一些没做出来的SBCF题
这里是一些我SB没做出来的CF水题. 其实这些题思维量还不错,所以写在这里常来看看…… 不一定每题代码都会写. CF1143C Queen 其实只要注意到如果一个点开始能被删,那一直就能被删:一个点开 ...
- thinkphp5中__PUBLIC__的使用
在使用thinkphp5.1开发的时候遇到设置__PUBLIC__无法生效的问题.这次的版本升级有比较大的改动,很多写法已经被更改,下面说下怎么去解决这个问题. 工具/原料 phpstorm ln ...
- css 选择其父元素下的某个元素
一,选择器 :first-child p:first-child(first第一个 child子元素)(找第一个子元素为p) :last-child p:last-child(last倒数 ...