Scrapy框架的使用
- Scrapy框架的安装
- pip install pywin32
- 下载 Twisted 包 pip install Twisted包的路径
- pip insatll scrapy
- Scrapy的基本使用
- 切换到开始项目的目录
- scrapy startproject my_first_spider 命令创建一个新项目
- scrapy genspider my_first_spider www.xxx.com
- 目录结构如下
# -*- coding: utf-8 -*-
import scrapy
from my_first_spider.items import MyFirstSpiderItem class FirstSpider(scrapy.Spider):
# 当前spider的名称
name = 'first' # 允许的域名
# allowed_domains = ['www.xxx.com'] # 开始的第一个url
start_urls = ['https://www.zhipin.com/c101010100/?query=python开发&page=1&ka=page-1'] url = 'https://www.zhipin.com/c101010100/?query=python开发&page=%d&ka=page-1'
page = 1 # 用于解析的解析函数, 适用 xpath, 必传参数response
def parse(self, response):
div_list = response.xpath('//div[@class="job-list"]/ul/li')
for div in div_list:
job = div.xpath('./div/div[1]/h3/a/div[1]/text()').extract_first()
salary = div.xpath('./div/div[1]/h3/a/span/text()').extract_first()
company = div.xpath('./div/div[2]/div/h3/a/text()').extract_first() item = MyFirstSpiderItem() item['job'] = job
item['salary'] = salary
item['company'] = company yield item # 将item对象返回给数据持久化管道(pipelines) # 分页爬取
if self.page <= 7:
print(f'第{self.page}页爬取完毕,开始爬取第{self.page+1}页')
self.page += 1
yield scrapy.Request(url=self.url%self.page, callback=self.parse)first.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy # 与管道交互,实例化item对象进行交互,将爬取到的数据封装在对象中,以对象的方式进行文件间数据传递
class MyFirstSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job = scrapy.Field()
salary = scrapy.Field()
company = scrapy.Field()item.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import redis # 写入boss.txt文件
class MyFirstSpiderPipeline(object): fp = None def open_spider(self, spider):
print('开始爬虫')
self.fp = open('./boss.txt', 'w', encoding='utf8') def close_spider(self, spider):
self.fp.close()
print('爬虫结束') def process_item(self, item, spider): self.fp.write(item['job']+':'+item['salary']+':'+item['company']+'\n') return item # MySQL 写入管道
class MySqlPipeline(object):
conn = None
cursor = None # 爬虫开始后如若使用管道, 首先执行open_spider方法(打开mysql数据库连接)
def open_spider(self, spider): import pymysql.cursors self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root',
db='scrapy', charset='utf8')
# print('-----', self.conn)
print('打开MySQL连接, 开始写入') # 第二步 执行process_item 函数, 在其中进行写入操作, 如若有在此管道之后还有管道 此方法要将item对象返回
def process_item(self, item, spider): self.cursor = self.conn.cursor()
try:
self.cursor.execute(
'INSERT INTO boss (job_name, salary, company) VALUES ("%s", "%s", "%s")' % (item['job'], item['salary'], item['company']))
self.conn.commit()
except Exception as e:
self.conn.rollback()
print('出现错误, 事件回滚')
print(e) # 第三部爬虫结束后执行close_spider方法(关闭MySQL连接)
def close_spider(self, spider): self.conn.close()
self.cursor.close()
print('MySQl 写入完毕') # Redis 写入管道
class RedisPipeline(object): conn = None def open_spider(self, spider):
self.conn = redis.Redis(host='127.0.0.1', port=6379) # 第二步 执行process_item 函数, 在其中进行写入操作, 如若有在此管道之后还有管道 此方法要将item对象返回
def process_item(self, item, spider):
import json
dic = {
'job_name': item['job'],
'salary': item['salary'],
'company': item['company']
}
try:
self.conn.lpush('boss', json.dumps(dic))
print('redis 写入成功')
except Exception as e: print('redis 写入失败', e)
return itempipeline.py
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'my_first_spider.pipelines.MyFirstSpiderPipeline': 300,
'my_first_spider.pipelines.RedisPipeline': 301,
'my_first_spider.pipelines.MySqlPipeline': 302,
} BOT_NAME = 'my_first_spider' SPIDER_MODULES = ['my_first_spider.spiders']
NEWSPIDER_MODULE = 'my_first_spider.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' # Obey robots.txt rules
ROBOTSTXT_OBEY = Falsesetting.py
- 在命令行中输入 scrapy crawl first --nolog --nolog不显示日志
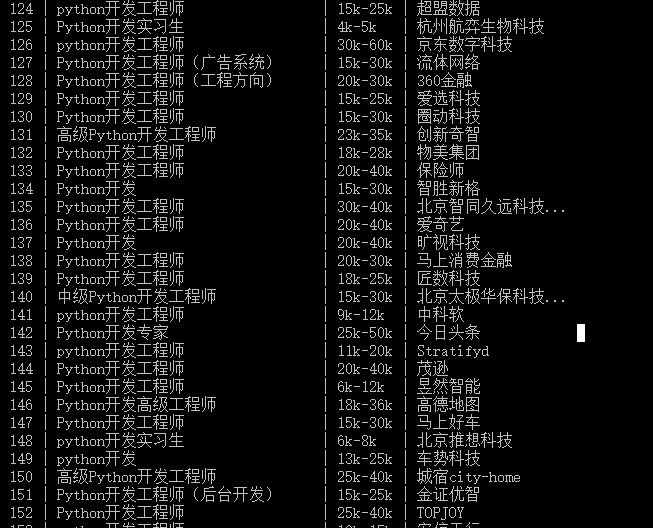
- 爬取成功

Scrapy框架的使用的更多相关文章
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
随机推荐
- leetcode-812-Largest Triangle Area
题目描述: You have a list of points in the plane. Return the area of the largest triangle that can be fo ...
- stark - 2 ⇲路由分发
在介绍前面三个注意点后,开始写stark组件内容. from django.apps import AppConfig from django.utils.module_loading import ...
- [短期持续更新]Codeforces 构造题一览
说实话我觉得做这种题很没意思(不够硬核), 可是人有短板终究是要补的...起码这种类型补起来相对简单 所以还是把先前准备好的专题放下吧,做点实现上比较休闲的题 ps.为了精简篇幅,代码全部丢到ubun ...
- eclipse 远程debug
[环境参数] Eclipse:Version: Mars.2 Release (4.5.2) Linux:centOS 6.5 [简述] Java自身支持调试功能,并提供了一个简单的调试工具--JDB ...
- Pycharm 导入 Python 包、模块
1.点击File->settings 2.选择Project Interpreter,点击右边绿色的加号添加包 3.输入你想添加的包名,点击Install Package 4.可以在Pychar ...
- jenkins+Publish Over SSH 提示:Transferred 0 file(s)
之前公司用jekins来进行自动化发布,现在公司因没有运维,所以自己学习.并搭建了一个jenkins的环境来进行项目自动化部署. 不料在最后连接ssh后部署时,一直提示Transferred 0 fi ...
- Celery ValueError: not enough values to unpack (expected 3, got 0)的解决方案
Celery ValueError: not enough values to unpack (expected 3, got 0)的解决方案 背景 最近因项目需要,学习任务队列Celery的用法,跟 ...
- tess4j 注意事项
依赖: <dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4 ...
- 实习没事干之自学redis
什么是Redis--http://how2j.cn/frontroute Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语 ...
- 性能调优之vmstat命令(转)
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存.进程.IO读写.CPU活动等进行监视.它是对系统的整体情况进行统计,不足之处是无法对某 ...