scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)
1.网页解析
当当网中,人工智能数据的首页url如下为http://category.dangdang.com/cp01.54.12.00.00.00.html

点击下方的链接,一次观察各个页面的url变化,发现每一页的url规律如下:在进行页面切换时除第一页外,其他页面的url变化规律为只有pg后的数字会随着页面的不同而变化,并且和页面数相同,我们就可以利用此规律,运用spider类来对每一个这样的页面信息进行爬取,并且符合此种规律的页面均可以按照同样的方式来爬取;
第1页:http://category.dangdang.com/cp01.54.12.00.00.00.html
第2页:http://category.dangdang.com/pg2-cp01.54.12.00.00.00.html
第3页:http://category.dangdang.com/pg3-cp01.54.12.00.00.00.html
第4页:http://category.dangdang.com/pg4-cp01.54.12.00.00.00.html
2. scrapy 具体实现代码
目标:爬取当当网上人工智能类数据的名称和价格,如下图:

2.1)项目结构:
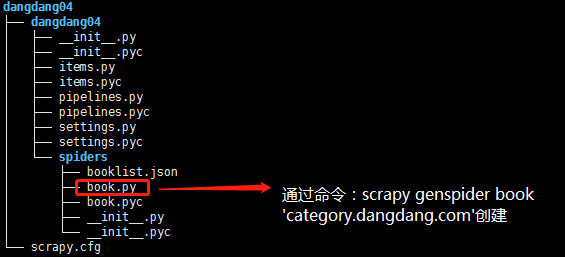
2.2)book.py代码
# -*- coding: utf-8 -*-
import scrapy
# 导入items中的类
from dangdang04.items import Dangdang04Item class BookSpider(scrapy.Spider):
name = "book"
allowed_domains = ["category.dangdang.com"]
url = 'http://category.dangdang.com/'
offset = 1
start_urls = [url + 'cp01.54.12.00.00.00.html'] def parse(self, response):
# 实例化类
item = Dangdang04Item()
# 定义提取规则,返回selector对象
book_list = response.xpath('//ul[@class="bigimg"]/li')
for book_info in book_list:
# 书的名称
item['name'] = book_info.xpath('./p[@class="name"]/a/@title').extract()[0]
# 书的价格
item['price'] = book_info.xpath('./p[@class="price"]/span[1]/text()').extract()[0]
yield item if self.offset < 80:
# 构建新的url再次发送请求
self.offset += 1
url = self.url + 'pg' + str(self.offset) + '-cp01.54.12.00.00.00.html'
yield scrapy.Request(url,callback=self.parse)
2.3)items.py代码
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class Dangdang04Item(scrapy.Item):
# 图书名称
name = scrapy.Field()
# 价格
price = scrapy.Field()
2.4)pipelines.py代码
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class Dangdang04Pipeline(object):
def __init__(self):
# 定义json文件,用于写入爬取的目标信息
self.filename = open('booklist.json','w')
def process_item(self, item, spider):
# 将item数据转换乘json格式数据
text = json.dumps(dict(item),ensure_ascii = False) + '\n'
# 将text数据写入本地文件中
self.filename.write(text.encode('utf-8'))
return item def close_spider(self,spider):
# 爬虫结束,关闭本地文件
self.filename.close()
2.5).settings.py文件对应设置
# user-agent设置
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'
# 下载延迟设置
DOWNLOAD_DELAY = 2.5
# 关键文件配置
ITEM_PIPELINES = {
'dangdang04.pipelines.Dangdang04Pipeline': 300,
}
scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)的更多相关文章
- scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)
scrapy项目3中已经对网页规律作出解析,这里用crawlspider类对其内容进行爬取: 项目结构与项目3中相同如下图,唯一不同的为book.py文件 crawlspider类的爬虫文件book的 ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- python爬虫06 | 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍
来啦,老弟 我们已经知道怎么使用 Requests 进行各种请求骚操作 也知道了对服务器返回的数据如何使用 正则表达式 来过滤我们想要的内容 ... 那么接下来 我们就使用 requests 和 re ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- python爬取返利网中值得买中的数据
先使用以前的方法将返利网的数据爬取下来,scrapy框架还不熟练,明日再战scrapy 查找目标数据使用的是beautifulsoup模块. 1.观察网页,寻找规律 打开值得买这块内容 1>分析 ...
- java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- 【转】java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- selenium自动化测试工具模拟登陆爬取当当网top500畅销书单
selenium自动化测试工具可谓是爬虫的利器,基本动态加载的网页都能抓取,当然随着大型网站的更新,也出现针对selenium的反爬,有些网站可以识别你是否用的是selenium访问,然后对你加以限制 ...
随机推荐
- springboot笔记-文件上传
使用 Spring Boot 和 Thymeleaf 上传文件 Spring Boot 利用 MultipartFile 的特性来接收和处理上传的文件,本示例前端页面使用 Thymeleaf 来处理. ...
- 利用BFS解决拯救007问题 -- 数据结构
题目: 7-1 拯救007 (30 分) 在老电影“007之生死关头”(Live and Let Die)中有一个情节,007被毒贩抓到一个鳄鱼池中心的小岛上,他用了一种极为大胆的方法逃脱 —— 直接 ...
- MyBatis时间排序问题
在数据中create_time字段是DateTime类型, 逆向工程后实体类中对应的成员变量类型为Date 时间排序代码为: 测试结果: 时间排序错乱. 解决方法: 1,在数据库创建varchar类型 ...
- Head First PHP&MySQl第四章代码
addemail.php <!DOCTYPE html> <html lang="cn" dir="ltr"> <head> ...
- 小白学习django第三站-自定义过滤器及标签
要使用自定义过滤器和标签,首先要设置好目录结构 现在项目目录下建立common的python包 再将common加入到setting.py中的INSTALLED_APP列表中 在common创建目录t ...
- PHP常用代码片段
/** * 高效判断远程文件是否存在 * @param $file * @return bool 存在返回 true 不存在或者其他原因返回false */ function remoteFileEx ...
- 在Windows与Ubuntu上使用tensorboard的不同点
(1)Ubuntu下使用TensorBoard如官网所述即可.https://www.tensorflow.org/programmers_guide/summaries_and_tensorboar ...
- git常用命令之log
查看提交日志记录 基础命令: git log commit ca82a6dff817ec66f44342007202690a93763949 Author: Scott Chacon < ...
- chrome插件2
转自:http://www.codeceo.com/article/15-chrome-extension.html 1. Web Developer 支持Chrome的Web Developer扩展 ...
- 关于Pandas中Dataframe的操作(一)
1.如何实现两个dataframe去重()? 假设df1是所有的数据,现在想去除与df2中重复的数据,也就是实现对df1进行操作,让他的数据不再包括df2. 方法一:先把需要剔除的df2的某一列(如i ...