带你认识Flink容错机制的两大方面:作业执行和守护进程
摘要:Flink 容错机制主要有作业执行的容错以及守护进程的容错两方面,前者包括 Flink runtime 的 ExecutionGraph 和Execution的容错,后者则包括 JobManager 和 TaskManager 的容错。
本文分享自华为云社区《Flink容错机制》,原文作者:yangxiao_mrs 。
Flink 容错机制主要有作业执行的容错以及守护进程的容错两方面,前者包括 Flink runtime 的 ExecutionGraph 和Execution的容错,后者则包括 JobManager 和 TaskManager 的容错。
一、作业执行容错
Flink 的错误恢复机制分为多个级别,即 Execution 级别的 Failover 策略和 ExecutionGraph 级别的 Job Restart 策略。当出现错误时,Flink 会先尝试触发范围小的错误恢复机制,如果仍处理不了才会升级为更大范围的错误恢复机制,具体可以看下面的序列图。
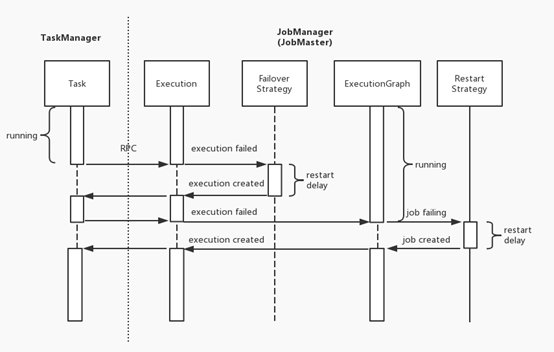
当 Task 发生错误,TaskManager 会通过 RPC 通知 JobManager,后者将对应 Execution 的状态转为 failed 并触发 Failover 策略。如果符合 Failover 策略,JobManager 会重启 Execution,否则升级为 ExecutionGraph 的失败。ExecutionGraph 失败则进入 failing 的状态,由 Restart 策略决定其重启(restarting 状态)还是异常退出(failed 状态)。
1.1 Task Failover策略
Task Failover策略目前有三个,分别是:RestartAll、RestartIndividualStrategy 和 RestartPipelinedRegionStrategy。
RestartAll: 重启全部 Task,是恢复作业一致性的最安全策略,会在其他 Failover 策略失败时作为保底策略使用。目前是默认的 Task Failover 策略。
RestartPipelinedRegionStrategy: 重启错误 Task 所在 Region 的全部 Task。Task Region 是由 Task 的数据传输决定的,有数据传输的 Task 会被放在同一个 Region,而不同 Region 之间没有数据交换。
RestartIndividualStrategy: 恢复单个 Task。因为如果该 Task 没有包含数据源,这会导致它不能重流数据而导致一部分数据丢失。考虑到至少提供准确一次的投递语义,这个策略的使用范围比较有限,只应用于 Task 间没有数据传输的作业。
1.2 Job Restart策略
如果 Task 错误最终触发了 Full Restart,此时 Job Restart 策略将会控制是否需要恢复作业。Flink 提供三种 Job 具体的 Restart Strategy。
FixedDelayRestartStrategy: 允许指定次数内的 Execution 失败,如果超过该次数则导致 Job 失败。FixedDelayRestartStrategy 重启可以设置一定的延迟,以减少频繁重试对外部系统带来的负载和不必要的错误日志。
FailureRateRestartStrategy: 允许在指定时间窗口内的指定次数内的 Execution 失败,如果超过这个频率则导致 Job 失败。同样地,FailureRateRestartStrategy 也可以设置一定的重启延迟。
NoRestartStrategy: 在 Execution 失败时直接让 Job 失败。
二、守护进程容错
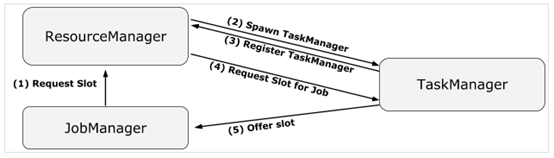
Flink on YARN 的部署模式,关键的守护进程有 JobManager 和 TaskManager 两个,其中JobManager的主要职责协调资源和管理作业的执行分别为ResourceManager 和 JobMaster 两个守护线程承担,三者之间的关系如下图所示。
2.1 TaskManager 的容错
如果 ResouceManager 通过心跳超时检测到或者通过集群管理器的通知了解到 TaskManager 故障,它会通知对应的 JobMaster 并启动一个新的 TaskManager 以做代替。注意 ResouceManager 并不关心 Flink 作业的情况,这是 JobMaster 的职责去管理 Flink 作业要做何种反应。
如果 JobMaster 通过 ResouceManager 的通知了解到或者通过心跳超时检测到 TaskManager 故障,它首先会从自己的 slot pool 中移除该 TaskManager,并将该 TaskManager 上运行的所有 Tasks 标记为失败,从而触发 Flink 作业执行的容错机制以恢复作业。
TaskManager 的状态已经写入 checkpoint 并会在重启后自动恢复,因此不会造成数据不一致的问题。
2.2 ResourceManager 的容错
如果TaskManager通过心跳超时检测到 ResourceManager 故障,或者收到 zookeeper 的关于ResourceManager失去leadership通知,TaskManager会寻找新的 leader,ResourceManager 并将自己重启注册到其上,期间并不会中断 Task的执行。
如果JobMaster通过心跳超时检测到ResourceManager故障,或者收到 zookeeper 的关于 ResourceManager 失去 leadership 通知,JobMaster 同样会等待新的 ResourceManager 变成 leader,然后重新请求所有的TaskManager。考虑到 TaskManager 也可能成功恢复,这样的话 JobMaster 新请求的 TaskManager 会在空闲一段时间后被释放。
ResourceManager上保持了很多状态信息,包括活跃的 container、可用的 TaskManager、TaskManager 和 JobMaster 的映射关系等等信息,不过这些信息并不是 ground truth,可以从与 JobMaster 及 TaskManager 的状态同步中再重新获得,所以这些信息并不需要持久化。
2.3 JobMaster 的容错
如果 TaskManager 通过心跳超时检测到 JobMaster 故障,或者收到 zookeeper 的关于 JobMaster 失去 leadership 通知,TaskManager 会触发自己的错误恢复,然后等待新的 JobMaster。如果新的 JobMaster 在一定时间后仍未出现,TaskManager 会将其 slot 标记为空闲并告知 ResourceManager。
如果 ResourceManager 通过心跳超时检测到 JobMaster 故障,或者收到 zookeeper 的关于 JobMaster 失去 leadership 通知,ResourceManager 会将其告知 TaskManager,其他不作处理。
JobMaster 保存了很多对作业执行至关重要的状态,其中 JobGraph 和用户代码会重新从 HDFS 等持久化存储中获取,checkpoint 信息会从 zookeeper 获得,Task 的执行信息可以不恢复因为整个作业会重新调度,而持有的 slot 则从 ResourceManager 的 TaskManager 的同步信息中恢复。
2.4 并发故障
Flink on YARN 部署模式下,因为 JobMaster 和 ResourceManager 都在 JobManager 进程内,如果JobManager 进程出问题,通常是 JobMaster 和 ResourceManager 并发故障,那么 TaskManager 会按以下步骤处理:
- 按照普通的 JobMaster 故障处理。
- 在一段时间内不断尝试将 slot 提供给新的 JobMaster。
- 不断尝试将自己注册到 ResourceManager 上。
值得注意的是,新 JobManager 的拉起是依靠 YARN 的 Application attempt 重试机制来自动完成的,而根据 Flink 配置的 YARN Application: keep-containers-across-application-attempts 行为,TaskManager 不会被清理,因此可以重新注册到新启动的 Flink ResourceManager 和 JobMaster 中。
三、总结
Flink 容错机制确保了 Flink 的可靠性和持久性,具体来说它包括作业执行的容错和守护进程的容错两个方面。在作业执行容错方面,Flink 提供 Task 级别的 Failover 策略和 Job 级别的 Restart 策略来进行故障情况下的自动重试。在守护进程的容错方面,在on YARN 模式下,Flink 通过内部组件的心跳和 YARN 的监控进行故障检测。TaskManager 的故障会通过申请新的 TaskManager 并重启 Task 或 Job 来恢复,JobManager 的故障会通过集群管理器的自动拉起新 JobManager 和 TaskManager 的重新注册到新 leader JobManager 来恢复。
带你认识Flink容错机制的两大方面:作业执行和守护进程的更多相关文章
- Flink容错机制(checkpoint)
checkpoint是Flink容错的核心机制.它可以定期地将各个Operator处理的数据进行快照存储( Snapshot ).如果Flink程序出现宕机,可以重新从这些快照中恢复数据. 1. ch ...
- Flink 容错机制与状态
简介 Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态. 该机制确保即使出现故障,经过恢复,程序的状态也会回到以前的状态. Flink 主持 at least once 语 ...
- Flink容错机制
Flink的Fault Tolerance,是在在Chandy Lamport Algorithm的基础上扩展实现了一套分布式Checkpointing机制,这个机制在论文"Lightwei ...
- Flink资料(2)-- 数据流容错机制
数据流容错机制 该文档翻译自Data Streaming Fault Tolerance,文档描述flink在流式数据流图上的容错机制. ------------------------------- ...
- Apache Flink - 数据流容错机制
Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态.该机制确保即使出现故障,程序的状态最终也会反映来自数据流的每条记录(只有一次). 从容错和消息处理的语义上(at leas ...
- 关于 Flink 状态与容错机制
Flink 作为新一代基于事件流的.真正意义上的流批一体的大数据处理引擎,正在逐渐得到广大开发者们的青睐.就从我自身的视角看,最近也是在数据团队把一些原本由 Flume.SparkStreaming. ...
- Flink原理(五)——容错机制
本文是博主阅读Flink官方文档以及<Flink基础教程>后结合自己理解所写,若有表达有误的地方欢迎大伙留言指出. 1. 前言 流式计算分为有状态和无状态两种情况,所谓状态就是计算过程中 ...
- 【大数据面试】Flink 04:状态编程与容错机制、Table API、SQL、Flink CEP
六.状态编程与容错机制 1.状态介绍 (1)分类 流式计算分为无状态和有状态 无状态流针对每个独立事件输出结果,有状态流需要维护一个状态,并基于多个事件输出结果(当前事件+当前状态值) (2)有状态计 ...
- Flink学习(三)状态机制于容错机制,State与CheckPoint
摘自Apache官网 一.State的基本概念 什么叫State?搜了一把叫做状态机制.可以用作以下用途.为了保证 at least once, exactly once,Flink引入了State和 ...
- 总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发. 本文主要内容如 ...
随机推荐
- 16.1 Socket 端口扫描技术
端口扫描是一种网络安全测试技术,该技术可用于确定对端主机中开放的服务,从而在渗透中实现信息搜集,其主要原理是通过发送一系列的网络请求来探测特定主机上开放的TCP/IP端口.具体来说,端口扫描程序将从指 ...
- java后端操作树结构
一.树结构的三种组装方式(递归.双层for循环,map) (1)递归 普通递归方法 public Result getBmsMenuList(UserSessionVO userSessionInfo ...
- 记一次 openSUSE Tumbleweed 下安装 k8s
出现的问题 因为没有K8s基础的而踩了不少坑. kubeadm kubelet 最好指定版本安装,因为kubelet的版本需要小于等于kubeadm的版本,否则就会报错. 运行 kubeadm ini ...
- CF1766B [Notepad#]
Problem 题目简述 给你一个整数 \(n\) 和字符串 \(s\),问:能不能在小于 \(n\) 次操作的情况下,输出字符串 \(s\). 有两次操作可供使用: 在已打出内容的最后添加一个字符. ...
- redis 怎么样查看key的大小,多大的key才算大key?
查看key大小的命令 # 格式memory usage [key-name]# 例如:我要查 yino_hash_key 这个key的大小,就在命令行中输入 memory usage yino_has ...
- Acwing127周赛第三题 构造矩阵 (套路)
题目链接:构造矩阵 题目描述 我们希望构造一个 n×m 的整数矩阵. 构造出的矩阵需满足: 每一行上的所有元素之积均等于 k. 每一列上的所有元素之积均等于 k. 保证 k 为 1 或 −1. 请你计 ...
- Flask Session 登录认证模块
Flask 框架提供了强大的 Session 模块组件,为 Web 应用实现用户注册与登录系统提供了方便的机制.结合 Flask-WTF 表单组件,我们能够轻松地设计出用户友好且具备美观界面的注册和登 ...
- 一个基于ASP.NET Core完全开源的CMS 解决方案
本文简介 MixCoreCMS是一个基于.NET Core框架的开源内容管理系统(CMS),提供了丰富的的基础功能和插件,是一款面向未来的企业 Web CMS,可轻松构建任何类型的应用程序.集成了Go ...
- 报错Error running 'Tomcat 9.0.68': Can't find catalina.jar【解决办法】
修改tomcat路径,肯定是你移动了jar包在硬盘的位置 将路径改成当前所在的文件位置
- 明解Java第一章练习题答案
@ 目录 练习1-1 练习1-2 练习1-3 <明解Java>书籍其他章节答案 练习1-1 如果没有表示程序语句末尾的分号,结果会怎么样呢?请编译程序进行确认. 答:编译器报错 练习1-2 ...