深度学习中优化【Normalization】
深度学习中优化操作:
- dropout
- l1, l2正则化
- momentum
- normalization
1、为什么Normalization?
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
对于每一层网络得到输出向量的分布是不太有规律的,将这些没有规律的的输出结果放入激励层,会使得许多样本?因为偏离0坐标太远,而使得这些样本的值很大(等于1)或者很小(等于0),从而导致在反向传播时梯度消失。
我们在训练的时候希望每个batch在同一层网络下的输出结果是独立同分布的,这样能网络的泛化性就会比较强。
2、方式
1.Batch Normalization
BN的做法很简单,就是在输出结果在送到激励层之前,对输出结果做一次标准化。

前三步分别就是求均值与方差,并对其进行中心化,normalize中分母中的$\epsilon$,是为了避免除以0溢出。经过这三步,输出结果已经变成均值为$\mu _{b}$, 方差是$\sigma^{2}_{b}$的分布了。
最后一步非常重要。γ和β是可学习的,目的是让网络能够自己调节分布。我们获得一个关于y轴对称的分布真的是最符合神经网络训练的吗?没有任何理由能证明这点。事实上,γ和β为输出的线性调整参数,可以让分布曲线压缩或延长一点,左移或右移一点。由于γ和β是可训练的,那么意味着神经网络会随着训练过程自己挑选一个最适合的分布。如果我们固执地不用γ和β会怎么样呢?那势必会把压力转移到特征提取层,虽然最后结果依然可观,但训练压力会很大。你想想,一边只需要训练两个数,另一边需要训练特征提取层来符合最优分布就是关于y轴的对称曲线。前者自然训练成本更低。
---------------------
作者:木盏
来源:CSDN
原文:https://blog.csdn.net/leviopku/article/details/83109422
版权声明:本文为博主原创文章,转载请附上博文链接!
反向传播:https://kevinzakka.github.io/2016/09/14/batch_normalization/

在反向传播过程中,$\frac{\partial L}{\partial \boldsymbol{y}}$由上一步已经算出,是已知条件。
先求:$\frac{\partial f}{\partial \gamma }, \frac{\partial f}{\partial \hat{x_{i}}},\frac{\partial f}{\partial \beta } $
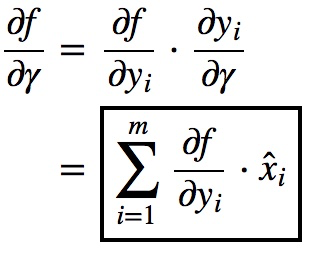
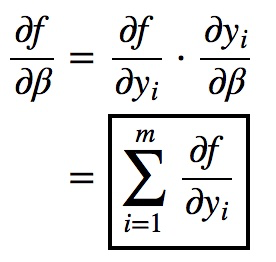
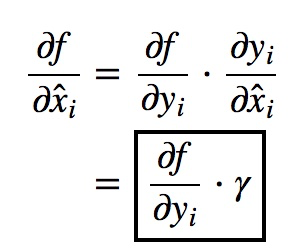
再根据 x标准化,求$\frac{\partial f}{\partial \mu }, \frac{\partial f}{\partial \sigma ^{2}},\frac{\partial f}{\partial x_{i} } $
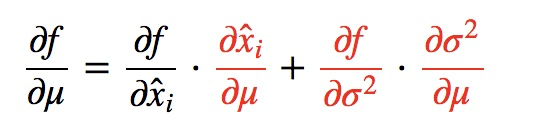
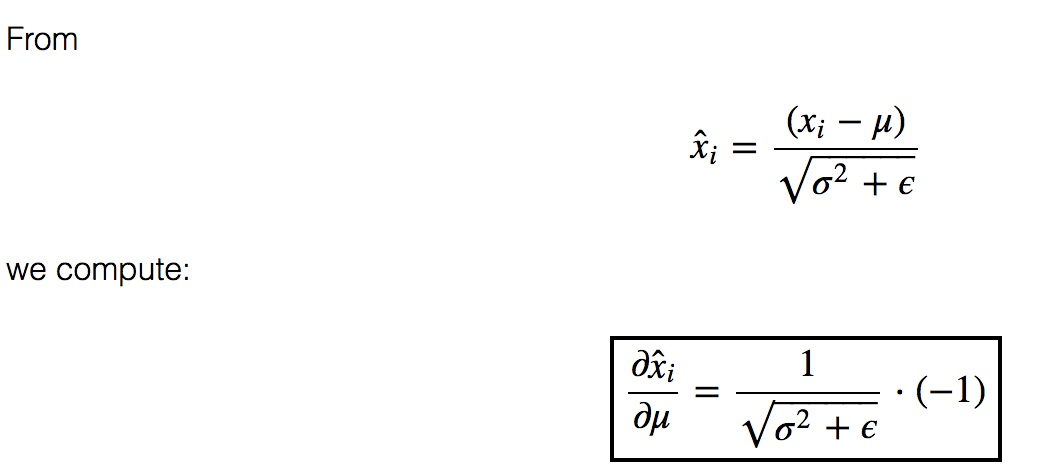

$\frac{\partial f}{\partial \mu} = \sum_{i = 1}^{m} \frac{\partial f}{\partial \hat{x}_{i}} \frac{\partial \hat{x}_{i}}{\partial \mu} + \frac{\partial f}{\partial \sigma^{2} } \frac{\partial \sigma^{2}}{\partial \mu}$

缺点:
1.对batchsize大小比较敏感,如果batchsize太不小计算的均值和方差不足以代表整体的数据分布
2.在RNN领域效果不是很好。为什么
BN是以每一个batch为基准进行计算的,也就是 μ.shape = (1, D), var.shape = (1, D),对于RNN来说,每一个batch中的数据可能不是等长的,即使padding后变成等长,然后在normalize就会引入噪声(padding)
2、Layer Normalization
LN不以batch为单位,而是以一个样本为单位。
u.shape = (N, 1)
var.shape = (N, 1)
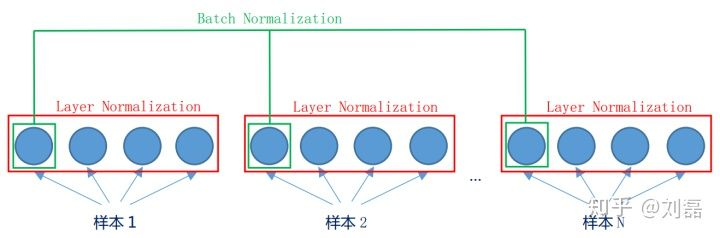
反向传播:
python实现:
tf接口
参考:
http://www.dataguru.cn/article-13031-1.html
https://www.cnblogs.com/guoyaohua/p/8724433.html
https://blog.csdn.net/leviopku/article/details/83109422
深度学习中优化【Normalization】的更多相关文章
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- 深度学习中 Batch Normalization
深度学习中 Batch Normalization为什么效果好?(知乎) https://www.zhihu.com/question/38102762
- 深度学习中 Batch Normalization为什么效果好
看mnist数据集上其他人的CNN模型时了解到了Batch Normalization 这种操作.效果还不错,至少对于训练速度提升了很多. batch normalization的做法是把数据转换为0 ...
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
- L19深度学习中的优化问题和凸性介绍
优化与深度学习 优化与估计 尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同. 优化方法目标:训练集损失函数值 深度学习目标:测试集损失函数值(泛化性) ...
- 深度学习中的batch_size,iterations,epochs等概念的理解
在自己完成的几个有关深度学习的Demo中,几乎都出现了batch_size,iterations,epochs这些字眼,刚开始我也没在意,觉得Demo能运行就OK了,但随着学习的深入,我就觉得不弄懂这 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
随机推荐
- Your project path contains non-ASCII characters
Android studio导入project时报错 non-ASCII characters意味着中文字符报错,解决方法简单有效: 检查项目路径中是否出现中文名,将中文字符修改成英文就可以解决辽~
- Android Studio教程04-Task和Back stack
目录 1.Tasks and Back Stack 1.1. 当点击Back按钮返回到上一个Activity时发生了什么? 1.2. 点击HOME按钮 1.3.多次点击进入Activity-Back按 ...
- Aspnet mvc移除WebFormViewEngine
为了提高mvc的速度,在Global.asax中移除WebFormViewEngine protected void Application_Start() { RemoveWebFormEngine ...
- 记录Javascript的数据方法参考
concat >>连接2个或更多数组,并返回结果 var arr1 = [1,2,3]; var arr2 = [-1,-2,-3]; console.log(arr1.concat(ar ...
- linux 软链接的创建、删除和更新
大家都知道,有的时候,我们为了省下空间,都会使用链接的方式来进行引用操作.同样的,在系统级别也有.在Windows系列中,我们称其为快捷方式,在Linux中我们称其为链接(基本上都差不多了,其中可能有 ...
- Azure存储账户的日志分析方法
1.首先确认日志功能是否开启(日志文件根据存储账户的类型,按使用量收费 . 2.在存储账户-Usage(classic)-Metrics中查看突出流量的时间: 3.在Explorer中下载对应时间点的 ...
- 《你必须掌握的Entity Framework 6.x与Core 2.0》勘误
第5章 5.1.1----致谢网友[宪煌] public virtual ICollection Post {get;set;} 修改为 public virtual ICollection<P ...
- 【alpha阶段】第八次Scrum Meeting
每日任务内容 队员 昨日完成任务 明日要完成的任务 牛宇航 #26 评价总览接口编写https://github.com/rRetr0Git/rateMyCourse/issues/26 (任务较重, ...
- iOS CATransition 自定义转场动画
https://www.jianshu.com/p/39c051cfe7dd CATransition CATransition 是CAAnimation的子类(如下图所示),用于控制器和控制器之间的 ...
- Linux centos ansible
创建m01.backup.nfs.web01.web02 m01(172.16.1.61).backup(172.16.1.41).nfs(172.16.1.31).web01(172.16.1.7) ...