Learning Invariant Deep Representation for NIR-VIS Face Recognition
查找异质图像匹配的过程中,发现几篇某组的论文,都是关于NIR-VIS的识别问题,提到了许多处理异质图像的处理方法,网络结构和idea都很不错,记录其中一篇。
其余两篇:
Wasserstein CNN: Learning Invariant Features for NIR-VIS Face Recognition
A Light CNN for Deep Face Representation with Noisy Labels
摘要
VIS-NIR(可见光与近红外)面部识别仍然是异质图像识别中的挑战。本文只用一个网络来映射NIR和VIS图像至一个紧凑的欧式空间。网络的低级层仅仅在大规模VIS数据中训练。每个卷积层由简单的maxout operator实现。网络的高级层被划分为两个正交的子空间,分别包括模态不变身份信息(modality-invariant identity information)和模态变化光谱信息(modality-variant spectrum information)。我们的联合公式在训练时引导交替最小化方法得到深度表示,测试时高效计算异质数据。实验证明了在CASIA NIR-VIS 2.0面部识别数据中实现94 percent的正确率,仅仅有64D大小的表示,比之前低了58 percent的错误率。
1. 介绍
NIR图像提供了廉价且简单的方式来提高在低光照情况下的面部识别能力。对于光照变换没有VIS那么敏感,所以被广泛应用于安检等。在真实应用中,NIR往往需要和VIS一起使用,导致了两者之间的匹配问题。这个问题可称为:NIR-VIS 异质面部识别问题。
NIR与VIS属于不同光谱,自然有很大的外表差异。所以深度网络在VIS数据训练后不含有NIR光谱信息,所以无法很好的解决NIR问题。怎样利用大规模VIS面部数据来探索NIR和VIS面部模态不变表示值得思考。得益于网络数据,我们可以容易获得大量VIS面部数据,然而成对的NIR数据难以获得。怎样在小规模NIR-VIS数据中学习也是一个中心问题。
之前的NIR-VIS匹配方法经常利用trick来减轻外观差异,通过移除一些可能含有光谱信息的主子空间。Chen在2012提出面部外观由身份信息(identity information)和变化信息(variation information eg.,lighting,poses,expressions)组成。受启发于此,本文提出一个网络来学习Invariant Deep Representation (IDR)同时包含NIR和VIS人脸信息,利用一个单一网络来将NIR和VIS图像同时映射到一个压缩后的欧式空间,使得NIR和VIS图像在嵌入空间embedding space中可以直接对应到面部相似性。
我们的网络首先在大规模VIS数据中训练,卷积层和全连接由简化形式的maxout operator实现。 这个网络使得我们学习的到的表示对于类内个体变化很鲁棒。然后,网络底层固定,微调NIR数据。高层划分为两个正交子空间:模态不变身份信息(modality-invariant identity information)和模态变化光谱信息(modality-variant spectrum information)。这个正交限制和maxout operator在高层可以缩减参数空间,因此避免了在小的NIR-VIS数据集上的过拟合。本文提出的IDR达到了SOTA,贡献如下:
- 一个高效深度网络结构学习模态不变表示,交替最小化高效优化。这个结构可以自然结合之前的不变特征提取和子空间学习到一个统一网络。
- 两个正交子空间嵌入网络中来建模身份和光谱信息。使得可以提取压缩后的表示,减小了小数据中的过拟合问题。
- 在数据集CASIA NIR-VIS 2.0面部数据上以64维的表示达到SOTA。
2. 相关工作
许多工作提出来减轻异质图像的外观差异。大多数方法可以分为三类:image synthesis, subspace learning、invariant feature extraction。
1)Image synthesis
主要从一个模态合成面部图像到另一个模态使得异质图像可在同一距离空间比较。
2)subspace learning
学习映射异质数据到一个共同的空间。当前sota方法是通过移除一些主子空间成分来解决。
3)Invariant feature extraction
即寻找模态不变特征使得对光照鲁棒。传统方法较多。
尽管很多方法,NIR-VIS识别表现仍然很low。远不如VIS数据结果好。很少有dl方法处理NIR-VIS,所以本文用DL方法来解决。
3. Invariant Deep Representation
本节介绍子空间分解和不变性特征提取,来学习模态不变深度表示。

注意到移除光谱信息有助于提高NIR-VIS识别表现。我们进一步三个映射矩阵(W,P,见上图)来建模身份不变信息和不变光谱信息。所以特征表示可以表示如下:
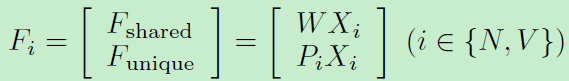
WX和PX分别代表共享特征和独立特征。考虑到子空间分解特性关于矩阵W和P:我们进一步提出一个正交限制使他们互相无关:
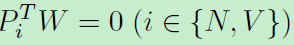
利用softmax函数来训练整个网络:

优化方法:
上式包含一些非凸变量,我们利用一种交替优化方法来最小化目标函数。首先根据朗格朗日乘子,重写上述函数:
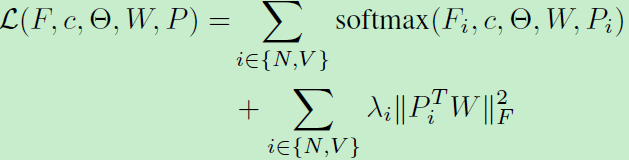
待优化参数有网络参数、W、P。利用交替优化更新,网络参数初始化利用Xavier,W和P初始化:
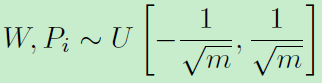
网络结构:lightened CNN B network(同作者另一作品:A Light CNN for Deep Face Representation with Noisy Labels)网络包括9个卷积层+4个最大池化层+全连接。Dropout设为0.7。初始学习率0.001,降到0.00001。基于该网络实现本文,特征层用来映射低级特征到两个正交子空间。
4. 其他要点
算法分析:分析本文提出的不变性深度表征: invariant deep representation (IDR)
我们实现了两种版本的IDR:DR表示IDR没有NIR特征和VIS特征。即仅仅训练卷积网络,没有子空间分解。这会导致大量参数在全连接和特征层,导致在小数据NIR-VIS上过拟合。特征层的maxout operator也有助于减少过拟合。因此,IDRm表示IDR没有maxout operator在特征层。
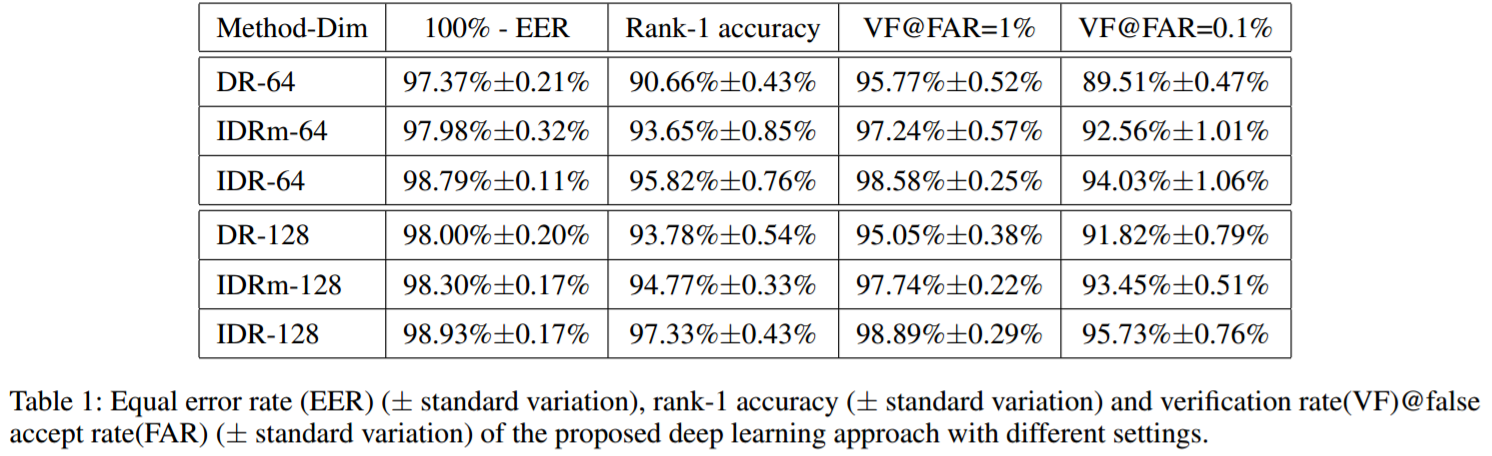
上图表明IDR是最好的结果。对比IDR和IDRm,注意到maxout operator在最后一个卷积层可进一步降低equal error rate,并提高表现。
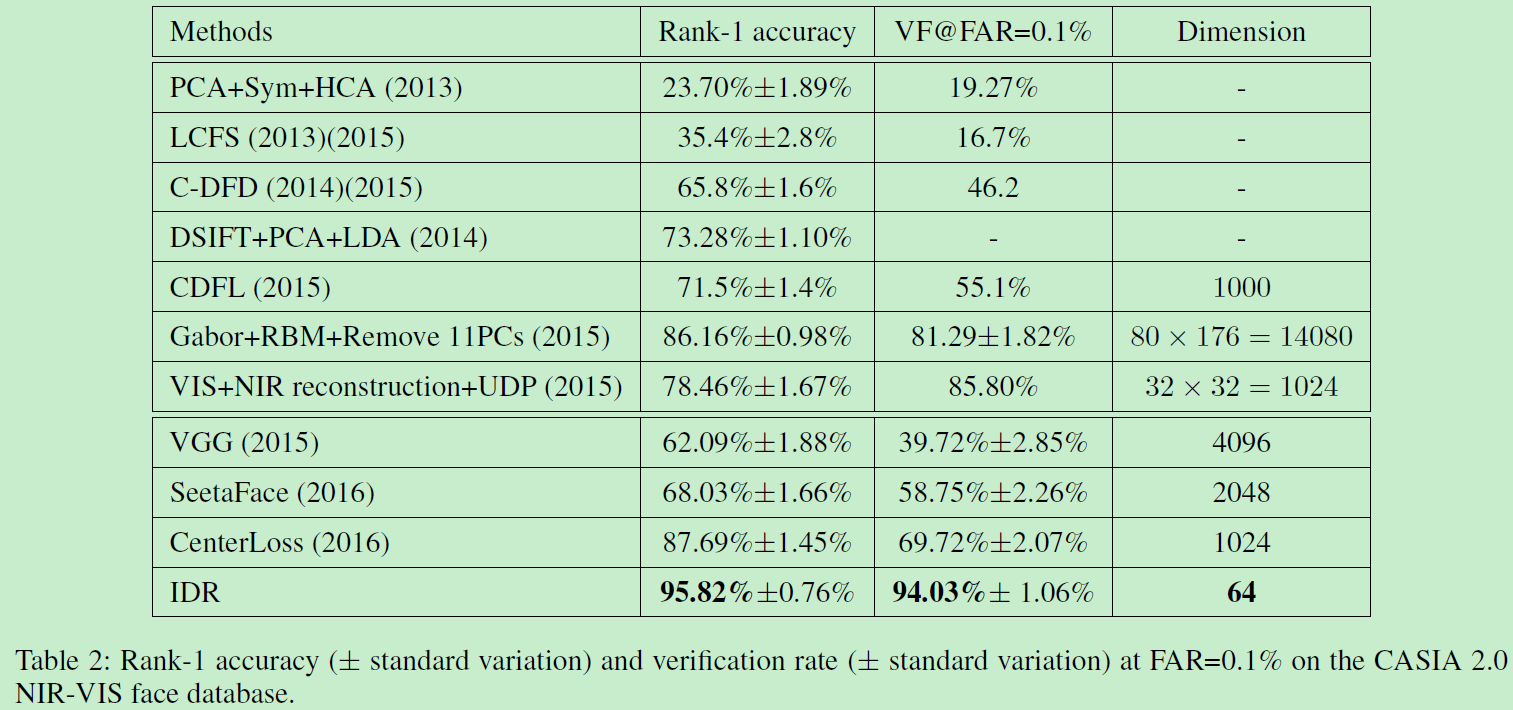
最后再附两张碾压性能图:

Learning Invariant Deep Representation for NIR-VIS Face Recognition的更多相关文章
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- Wasserstein CNN: Learning Invariant Features for NIR-VIS Face Recognition
承接上上篇博客,在其基础上,加入了Wasserstein distance和correlation prior .其他相关工作.网络细节(maxout operator).训练方式和数据处理等基本和前 ...
- (转)Understanding, generalisation, and transfer learning in deep neural networks
Understanding, generalisation, and transfer learning in deep neural networks FEBRUARY 27, 2017 Thi ...
- A Gentle Introduction to Transfer Learning for Deep Learning | 迁移学习
by Jason Brownlee on December 20, 2017 in Better Deep Learning Transfer learning is a machine learni ...
- [译]深度神经网络的多任务学习概览(An Overview of Multi-task Learning in Deep Neural Networks)
译自:http://sebastianruder.com/multi-task/ 1. 前言 在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI.为了达到这个目标,我 ...
- paper 124:【转载】无监督特征学习——Unsupervised feature learning and deep learning
来源:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio c ...
- 论文笔记之:Learning Cross-Modal Deep Representations for Robust Pedestrian Detection
Learning Cross-Modal Deep Representations for Robust Pedestrian Detection 2017-04-11 19:40:22 Moti ...
- 转:无监督特征学习——Unsupervised feature learning and deep learning
http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio clas ...
- Incentivizing exploration in reinforcement learning with deep predictive models
Stadie, Bradly C., Sergey Levine, and Pieter Abbeel. "Incentivizing exploration in reinforcemen ...
随机推荐
- Java开发中的编码分析__GET&POST
GET方式提交参数分析 code.jsp <%@ page language="java" contentType="text/html; charset=UTF- ...
- Java Web之EL
<%-- Created by IntelliJ IDEA. User: Vae Date: 2019/1/2 Time: 12:19 To change this template use F ...
- C语言复习---找出一个二维数组的鞍点
前提: 求任意的一个m×n矩阵的鞍点——鞍点是指该位置上的元素在该行上为最大.在该列上为最小, 矩阵中可能没有鞍点,但最多只有一个鞍点. m.n(<=m<=.<=n<=)及矩阵 ...
- 基于Asp.net C#实现HTML转图片(网页快照)
一.实现方法 //WebSiteThumbnail.cs文件,在BS项目中需要添加对System.Windows.Forms的引用 using System; using System.Data; u ...
- HDU - 6313 Hack It(构造)
http://acm.hdu.edu.cn/showproblem.php?pid=6313 题意 让你构造一个矩阵使得里面不存在四个顶点都为1的矩形,并且矩阵里面1的个数要>=85000 分析 ...
- sublime text3支持Vue文件高亮显示
sublime text 默认打开.vue文件全部都是白色的,不是特别方便.安装插件可以做到代码高亮显示 1.插件vue-syntax-highlight 下载地址:github https://gi ...
- 关于CPU的User、Nice、System、Wait、Idle各个参数的解释
使用Ganglia监控整个Hadoop集群,看到Ganglia采集的各种指标:CPU各个具体的指标含义解释如下: ①CPU(监测到的master主机上的CPU使用情况) 从图中看出,一共有五个关于CP ...
- List<string>序列化与反序列化一个小坑
Newtonsoft序列化与反序列化有两个重载方法,带<T>和不带<T>的 如果将一个List<String>序列化为jsonStr后,再反序列化,会变成JArra ...
- Linq中Sum和Group的使用
].AsEnumerable() group c by c.Field<int>("Name") into s select new { ID = s.Select(m ...
- vivalidi 一款由Web技术诞生的Web浏览器
vivalidi https://vivaldi.com/ A million ways to customize everything The world is a colorful place b ...