Spark 集群环境搭建
思路:
①先在主机s0上安装Scala和Spark,然后复制到其它两台主机s1、s2
②分别配置三台主机环境变量,并使用source命令使之立即生效
主机映射信息如下:
192.168.32.100 s0
192.168.32.101 s1
192.168.32.102 s2
搭建目标:
s0 : Master
s1 : Worker
s2 : Worker
1、准备
Hadoop 版本:2.7.7
Scala版本:2.12.8
Spark版本:2.4.3
2、安装Hadoop
下载地址:
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
Hadoop 安装步骤参考(示例版本与HDFS端口配置略有差异,根据实际情况调整):
https://www.cnblogs.com/jonban/p/hadoop.html
3、安装Scala
下载地址:
https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz
解压到 /opt 下
tar -zxvf scala-2.12.8.tgz -C /opt/
环境变量可暂时不配置,等到全部配置完成后统一配置环境变量,并使之生效。
配置环境变量,追加如下内容:
export SCALA_HOME=/opt/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
可用追加命令,如下所示:
echo -e '\nexport SCALA_HOME=/opt/scala-2.12.8\nexport PATH=$PATH:$SCALA_HOME/bin\n' >> /etc/profile
使用source命令使配置立即生效
source /etc/profile
4、安装Spark
Spark下载地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
也可到官网下载其它版本,下载页面地址如下:
http://spark.apache.org/downloads.html
解压到 /opt 下
tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz -C /opt/
5、修改配置文件
进入配置文件目录
cd /opt/spark-2.4.3-bin-hadoop2.7/conf
配置 log4j.properties
mv log4j.properties.template log4j.properties
配置 slaves
mv slaves.template slaves
内容如下:
s1
s2
配置 spark-env.sh
cp spark-env.sh.template spark-env.sh
在 spark-env.sh 中添加如下内容(以下为本机示例,配置路径根据实际情况调整):
export JAVA_HOME=/opt/jdk1.8.0_192
export SCALA_HOME=/opt/scala-2.12.8
export HADOOP_HOME=/opt/hadoop-2.7.7
export HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop
export SPARK_MASTER_IP=s0
export SPARK_MASTER_HOST=s0
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.7/bin/hadoop classpath)
6、远程复制Scala 安装目录到其它两台主机s1、s2
scp -r /opt/scala-2.12.8 root@s1:/opt/
scp -r /opt/scala-2.12.8 root@s2:/opt/
7、远程复制Spark 安装目录到其它两台主机s1、s2
scp -r /opt/spark-2.4.3-bin-hadoop2.7 root@s1:/opt/
scp -r /opt/spark-2.4.3-bin-hadoop2.7 root@s2:/opt/
8、配置三台主机环境变量
在 /etc/profile 中追加如下内容:
export SCALA_HOME=/opt/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin export SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
追加命令如下:
echo -e '\nexport SCALA_HOME=/opt/scala-2.12.8\nexport PATH=$PATH:$SCALA_HOME/bin\n' >> /etc/profile
echo -e '\nexport SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7\nexport PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin\n' >> /etc/profile
使用source命令使配置立即生效
source /etc/profile
9、启动
启动Hadoop集群
start-dfs.sh
start-yarn.sh
启动Spark
start-master.sh
start-slaves.sh
10、查看状态
在三台主机上分别输入jps命令查看状态,结果如下:
[root@s0 conf]# jps
2097 ResourceManager
1803 NameNode
2675 Master
[root@s1 ~]# jps
1643 NodeManager
1518 DataNode
1847 Worker
[root@s2 ~]# jps
1600 NodeManager
1475 DataNode
1804 Worker
符合预期结果!
11、验证
浏览器输入地址:
截图如下:
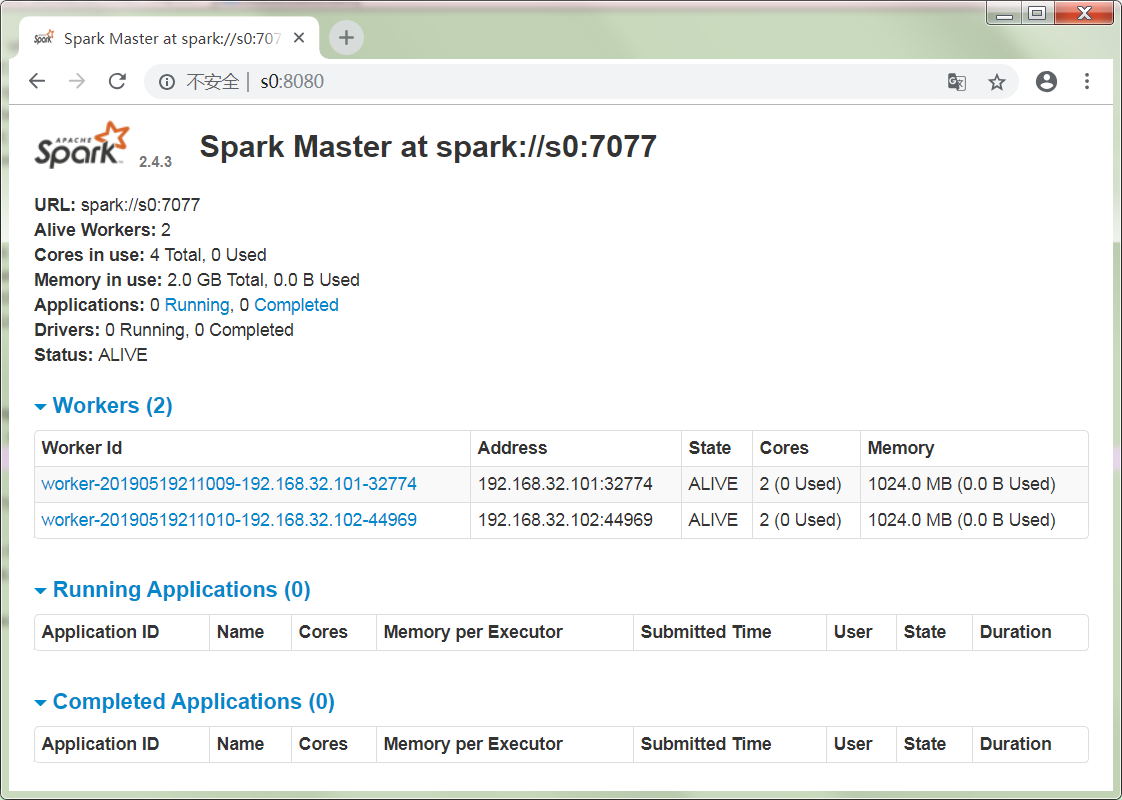
集群状态完美!
12、测试
输入spark-shell 命令,如下所示:
创建 wordcount.txt 文件,内容如下:
Hello Hadoop
Hello Hbase
Hello Spark
上传 wordcount.txt 到 HDFS文件系统上
hdfs dfs -mkdir -p /spark/input
hdfs dfs -put wordcount.txt /spark/input
输入scala 统计单词个数程序,如下:
sc.textFile("hdfs://s0:8020/spark/input/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect
输出结果:
res0: Array[(String, Int)] = Array((Spark,1), (Hello,3), (Hbase,1), (Hadoop,1))
程序正常运行!
13、停止集群
stop-slaves.sh
stop-master.sh
停止Hadoop集群
stop-yarn.sh
stop-dfs.sh
Spark 集群环境搭建
.
Spark 集群环境搭建的更多相关文章
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Spark集群环境搭建——部署Spark集群
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等.并且已经安装好了hadoop集群. 如果还没有配置好的,参考我前面两篇博客: Spark集群环境搭建--服务器环境初始化:htt ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- Spark集群环境搭建——服务器环境初始化
Spark也是属于Hadoop生态圈的一部分,需要用到Hadoop框架里的HDFS存储和YARN调度,可以用Spark来替换MR做分布式计算引擎. 接下来,讲解一下spark集群环境的搭建部署. 一. ...
- Hadoop、Spark 集群环境搭建问题汇总
Hadoop 问题1: Hadoop Slave节点 NodeManager 无法启动 解决方法: yarn-site.xml reducer取数据的方式是mapreduce_shuffle 问题2: ...
- Hadoop、Spark 集群环境搭建
1.基础环境搭建 1.1运行环境说明 1.1.1硬软件环境 主机操作系统:Windows 64位,四核8线程,主频3.2G,8G内存 虚拟软件:VMware Workstation Pro 虚拟机操作 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
随机推荐
- cshtml 获取session值
在 cshtml 中,我们如何获取 session 的呢? 首先我们先设置 session 值,我们一般都会在 Controller 设置 session. Session["isAdmin ...
- 浏览器版本低于IE10跳转到指定网页
var userAgent = navigator.userAgent; var ie6 = (/msie\s*(\d+)\.\d+/g.exec(userAgent.toLowerCase()) | ...
- 当Python中混进一只薛定谔的猫……
本文原创并首发于公众号[Python猫],未经授权,请勿转载. 原文地址:https://mp.weixin.qq.com/s/-fFVTgWVsydFsNu1nyxUzA Python 是一门强大的 ...
- GDB 远程调试Linux (CentOS)
1.引用: https://blogs.msdn.microsoft.com/vcblog/2016/03/30/visual-c-for-linux-development/ 注意安装gdbserv ...
- [Xcode 实际操作]六、媒体与动画-(3)使用CoreImage框架设置图片的单色效果
目录:[Swift]Xcode实际操作 本文将演示如何使用图片框架,将图片转换成单色样式. 在项目导航区,打开视图控制器的代码文件[ViewController.swift] import UIKit ...
- HTML <!doctype>声明
昨天看代码的时候,发现在<!doctype>中添加了新的属性,以前写代码的时候并不会在该声明里添加新的属性.昨天看到了,就把它记下来学习一下,顺便整理成文档.以便日后复习. <!DO ...
- Ubuntu英文版中无法输入中文标点符号的问题
问题: 不管是中文还是英文输入法,输入的标点符号都是英文的 解决方法: ctrl + . 进行切换,一个是lation 符号,一个是全角符号
- JS高级学习历程-17
[正则案例] 1 匹配手机号码
- [Android]Android性能优化
安卓性能优化 性能优化的几大考虑 Mobile Context 资源受限 + 内存,普遍较小,512MB很常见,开发者的机器一般比用户的机器高端 + CPU,核心少,运算能力没有全开 + GPU,上传 ...
- 二开获取yigo设计器里查询集合里中的某个SQL
package com.bokesoft.lrp_v3.mid.dongming.service; import java.math.BigDecimal; import java.util.Arra ...