深度学习中 Batch Normalization为什么效果好
看mnist数据集上其他人的CNN模型时了解到了Batch Normalization 这种操作。效果还不错,至少对于训练速度提升了很多。
batch normalization的做法是把数据转换为0均值和单位方差
1. What is BN?
顾名思义,batch normalization嘛,就是“批规范化”咯。Google在ICML文中描述的非常清晰,即在每次SGD时,通过mini-batch来对相应的activation做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1. 而最后的“scale and shift”操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入(即当

2. How to Batch Normalize?
怎样学BN的参数在此就不赘述了,就是经典的chain rule:
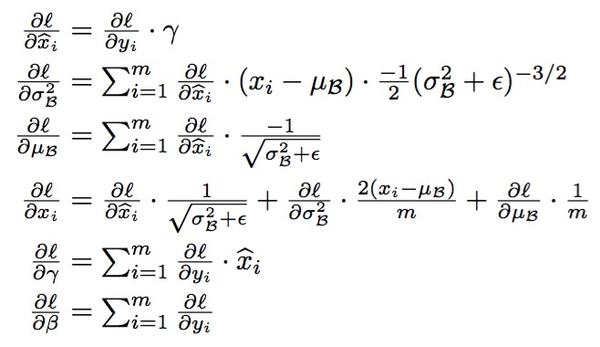
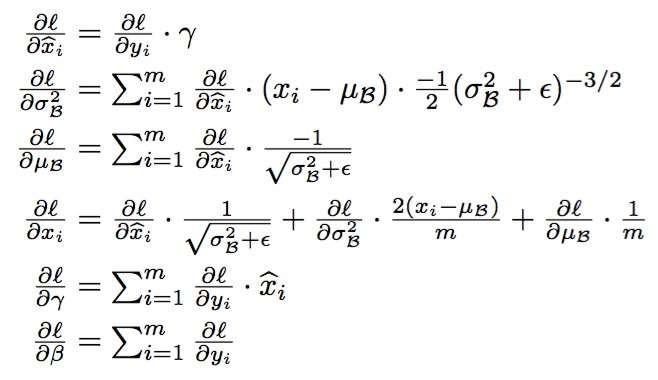
3. Where to use BN?
BN可以应用于网络中任意的activation set。文中还特别指出在CNN中,BN应作用在非线性映射前,即对做规范化。另外对CNN的“权值共享”策略,BN还有其对应的做法(详见文中3.2节)。
4. Why BN?
好了,现在才是重头戏--为什么要用BN?BN work的原因是什么?
说到底,BN的提出还是为了克服深度神经网络难以训练的弊病。其实BN背后的insight非常简单,只是在文章中被Google复杂化了。
首先来说说“Internal Covariate Shift”。文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有,
,但是
. 大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子:。在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法(见4.2.1节)。
5. When to use BN?
OK,说完BN的优势,自然可以知道什么时候用BN比较好。例如,在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
诚然,在DL中还有许多除BN之外的“小trick”。别看是“小trick”,实则是“大杀器”,正所谓“The devil is in the details”。希望了解其它DL trick(特别是CNN)的各位请移步我之前总结的:Must Know Tips/Tricks in Deep Neural Networks
以上。
作者:魏秀参
链接:https://www.zhihu.com/question/38102762/answer/85238569
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
参考资料:
https://blog.csdn.net/shuzfan/article/details/50723877
https://www.zhihu.com/question/38102762
https://arxiv.org/pdf/1502.03167.pdf
深度学习中 Batch Normalization为什么效果好的更多相关文章
- 深度学习中 Batch Normalization
深度学习中 Batch Normalization为什么效果好?(知乎) https://www.zhihu.com/question/38102762
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- 深度学习之Batch Normalization
在机器学习领域中,有一个重要的假设:独立同分布假设,也就是假设训练数据和测试数据是满足相同分布的,否则在训练集上学习到的模型在测试集上的表现会比较差.而在深层神经网络的训练中,当中间神经层的前一层参数 ...
- 深度学习中优化【Normalization】
深度学习中优化操作: dropout l1, l2正则化 momentum normalization 1.为什么Normalization? 深度神经网络模型的训练为什么会很困难?其中一个重 ...
- 深度学习中的batch、epoch、iteration的含义
深度学习的优化算法,说白了就是梯度下降.每次的参数更新有两种方式. 第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度.这种方法每更新一次参数都要把数据集里的所有样本都看一遍, ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
随机推荐
- PAT 1145 Hashing - Average Search Time [hash][难]
1145 Hashing - Average Search Time (25 分) The task of this problem is simple: insert a sequence of d ...
- Java中的反射[转载]
转自:https://blog.csdn.net/sinat_38259539/article/details/71799078#commentBox 1.什么是反射? 反射是通过一个类可以知道其中所 ...
- css 自定义滚动条
我遇到的场景: 对于iframe窗口,自带滚动条是整个窗口的大小.有时需要顶部或底部固定,则滚动条不应该触碰到顶部或底部. 那么首先打开iframe时应该去掉滚动条 scrolling="n ...
- 过滤adb logcat 日志
原文地址http://blog.csdn.net/listening_music/article/details/7518990 另外比较好的文章http://blog.csdn.net/liao27 ...
- AviMemDc: a C++ class
AviMemDc: a C++ class This class is used in the Avi Examples.The header fileAviMemDC.h /* ...
- Android 环境搭建资料及启动过程中问题汇总
一.环境搭建资料 推荐谷歌自己开发的Android Studio 工具可以从这个网址下载:http://tools.android-studio.org/,直接下载推荐的就行 二.安装 安装时最好指定 ...
- java 定时器实现
java工程中,不免遇到需要定时处理任务的需求,有如下两种方法: 1.使用java.util.TimerTask 2.使用Quartz 一.java.util.TimerTask Timer time ...
- [转]madwifi无线网卡源代码阅读
转自:http://xiyong8260.blog.163.com/blog/static/66514621200892465922669/ 在我的Doctor课题研究中,基于ARF协议设计了一个改进 ...
- TOSCA自动化测试工具--怎么写自动化用例
1.查看一下要测试的对象属性 2.
- JavaWeb项目中各种路径的获取
以工程名为/DemoWeb为例: 访问的jsp为: http://localhost:8080/DemoWeb/test/index.jsp 1 JSP中获得当前应用的相对路径和绝对路径 (1)得到工 ...