神经网络优化篇:详解动量梯度下降法(Gradient descent with Momentum)
动量梯度下降法
还有一种算法叫做Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法,简而言之,基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新的权重。

例如,如果要优化成本函数,函数形状如图,红点代表最小值的位置,假设从这里(蓝色点)开始梯度下降法,如果进行梯度下降法的一次迭代,无论是batch或mini-batch下降法,也许会指向这里,现在在椭圆的另一边,计算下一步梯度下降,结果或许如此,然后再计算一步,再一步,计算下去,会发现梯度下降法要很多计算步骤对吧?

慢慢摆动到最小值,这种上下波动减慢了梯度下降法的速度,就无法使用更大的学习率,如果要用较大的学习率(紫色箭头),结果可能会偏离函数的范围,为了避免摆动过大,要用一个较小的学习率。
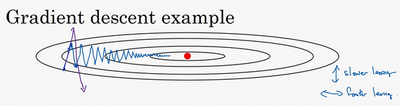
另一个看待问题的角度是,在纵轴上,希望学习慢一点,因为不想要这些摆动,但是在横轴上,希望加快学习,希望快速从左向右移,移向最小值,移向红点。所以使用动量梯度下降法,需要做的是,在每次迭代中,确切来说在第\(t\)次迭代的过程中,会计算微分\(dW\),\(db\),会省略上标\([l]\),用现有的mini-batch计算\(dW\),\(db\)。如果用batch梯度下降法,现在的mini-batch就是全部的batch,对于batch梯度下降法的效果是一样的。如果现有的mini-batch就是整个训练集,效果也不错,要做的是计算\(v_{{dW}}= \beta v_{{dW}} + \left( 1 - \beta \right)dW\),这跟之前的计算相似,也就是\(v = \beta v + \left( 1 - \beta \right)\theta_{t}\),\(dW\)的移动平均数,接着同样地计算\(v_{db}\),\(v_{db} = \beta v_{{db}} + ( 1 - \beta){db}\),然后重新赋值权重,\(W:= W -av_{{dW}}\),同样\(b:= b - a v_{db}\),这样就可以减缓梯度下降的幅度。
例如,在上几个导数中,会发现这些纵轴上的摆动平均值接近于零,所以在纵轴方向,希望放慢一点,平均过程中,正负数相互抵消,所以平均值接近于零。但在横轴方向,所有的微分都指向横轴方向,因此横轴方向的平均值仍然较大,因此用算法几次迭代后,发现动量梯度下降法,最终纵轴方向的摆动变小了,横轴方向运动更快,因此的算法走了一条更加直接的路径,在抵达最小值的路上减少了摆动。
动量梯度下降法的一个本质,这对有些人而不是所有人有效,就是如果要最小化碗状函数,这是碗的形状,画的不太好。
它们能够最小化碗状函数,这些微分项,想象它们为从山上往下滚的一个球,提供了加速度,Momentum项相当于速度。

想象有一个碗,拿一个球,微分项给了这个球一个加速度,此时球正向山下滚,球因为加速度越滚越快,而因为\(\beta\) 稍小于1,表现出一些摩擦力,所以球不会无限加速下去,所以不像梯度下降法,每一步都独立于之前的步骤,的球可以向下滚,获得动量,可以从碗向下加速获得动量。发现这个球从碗滚下的比喻,物理能力强的人接受得比较好,但不是所有人都能接受,如果球从碗中滚下这个比喻,理解不了,别担心。
最后来看具体如何计算,算法在此。

所以有两个超参数,学习率\(a\)以及参数\(\beta\),\(\beta\)控制着指数加权平均数。\(\beta\)最常用的值是0.9,之前平均了过去十天的温度,所以现在平均了前十次迭代的梯度。实际上\(\beta\)为0.9时,效果不错,可以尝试不同的值,可以做一些超参数的研究,不过0.9是很棒的鲁棒数。那么关于偏差修正,所以要拿\(v_{dW}\)和\(v_{db}\)除以\(1-\beta^{t}\),实际上人们不这么做,因为10次迭代之后,因为的移动平均已经过了初始阶段。实际中,在使用梯度下降法或动量梯度下降法时,人们不会受到偏差修正的困扰。当然\(v_{{dW}}\)初始值是0,要注意到这是和\(dW\)拥有相同维数的零矩阵,也就是跟\(W\)拥有相同的维数,\(v_{db}\)的初始值也是向量零,所以和\(db\)拥有相同的维数,也就是和\(b\)是同一维数。

最后要说一点,如果查阅了动量梯度下降法相关资料,经常会看到一个被删除了的专业词汇,\(1-\beta\)被删除了,最后得到的是\(v_{dW}= \beta v_{{dW}} +dW\)。用紫色版本的结果就是,所以\(v_{{dW}}\)缩小了\(1-\beta\)倍,相当于乘以\(\frac{1}{1- \beta}\),所以要用梯度下降最新值的话,\(a\)要根据\(\frac{1}{1 -\beta}\)相应变化。实际上,二者效果都不错,只会影响到学习率\(a\)的最佳值。觉得这个公式用起来没有那么自然,因为有一个影响,如果最后要调整超参数\(\beta\),就会影响到\(v_{{dW}}\)和\(v_{db}\),也许还要修改学习率\(a\),所以更喜欢左边的公式,而不是删去了\(1-\beta\)的这个公式,所以更倾向于使用左边的公式,也就是有\(1-\beta\)的这个公式,但是两个公式都将\(\beta\)设置为0.9,是超参数的常见选择,只是在这两个公式中,学习率\(a\)的调整会有所不同。
所以这就是动量梯度下降法,这个算法肯定要好于没有Momentum的梯度下降算法。
神经网络优化篇:详解动量梯度下降法(Gradient descent with Momentum)的更多相关文章
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- (3)梯度下降法Gradient Descent
梯度下降法 不是一个机器学习算法 是一种基于搜索的最优化方法 作用:最小化一个损失函数 梯度上升法:最大化一个效用函数 举个栗子 直线方程:导数代表斜率 曲线方程:导数代表切线斜率 导数可以代表方向, ...
- matlab实现梯度下降法(Gradient Descent)的一个例子
在此记录使用matlab作梯度下降法(GD)求函数极值的一个例子: 问题设定: 1. 我们有一个$n$个数据点,每个数据点是一个$d$维的向量,向量组成一个data矩阵$\mathbf{X}\in \ ...
- 梯度下降法Gradient descent(最速下降法Steepest Descent)
最陡下降法(steepest descent method)又称梯度下降法(英语:Gradient descent)是一个一阶最优化算法. 函数值下降最快的方向是什么?沿负梯度方向 d=−gk
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- ubuntu之路——day8.2 深度学习优化算法之指数加权平均与偏差修正,以及基于指数加权移动平均法的动量梯度下降法
首先感谢吴恩达老师的免费公开课,以下图片均来自于Andrew Ng的公开课 指数加权平均法 在统计学中被称为指数加权移动平均法,来看下面一个例子: 这是伦敦在一些天数中的气温分布图 Vt = βVt- ...
- 理解梯度下降法(Gradient Decent)
1. 什么是梯度下降法? 梯度下降法(Gradient Decent)是一种常用的最优化方法,是求解无约束问题最古老也是最常用的方法之一.也被称之为最速下降法.梯度下降法在机器学习中十分常见,多用 ...
随机推荐
- Halcon、HDevelop快速入门
HDevelop基础一 HDevelop概述 HDevelop是一款机器视觉的集成开发环境.下面将对HDevelop的界面内容做一下简单的介绍. 界面介绍 打开HDevelop,将看到以下画面. ...
- Centos离线安装JDK+Tomcat+MySQL8.0+Nginx
一.安装JDK 注:以下命令环境在Xshell中进行. 1.查询出系统自带的OpenJDK及版本 rpm -qa | grep jdk 2.如果显示已安装openjdk则对其进行卸载. #卸载 rpm ...
- 使用Visual Studio 2022 创建lib和dll并使用
对于一个经常写javaWeb的人来说,使用Visual Studio似乎没什么必要,但是对于使用ffi的人来说,使用c或c++编译器,似乎是必不可少的,下面我将讲述如何用Visual Studio 2 ...
- 【Linux API 揭秘】container_of函数详解
[Linux API 揭秘]container_of函数详解 Linux Version:6.6 Author:Donge Github:linux-api-insides 1.container_o ...
- 将多个txt文件中的内容写在一个txt中的方法
import os filename='./train_data/img_' for i in range(1,19736): newfile=filename+str(i)+'.txt' if os ...
- SpringBoot-Validate优雅的实现参数校验,详细示例~
1.是什么? 它简化了 Java Bean Validation 的集成.Java Bean Validation 通过 JSR 380,也称为 Bean Validation 2.0,是一种标准化的 ...
- 解密Prompt系列21. LLM Agent之再谈RAG的召回信息密度和质量
话接上文的召回多样性优化,多路索引的召回方案可以提供更多的潜在候选内容.但候选越多,如何对这些内容进行筛选和排序就变得更加重要.这一章我们唠唠召回的信息密度和质量.同样参考经典搜索和推荐框架,这一章对 ...
- 关于Secure Hash Algorithm加密算法
一.概述 SHA(Secure Hash Algorithm)加密算法是一种广泛应用的密码散列函数,由美国国家安全局(NSA)设计,用于保障数据的安全性和完整性.SHA算法经历了多个版本的更新,目前主 ...
- Pikachu漏洞靶场 PHP反序列化
PHP反序列化 查看源码,以下为关键代码: class S{ var $test = "pikachu"; function __construct(){ echo $this-& ...
- Liquid 常用语法记录
一.什么是 Liquid Liquid 是一款专为特定需求而打造的模板引擎. Liquid 中有两种类型的标记:Output 和 Tag. Output 通常用来显示文本 {{ 两个花括号 }} Ta ...