Feature Selection
两方面(发散,相关)~三方法(FWE)
F:方皮卡互
W:RFE
E:惩罚树
一、简介
我们的数据处理后,喂给算法之前,考虑到特征的实际情况,通常会从两个方面考虑来选择特征:
1)特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用
2)特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优先选择
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值选择特征
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征
- Embedded:集成法,先使用某些模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣
二、实践
1)Filter
a)方差法
使用方差法,要先计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
使用feature_selection库的VarianceThreshold类来选择特征的代码如下:
from sklearn.datasets import load_iris
from sklearn.feature_selection import VarianceThreshold iris = load_iris()
print(iris.data[0])
print(iris.target[0])
一个样本的数据和标签,如下:

而我们将方差阈值设置为3之后,保留方差大于3的特征:
print(VarianceThreshold(threshold=3).fit_transform(iris.data)[0])
结果:
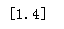
可见只有第三个特征满足方差大于3,被保留,注意:方差选择法,返回值为特征选择后的数据
b)皮尔逊系数
皮尔逊系数只能衡量线性相关性,先要计算各个特征对目标值的相关系数以及相关系数的P值。
用feature_selection库的SelectKBest类结合皮尔逊系数来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
from sklearn.datasets import load_iris
import numpy as np iris = load_iris() #选择K个最好的特征,返回选择特征后的数据 #第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量
#输出二元组(评分,P值)的数组
#数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
#参数k为选择的特征个数
def multivariate_pearsonr(X, y):
scores, pvalues = [], []
for ret in map(lambda x: pearsonr(x, y), X.T):
print(ret)
scores.append( abs(ret[0]) )
pvalues.append( ret[1] ) return (np.array(scores), np.array(pvalues)) transformer = SelectKBest( score_func = multivariate_pearsonr, k=2)
Xt_pearson = transformer.fit_transform( iris.data, iris.target)
print(Xt_pearson)

Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0
from scipy.stats import pearsonr
import numpy as np
x = np.random.uniform(-1, 1, 10000)
print( pearsonr(x, x**2) )
print( pearsonr(x, x**2)[0] )

c)卡方检验
在统计学中,卡方检验用来评价是两个事件是否独立,也就是$P(AB) = P(A)*P(B)$
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2 from sklearn.datasets import load_iris
iris = load_iris() SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
d)互信息
互信息是用来评价一个事件的出现对于另一个事件的出现所贡献的信息量
这里有通俗的理解(抛开公式):
原来我对X有些不确定(不确定性为H(X)),告诉我Y后我对X不确定性变为H(X|Y),这个不确定性的减少量就是X,Y之间的互信息I(X;Y)=H(X)-H(X|Y)。
互信息指的是两个随机变量之间的关联程度:即给定一个随机变量后,另一个随机变量不确定性的削弱程度,因而互信息取值最小为0,意味着给定一个随机变量对确定一另一个随机变量没有关系,最大取值为随机变量的熵,意味着给定一个随机变量,能完全消除另一个随机变量的不确定性
from sklearn.feature_selection import mutual_info_classif from sklearn.datasets import load_iris
iris = load_iris() SelectKBest(mutual_info_classif, k=2).fit_transform(iris.data, iris.target)
反过头来看\(y=x^2\)这个例子,MIC算出来的互信息值为1(最大的取值)
from minepy import MINE
m = MINE()
x = np.random.uniform(-1, 1, 100000)
m.compute_score(x, x**2)
print ( m.mic() )

2)Wrapper
a)递归特征消除法(Recursive Feature Elimination)
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris iris = load_iris()
RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target)
3)Embedded:集成法,先使用某些模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣
a)基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_iris iris = load_iris() SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
b)基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维
三、总结

Feature Selection的更多相关文章
- 【转】[特征选择] An Introduction to Feature Selection 翻译
中文原文链接:http://www.cnblogs.com/AHappyCat/p/5318042.html 英文原文链接: An Introduction to Feature Selection ...
- 单因素特征选择--Univariate Feature Selection
An example showing univariate feature selection. Noisy (non informative) features are added to the i ...
- 10-3[RF] feature selection
main idea: 计算每一个feature的重要性,选取重要性前k的feature: 衡量一个feature重要的方式:如果一个feature重要,则在这个feature上加上noise,会对最后 ...
- Feature Selection Can Reduce Overfitting And RF Show Feature Importance
一.特征选择可以减少过拟合代码实例 该实例来自机器学习实战第四章 #coding=utf-8 ''' We use KNN to show that feature selection maybe r ...
- highly variable gene | 高变异基因的选择 | feature selection | 特征选择
在做单细胞的时候,有很多基因属于noise,就是变化没有规律,或者无显著变化的基因.在后续分析之前,我们需要把它们去掉. 以下是一种找出highly variable gene的方法: The fea ...
- 机器学习-特征选择 Feature Selection 研究报告
原文:http://www.cnblogs.com/xbinworld/archive/2012/11/27/2791504.html 机器学习-特征选择 Feature Selection 研究报告 ...
- the steps that may be taken to solve a feature selection problem:特征选择的步骤
參考:JMLR的paper<an introduction to variable and feature selection> we summarize the steps that m ...
- The Practical Importance of Feature Selection(变量筛选重要性)
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
- [Feature] Feature selection
Ref: 1.13. Feature selection Ref: 1.13. 特征选择(Feature selection) 大纲列表 3.1 Filter 3.1.1 方差选择法 3.1.2 相关 ...
- [Feature] Feature selection - Embedded topic
基于惩罚项的特征选择法 一.直接对特征筛选 Ref: 1.13.4. 使用SelectFromModel选择特征(Feature selection using SelectFromModel) 通过 ...
随机推荐
- myclipse里有感叹号的问题,希望可以帮到各位
今天,我在myeclipse中导入一个项目的时候就发现一个问题:项目有红色感叹号,并且项目有红色错误提示.我首先看了这个红色错误提示的地方,发现这个根本不应该报错,想必是这个红色感叹号的原因. 于 ...
- HDU1890-Robotic Sort-Splay
#include <cstdio> #include <algorithm> #include <cstring> using namespace std; #de ...
- 洛谷P1983车站分级题解
题目 这个题非常毒瘤,只要还是体现在其思维难度上,因为要停留的车站的等级一定要大于不停留的车站的等级,因此我们可以从不停留的车站向停留的车站进行连边,然后从入度为0的点即不停留的点全都入队,然后拓扑排 ...
- 洛谷P1074 靶形数独(算竞进阶习题)
还是数独.. 比上一个多了个分数矩阵,其实没什么差别,但是数据好像水了许多... #include <bits/stdc++.h> #define INF 0x3f3f3f3f using ...
- 【XSY1098】第k小 可持久化trie
题目描述 给你一个长度为\(n\)数列\(a\),有\(m\)次操作: \(1~x\):把所有数异或\(x\) \(2~x\):把所有数与\(x\) \(3~x\):把所有数或\(x\) \(4~l~ ...
- springmvc返回xml格式、json格式数据
问:@ResponseBody注解怎么指定返回xml 还是json答:@RequestMapping 的produces 属性指定 produces = "application/xml&q ...
- Shell 字符截取命令 Cut
1.Cut 命令 # cut [选项] 文件名 选项 : -f 列号 提取第几列 -d 分隔符,按照指定分隔符分割列 2.例子 cut -f 1,4 -d ":" /etc/p ...
- stm32使用rt-thread在文件《stm32f1xx_hal.h》中头文件包含顺序引出的错误
@2019-01-24 [小记] 在学习 rt-thread BSP制作过程中,发现文件<stm32f1xx_hal.h>中 Env工具生成的原始顺序 1. #include " ...
- a span做成按钮样式不选中文字
a,span做成按钮样式时,文字会被选中.加以下CSS可以让其不选中.测试三大浏览器都可以 .button { display: inline-block; -moz-user-select: non ...
- ES6中箭头函数与普通函数this的区别
普通函数中的this: 1. this总是代表它的直接调用者, 例如 obj.func ,那么func中的this就是obj 2.在默认情况(非严格模式下,未使用 'use strict'),没找到直 ...