防止过拟合的方法 预测鸾凤花(sklearn)
1. 防止过拟合的方法有哪些?
过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。
产生过拟合问题的原因大体有两个:训练样本太少或者模型太复杂。
防止过拟合问题的方法:
(1)增加训练数据。
考虑增加训练样本的数量
使用数据集估计数据分布参数,使用估计分布参数生成训练样本
使用数据增强
(2)减小模型的复杂度。
a.减少网络的层数或者神经元数量。这个很好理解,介绍网络的层数或者神经元的数量会使模型的拟合能力降低。
b.参数范数惩罚。参数范数惩罚通常采用L1和L2参数正则化(关于L1和L2的区别联系请戳这里)。
c.提前终止(Early stopping);
d.添加噪声。添加噪声可以在输入、权值,网络相应中添加。
e.结合多种模型。这种方法中使用不同的模型拟合不同的数据集,例如使用 Bagging,Boosting,Dropout、贝叶斯方法

而在深度学习中,通常解决的方法如下
Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。
获取更多数据(从数据源头获取更多数据 根据当前数据集估计数据分布参数,使用该分布产生更多数据 数据增强(Data Augmentation))
正则化(直接将权值的大小加入到 Cost 里,在训练的时候限制权值变大)
dropout:在训练时,每次随机(如50%概率)忽略隐层的某些节点;
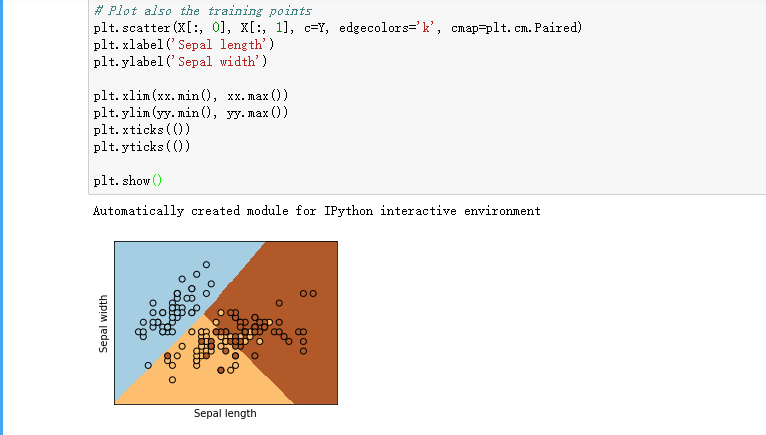
2. 使用逻辑回归(Logistic Regression)对鸢尾花数据(多分类问题)进行预测,可以直接使用sklearn中的LR方法,并尝试使用不同的参数,包括正则化的方法,正则项系数,求解优化器,以及将二分类模型转化为多分类模型的方法。
获取鸢尾花数据的方法:
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
print(__doc__) # Code source: Gaël Varoquaux
# Modified for documentation by Jaques Grobler
# License: BSD 3 clause import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model, datasets # import some data to play with
iris = datasets.load_iris()
X = iris.data[:, :2] # we only take the first two features.
Y = iris.target h = .02 # step size in the mesh logreg = linear_model.LogisticRegression(C=1e5) # we create an instance of Neighbours Classifier and fit the data.
logreg.fit(X, Y) # Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = logreg.predict(np.c_[xx.ravel(), yy.ravel()]) # Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure(1, figsize=(4, 3))
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired) # Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width') plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(()) plt.show()
防止过拟合的方法 预测鸾凤花(sklearn)的更多相关文章
- CNN 防止过拟合的方法
CNN 防止过拟合的方法 因为数据量的限制以及训练参数的增多,几乎所有大型卷积神经网络都面临着过拟合的问题,目前常用的防止过拟合的方法有下面几种: 1. data augmentation: ...
- 使用基于Apache Spark的随机森林方法预测贷款风险
使用基于Apache Spark的随机森林方法预测贷款风险 原文:Predicting Loan Credit Risk using Apache Spark Machine Learning R ...
- how to avoid over-fitting?(机器学习中防止过拟合的方法,重要)
methods to avoid overfitting: Cross-Validation : Cross Validation in its simplest form is a one roun ...
- Andrew Ng机器学习算法入门(十):过拟合问题解决方法
在使用机器学习对训练数据进行学习和分类的时候,会出现欠拟合和过拟合的问题.那么什么是欠拟合和过拟合问题呢?
- 想到的regular方法果然已经被sklearn实现了就是L1和L2组合rugular
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- 评价指标的局限性、ROC曲线、余弦距离、A/B测试、模型评估的方法、超参数调优、过拟合与欠拟合
1.评价指标的局限性 问题1 准确性的局限性 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷.比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率.所以,当 ...
- Neural Network Toolbox使用笔记1:数据拟合
http://blog.csdn.net/ljp1919/article/details/42556261 Neural Network Toolbox为各种复杂的非线性系统的建模提供多种函数和应用程 ...
- lecture9-提高模型泛化能力的方法
HInton第9课,这节课没有放论文进去.....如有不对之处还望指正.话说hinton的课果然信息量够大.推荐认真看PRML<Pattern Recognition and Machine L ...
随机推荐
- Tomcat最佳线程数
什么是最佳线程数? 为满足更多用户访问需求,可以调整Tomcat线程数,但是不能太大,否则导致线程切换开销,随着用户递增(线程数也随之调整),系统QPS逐渐增加,当用户量达到某个值,QPS并不会增加, ...
- UVA 11400"Lighting System Design"
传送门 错误思路 正解 AC代码 参考资料: [1]:https://www.cnblogs.com/Kiraa/p/5510757.html 题意: 现给你一套照明系统,这套照明系统共包含 n 种类 ...
- 关于methods、computed、watch的使用
关于methods.computed.watch的使用,前前后后我有转载过好几篇别人的文章.但始终没有自己成型的博文来记录,现自己尝试性的总结一下三者之间的区别: computed:计算属性 comp ...
- SDNU ACM-ICPC 2019 Competition For the End of Term(12-15)山师停训赛题解
马鸿儒 目前已补:01 03 06 07 08 09 10 11目前未补:02 04 05 12 苏用 1582.柳予欣的舔狗行为 1587.柳予欣的女朋友们在分享水果 1585.柳予欣和她女朋友的购 ...
- vue-learning:11 -js-nextTick()
nextTick() 在jQuery中,如果我们要生成一个ul-li的列表元素,我们也不会在循环体中每生成一个li就将它插入到ul中,而是在循环体内拼接每个li,待循环体结束后,再一并添加到ul元素上 ...
- 举例理解Hibernate的三种状态(转)
转自:https://blog.csdn.net/yiguang_820/article/details/79073152 初学Hibernate,了解到Hibernate有三种状态:transien ...
- VRChat模型制作及上传总篇(201912)
1.视频资源及软件插件模型资源: Kodoku-shi :https://www.bilibili.com/video/av20097333(自己目前找到讲的最详细的教程,但是blender减免部分貌 ...
- python列表的增删查改
添加新的元素 append() insert() extend() +号 删除元素 pop() remove() del xxx[index] 修改 xxx[index] = value 查找 in. ...
- EnvironmentAware接口的作用
在SpringBoot中的应用 凡注册到Spring容器内的bean,实现了EnvironmentAware接口重写setEnvironment方法后,在工程启动时可以获得application.pr ...
- Ubuntu查看cuda和cudnn版本
查看 CUDA 版本: cat /usr/local/cuda/version.txt 查看 CUDNN 版本: cat /usr/local/cuda/include/cudnn.h | grep ...