[机器学习]回归--Support Vector Regression(SVR)
SVM分类,就是找到一个平面,让两个分类集合的支持向量或者所有的数据(LSSVM)离分类平面最远;
SVR回归,就是找到一个回归平面,让一个集合的所有数据到该平面的距离最近。
SVR是支持向量回归(support vector regression)的英文缩写,是支持向量机(SVM)的重要的应用分支。
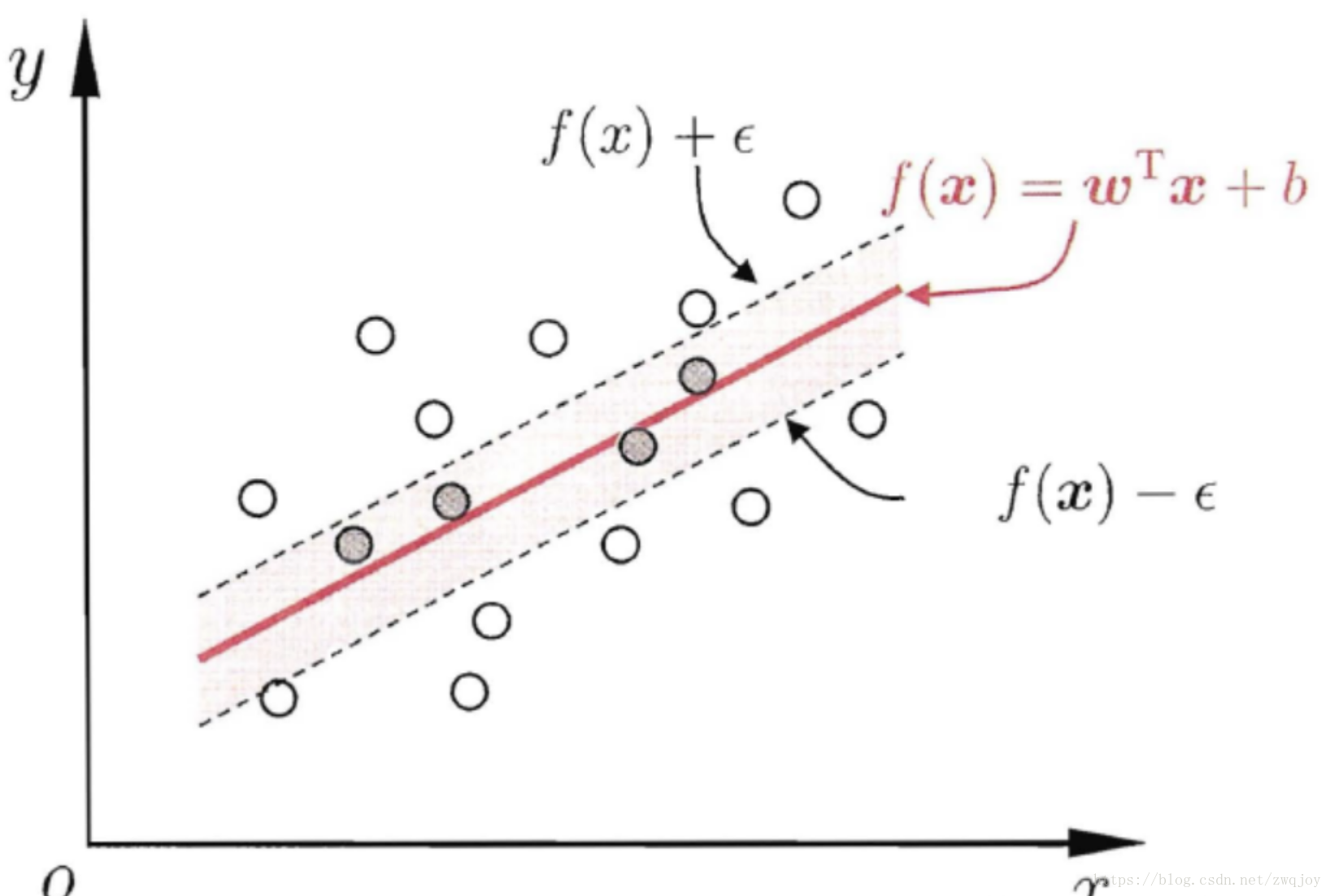
传统回归方法当且仅当回归f(x)完全等于y时才认为预测正确,如线性回归中常用(f(x)−y)2来计算其损失。
而支持向量回归则认为只要f(x)与y偏离程度不要太大,既可以认为预测正确,不用计算损失,具体的,就是设置阈值α,只计算|f(x)−y|>α的数据点的loss,如下图所示,阴影部分的数据点我们都认为该模型预测准确了,只计算阴影外的数据点的loss:
数据处理
preprocessing.scale()作用:
scale()是用来对原始样本进行缩放的,范围可以自己定,一般是[0,1]或[-1,1]。
缩放的目的主要是
1)防止某个特征过大或过小,从而在训练中起的作用不平衡;
2)为了计算速度。因为在核计算中,会用到内积运算或exp运算,不平衡的数据可能造成计算困难。
对于SVM算法,我们首先导入sklearn.svm中的SVR模块。SVR()就是SVM算法来做回归用的方法(即输入标签是连续值的时候要用的方法),通过以下语句来确定SVR的模式(选取比较重要的几个参数进行测试。随机选取一只股票开始相关参数选择的测试)。
svr = SVR(kernel=’rbf’, C=1e3, gamma=0.01)
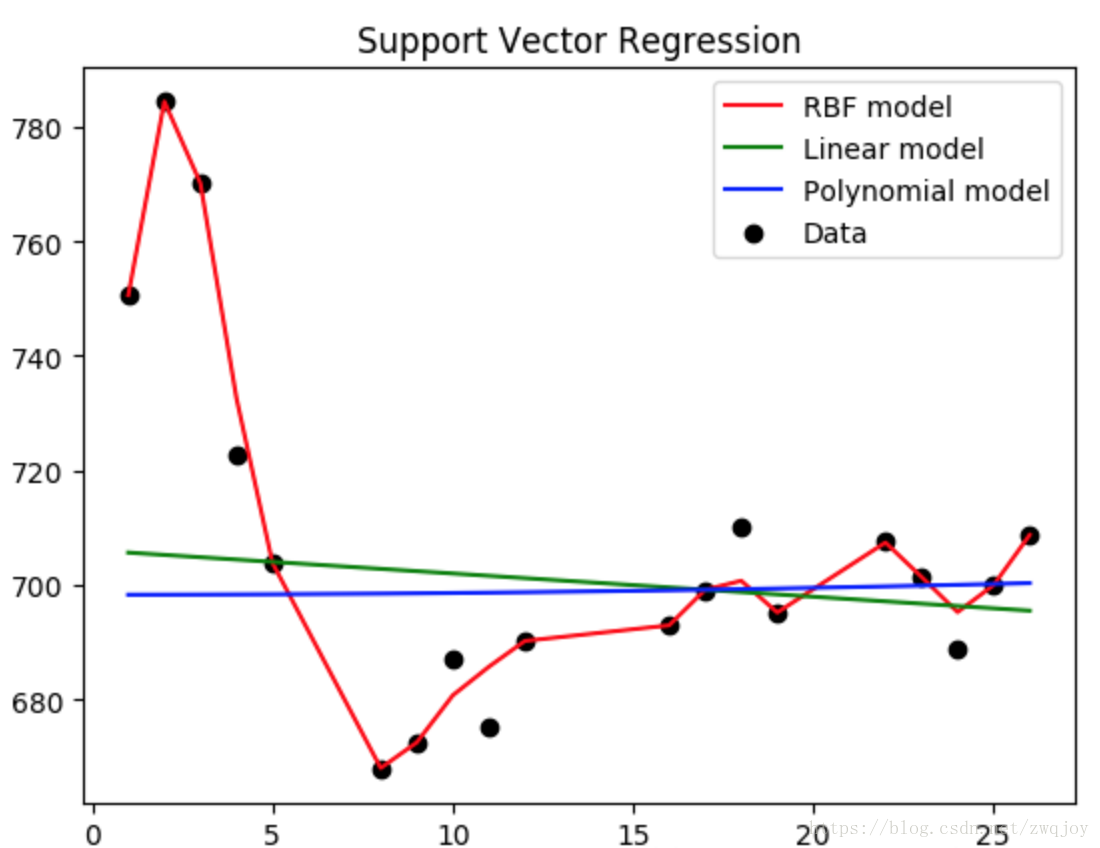
kernel:核函数的类型,一般常用的有’rbf’,’linear’,’poly’,等如图4-1-2-1所示,发现使用rbf参数时函数模型的拟合效果最好。
C:惩罚因子
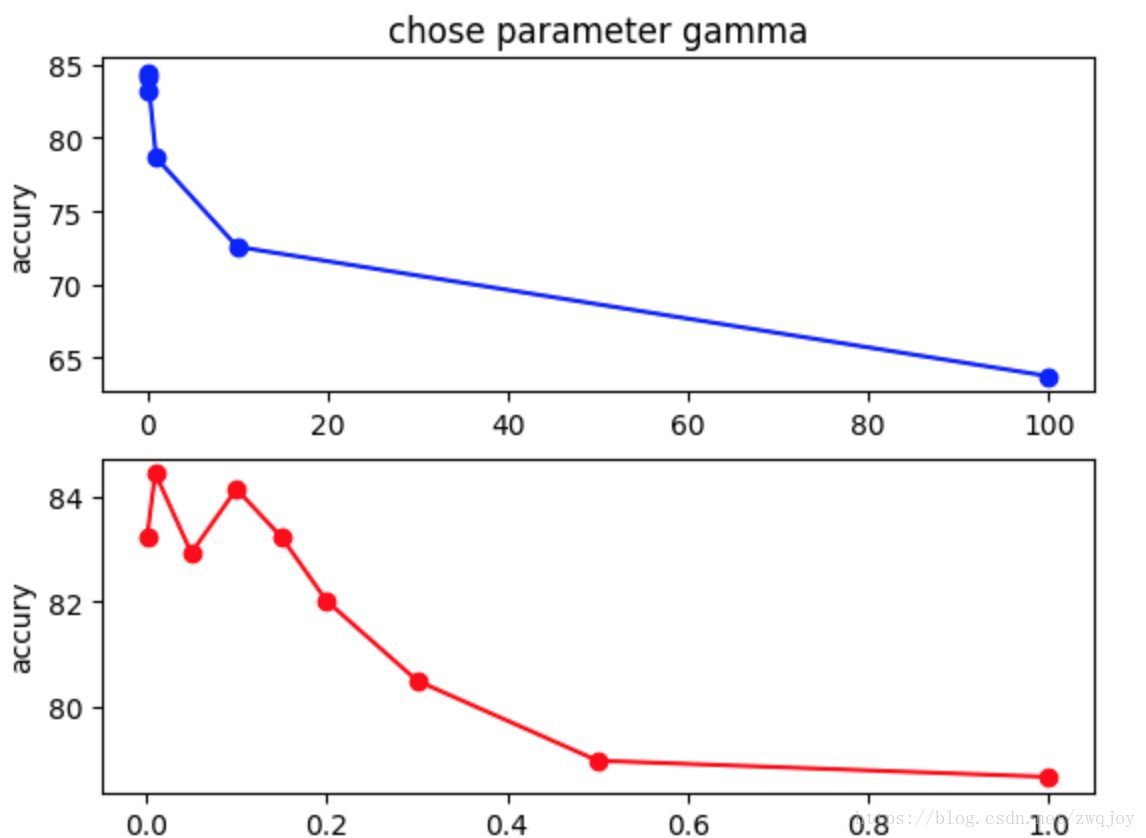
C表征你有多么重视离群点,C越大越重视,越不想丢掉它们。C值大时对误差分类的惩罚增大,C值小时对误差分类的惩罚减小。当C越大,趋近无穷的时候,表示不允许分类误差的存在,margin越小,容易过拟合;当C趋于0时,表示我们不再关注分类是否正确,只要求margin越大,容易欠拟合。如图所示发现当使用1e3时最为适宜。
gamma:
是’rbf’,’poly’和’sigmoid’的核系数且gamma的值必须大于0。随着gamma的增大,存在对于测试集分类效果差而对训练分类效果好的情况,并且容易泛化误差出现过拟合。如图发现gamma=0.01时准确度最高。
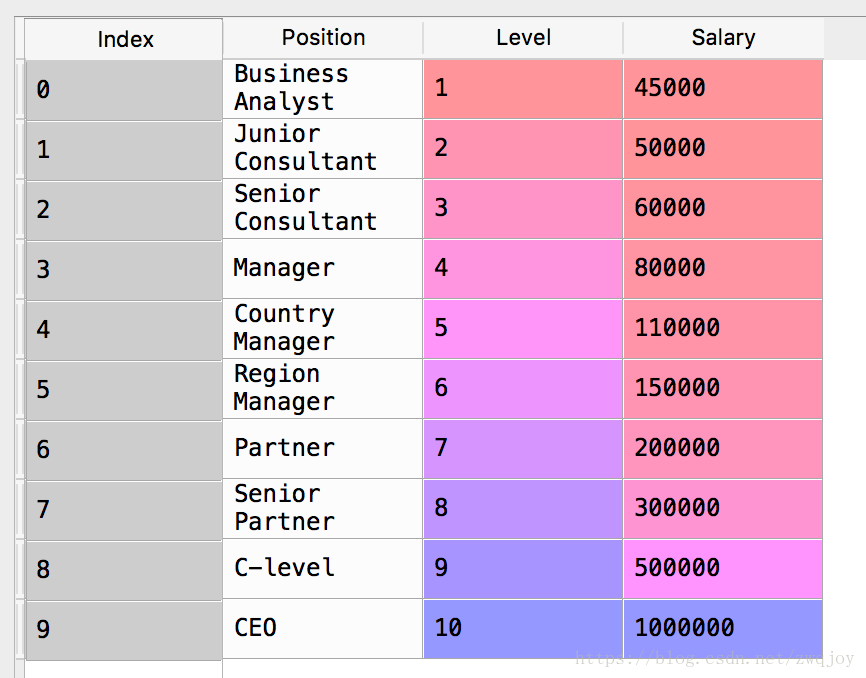
我们这次用的数据是公司内部不同的promotion level所对应的薪资
下面我们来看一下在Python中是如何实现的
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Position_Salaries.csv')
X = dataset.iloc[:, 1:2].values
# 这里注意:1:2其实只有第一列,与1 的区别是这表示的是一个matrix矩阵,而非单一向量。
y = dataset.iloc[:, 2].values接下来,处理数据:
# Reshape your data either using array.reshape(-1, 1) if your data has a single feature
# array.reshape(1, -1) if it contains a single sample.
X = np.reshape(X, (-1, 1))
y = np.reshape(y, (-1, 1))
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(X)
y = sc_y.fit_transform(y)
接下来,进入正题,开始SVR回归:
# Fitting SVR to the dataset
from sklearn.svm import SVR
regressor = SVR(kernel = 'rbf')
regressor.fit(X, y)
# Predicting a new result
y_pred = regressor.predict(sc_X.transform(np.array([[6.5]])))
# 转换回正常预测值
y_pred = sc_y.inverse_transform(y_pred)
# 图像中显示
plt.scatter(X, y, color = 'red')
plt.plot(X, regressor.predict(X), color = 'blue')
plt.title('Truth or Bluff (SVR)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
# Visualising the SVR results (for higher resolution and smoother curve)
X_grid = np.arange(min(X), max(X), 0.01) # choice of 0.01 instead of 0.1 step because the data is feature scaled
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = 'red')
plt.plot(X_grid, regressor.predict(X_grid), color = 'blue')
plt.title('Truth or Bluff (SVR)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()

[机器学习]回归--Support Vector Regression(SVR)的更多相关文章
- 机器学习技法:06 Support Vector Regression
Roadmap Kernel Ridge Regression Support Vector Regression Primal Support Vector Regression Dual Summ ...
- 机器学习技法笔记:06 Support Vector Regression
Roadmap Kernel Ridge Regression Support Vector Regression Primal Support Vector Regression Dual Summ ...
- [Scikit-learn] 1.4 Support Vector Regression
SVM算法 既可用于回归问题,比如SVR(Support Vector Regression,支持向量回归) 也可以用于分类问题,比如SVC(Support Vector Classification ...
- 翻译——2_Linear Regression and Support Vector Regression
续上篇 1_Project Overview, Data Wrangling and Exploratory Analysis 使用不同的机器学习方法进行预测 线性回归 在这本笔记本中,将训练一个线性 ...
- support vector regression与 kernel ridge regression
前一篇,我们将SVM与logistic regression联系起来,这一次我们将SVM与ridge regression(之前的linear regression)联系起来. (一)kernel r ...
- 【Support Vector Regression】林轩田机器学习技法
上节课讲了Kernel的技巧如何应用到Logistic Regression中.核心是L2 regularized的error形式的linear model是可以应用Kernel技巧的. 这一节,继续 ...
- [机器学习]回归--Decision Tree Regression
CART决策树又称分类回归树,当数据集的因变量为连续性数值时,该树算法就是一个回归树,可以用叶节点观察的均值作为预测值:当数据集的因变量为离散型数值时,该树算法就是一个分类树,可以很好的解决分类问题. ...
- 【机器学习】从SVM到SVR
注:最近在工作中,高频率的接触到了SVM模型,而且还有使用SVM模型做回归的情况,即SVR.另外考虑到自己从第一次知道这个模型到现在也差不多两年时间了,从最开始的腾云驾雾到现在有了一点直观的认识,花费 ...
- [Scikit-learn] 1.4 Support Vector Machines - Linear Classification
Outline: 作为一种典型的应用升维的方法,内容比较多,自带体系,以李航的书为主,分篇学习. 函数间隔和几何间隔 最大间隔 凸最优化问题 凸二次规划问题 线性支持向量机和软间隔最大化 添加的约束很 ...
随机推荐
- Linux学习---内存分布基础
内核空间 应用程序不允许访问 -----------------------------------------3G 栈空间 局部变量 RW ----------------------------- ...
- 实现PHP服务端和c#客户端数据交换
服务端实现功能1,数据库的访问dbhelper.php包括执行语句返回多行,返回json数据,返回单条记录,返回第一行第一列的整数,返回第一行第一列的浮点数,返回第一行第一列的双精度数,返回第一行第一 ...
- java模板设计模式
1.概述 模板设计模式定义:定义一个操作中的算法骨架,将步骤延迟到子类中. 模板设计模式是一种行为设计模式,一般是准备一个抽象类,将部分逻辑以具体方法或者具体的构造函数实现,然后声明一些抽象方法,这样 ...
- Redis各种数据类型的应用场景
redis是一种key values形式的非关系型数据库,通过内存存储,也可以把数据持久化到本地文件中. redis支持丰富的数据类型,String,list,set,zset,hash,下面说一下各 ...
- Paper | 深度网络中特征的可迁移性
目录 1. 核心贡献 2. 实验设置 2.1. 任务设置 2.2. 网络设置 3. 实验结果 4. 启发 论文:How transferable are features in deep neural ...
- 用pyspider爬取并解析json字符串
获取堆糖网站所有用户的id 昵称及主页地址 #!/usr/bin/env python # -*- encoding: utf-8 -*- # Created on 2016-06-21 13:57: ...
- mysql-exporter
[1] https://blog.frognew.com/2017/08/use-prometheus-monitoring-mysql.html [2] http://www.ywnds.com/? ...
- git 创建项目
Command line instructions Git global setup git config --global user.name "quliangliang" gi ...
- 《python语言程序设计》_第二章笔记
#2.2_编写一个简单的程序 项目1: 设计:radius=20,求面积area? 程序: radius=20 #给变量radius复制area=radius*radius*3.14159 #编写ar ...
- Reids学习1 -- 初识Redis
1. Reids和其他类型数据库对比 名称 类型 数据库存储选项 查询类型 附加功能 Redis 使用内存存储的非关系数据库 字符串,列表,集和,散列表,有序集合 每个类型有自己的专属命令,还有批量操 ...