pytorch --Rnn语言模型(LSTM,BiLSTM) -- 《Recurrent neural network based language model》
论文通过实现RNN来完成了文本分类。
论文地址:88888888
模型结构图:
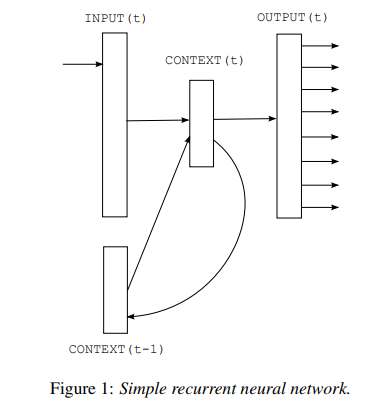
原理自行参考论文,code and comment(https://github.com/graykode/nlp-tutorial):
# -*- coding: utf-8 -*-
# @time : 2019/11/9 15:12 import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable dtype = torch.FloatTensor sentences = [ "i like dog", "i love coffee", "i hate milk"] word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # TextRNN Parameter
batch_size = len(sentences)
n_step = 2 # number of cells(= number of Step)
n_hidden = 5 # number of hidden units in one cell def make_batch(sentences):
input_batch = []
target_batch = [] for sen in sentences:
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]] input_batch.append(np.eye(n_class)[input])
target_batch.append(target) return input_batch, target_batch # to Torch.Tensor
input_batch, target_batch = make_batch(sentences)
input_batch = Variable(torch.Tensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch)) class TextRNN(nn.Module):
def __init__(self):
super(TextRNN, self).__init__() self.rnn = nn.RNN(input_size=n_class, hidden_size=n_hidden,batch_first=True)
self.W = nn.Parameter(torch.randn([n_hidden, n_class]).type(dtype))
self.b = nn.Parameter(torch.randn([n_class]).type(dtype)) def forward(self, hidden, X):
if self.rnn.batch_first == True:
# X [batch_size,time_step,word_vector]
outputs, hidden = self.rnn(X, hidden) # outputs [batch_size, time_step, hidden_size*num_directions]
output = outputs[:, -1, :] # [batch_size, num_directions(=1) * n_hidden]
model = torch.mm(output, self.W) + self.b # model : [batch_size, n_class]
return model
else:
X = X.transpose(0, 1) # X : [n_step, batch_size, n_class]
outputs, hidden = self.rnn(X, hidden)
# outputs : [n_step, batch_size, num_directions(=1) * n_hidden]
# hidden : [num_layers(=1) * num_directions(=1), batch_size, n_hidden] output = outputs[-1,:,:] # [batch_size, num_directions(=1) * n_hidden]
model = torch.mm(output, self.W) + self.b # model : [batch_size, n_class]
return model model = TextRNN() criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # Training
for epoch in range(5000):
optimizer.zero_grad() # hidden : [num_layers * num_directions, batch, hidden_size]
hidden = Variable(torch.zeros(1, batch_size, n_hidden))
# input_batch : [batch_size, n_step, n_class]
output = model(hidden, input_batch) # output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) loss.backward()
optimizer.step() # Predict
hidden_initial = Variable(torch.zeros(1, batch_size, n_hidden))
predict = model(hidden_initial, input_batch).data.max(1, keepdim=True)[1]
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
LSTM unit的RNN模型:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable dtype = torch.FloatTensor char_arr = [c for c in 'abcdefghijklmnopqrstuvwxyz']
word_dict = {n: i for i, n in enumerate(char_arr)}
number_dict = {i: w for i, w in enumerate(char_arr)}
n_class = len(word_dict) # number of class(=number of vocab) seq_data = ['make', 'need', 'coal', 'word', 'love', 'hate', 'live', 'home', 'hash', 'star'] # TextLSTM Parameters
n_step = 3
n_hidden = 128 def make_batch(seq_data):
input_batch, target_batch = [], [] for seq in seq_data:
input = [word_dict[n] for n in seq[:-1]] # 'm', 'a' , 'k' is input
target = word_dict[seq[-1]] # 'e' is target
input_batch.append(np.eye(n_class)[input])
target_batch.append(target) return Variable(torch.Tensor(input_batch)), Variable(torch.LongTensor(target_batch)) class TextLSTM(nn.Module):
def __init__(self):
super(TextLSTM, self).__init__() self.lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden)
self.W = nn.Parameter(torch.randn([n_hidden, n_class]).type(dtype))
self.b = nn.Parameter(torch.randn([n_class]).type(dtype)) def forward(self, X):
input = X.transpose(0, 1) # X : [n_step, batch_size, n_class] hidden_state = Variable(
torch.zeros(1, len(X), n_hidden)) # [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
cell_state = Variable(
torch.zeros(1, len(X), n_hidden)) # [num_layers(=1) * num_directions(=1), batch_size, n_hidden] outputs, (_, _) = self.lstm(input, (hidden_state, cell_state))
outputs = outputs[-1] # [batch_size, n_hidden]
model = torch.mm(outputs, self.W) + self.b # model : [batch_size, n_class]
return model input_batch, target_batch = make_batch(seq_data) model = TextLSTM() criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # Training
for epoch in range(1000): output = model(input_batch)
loss = criterion(output, target_batch)
if (epoch + 1) % 100 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step() inputs = [sen[:3] for sen in seq_data] predict = model(input_batch).data.max(1, keepdim=True)[1]
print(inputs, '->', [number_dict[n.item()] for n in predict.squeeze()])
BiLSTM RNN model:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F dtype = torch.FloatTensor sentence = (
'Lorem ipsum dolor sit amet consectetur adipisicing elit '
'sed do eiusmod tempor incididunt ut labore et dolore magna '
'aliqua Ut enim ad minim veniam quis nostrud exercitation'
) word_dict = {w: i for i, w in enumerate(list(set(sentence.split())))}
number_dict = {i: w for i, w in enumerate(list(set(sentence.split())))}
n_class = len(word_dict)
max_len = len(sentence.split())
n_hidden = 5 def make_batch(sentence):
input_batch = []
target_batch = [] words = sentence.split()
for i, word in enumerate(words[:-1]):
input = [word_dict[n] for n in words[:(i + 1)]]
input = input + [0] * (max_len - len(input))
target = word_dict[words[i + 1]]
input_batch.append(np.eye(n_class)[input])
target_batch.append(target) return Variable(torch.Tensor(input_batch)), Variable(torch.LongTensor(target_batch)) class BiLSTM(nn.Module):
def __init__(self):
super(BiLSTM, self).__init__() self.lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden, bidirectional=True)
self.W = nn.Parameter(torch.randn([n_hidden * 2, n_class]).type(dtype))
self.b = nn.Parameter(torch.randn([n_class]).type(dtype)) def forward(self, X):
input = X.transpose(0, 1) # input : [n_step, batch_size, n_class] hidden_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
cell_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=1), batch_size, n_hidden] outputs, (_, _) = self.lstm(input, (hidden_state, cell_state))
outputs = outputs[-1] # [batch_size, n_hidden]
model = torch.mm(outputs, self.W) + self.b # model : [batch_size, n_class]
return model input_batch, target_batch = make_batch(sentence) model = BiLSTM() criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # Training
for epoch in range(10000):
output = model(input_batch)
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) optimizer.zero_grad()
loss.backward()
optimizer.step() predict = model(input_batch).data.max(1, keepdim=True)[1]
print(sentence)
print([number_dict[n.item()] for n in predict.squeeze()])
pytorch --Rnn语言模型(LSTM,BiLSTM) -- 《Recurrent neural network based language model》的更多相关文章
- 4.5 RNN循环神经网络(recurrent neural network)
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 RNN循环神经网络 ...
- 论文笔记:ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks
ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks2018-03-05 11:13:05 ...
- 【NLP】Recurrent Neural Network and Language Models
0. Overview What is language models? A time series prediction problem. It assigns a probility to a s ...
- RNN循环神经网络(Recurrent Neural Network)学习
一.RNN简介 1.)什么是RNN? RNN是一种特殊的神经网络结构,考虑前一时刻的输入,且赋予了网络对前面的内容的一种'记忆'功能. 2.)RNN可以解决什么问题? 时间先后顺序的问题都可以使用RN ...
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- (zhuan) Recurrent Neural Network
Recurrent Neural Network 2016年07月01日 Deep learning Deep learning 字数:24235 this blog from: http:/ ...
- Recurrent neural network (RNN) - Pytorch版
import torch import torch.nn as nn import torchvision import torchvision.transforms as transforms # ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Recurrent Neural Network系列4--利用Python,Theano实现GRU或LSTM
yi作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORK ...
随机推荐
- js对象转换为json格式时,js对象属性中有值为null和undefined注意事项
当属性值为null时: 当属性值为undefined时: 只有当属性值为未定义时, js对象转换成json格式时会忽略该属性.
- 加深对于 MVC、MVP、MVVM 的概念理解
目录 MVC 对 MVC 的误解及缘由 MVP MVVM MVC MVC - 维基百科,自由的百科全书 MVC 是软件工程的一种软件架构模式,它不是具体的技术,而是一种代码分层的理念,主要体现了职责分 ...
- 数字金字塔 动态规划(优化版) USACO 一维dp压缩版
1016: 1.5.1 Number Triangles 数字金字塔 时间限制: 1 Sec 内存限制: 128 MB提交: 9 解决: 8[提交] [状态] [讨论版] [命题人:外部导入] 题 ...
- vnpy源码阅读学习(4):自己写一个类似vnpy的UI框架
自己写一个类似vnpy的界面框架 概述 通过之前3次对vnpy的界面代码的研究,我们去模仿做一个vn.py的大框架.巩固一下PyQt5的学习. 这部分的代码相对来说没有难度和深度,基本上就是把PyQt ...
- DbCommand :执行超时已过期。完成操作之前已超时或服务器未响应。
问题:“Timeout 时间已到.在操作完成之前超时时间已过或服务器未响应.”的解决方法 在一个链接数据库的时候,老是出现超时的错误:执行超时已过期.完成操作之前已超时或服务器未响应. 就是给这个链接 ...
- [bzoj4446] [loj#2009] [Scoi2015] 小凸玩密室
Description 小凸和小方相约玩密室逃脱,这个密室是一棵有 \(n\) 个节点的完全二叉树,每个节点有一个灯泡.点亮所有灯泡即可逃出密室.每个灯泡有个权值 \(Ai\) ,每条边也有个权值 \ ...
- 洛谷P2585 [ZJOI2006]三色二叉树
题目描述 输入输出格式 输入格式: 输入文件名:TRO.IN 输入文件仅有一行,不超过10000个字符,表示一个二叉树序列. 输出格式: 输出文件名:TRO.OUT 输出文件也只有一行,包含两个数,依 ...
- [bzoj2038] [洛谷P1494] [2009国家集训队] 小Z的袜子(hose)
Description 作为一个生活散漫的人,小Z每天早上都要耗费很久从一堆五颜六色的袜子中找出一双来穿.终于有一天,小Z再也无法忍受这恼人的找袜子过程,于是他决定听天由命-- 具体来说,小Z把这N只 ...
- vwmare 十月第 1 弹
step one 不管 是 ubuntu 还是 win vm tools 都是需要在虚拟的系统里面的去安装的. 这一点是相同的.
- Data for the People: How to Make Our Post-Privacy Economy Work for You
等翻译成 chinese在看吧