solr6.6 配置拼音分词
1、下载拼音分析包
下载地址:pinyin.zip
解压后放在core下面的lib文件夹下面:
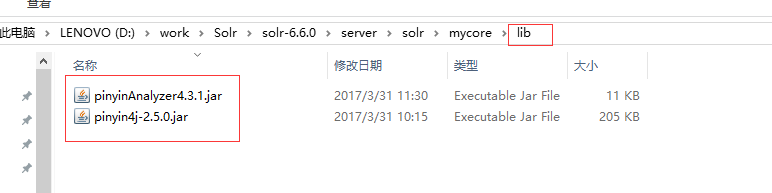
2、修改managed-schema配置文件
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
<field name="text" type="text_smartcn" termVectors="true" indexed="true" stored="true"/>
3、修改solrconfig.xml配置文件
增加如下:
<lib dir="${solr.install.dir:../../../..}/contrib/analysis-extras/lucene-libs" regex="lucene-analyzers-smartcn-6.6.0.jar" />
<lib dir="./lib" regex=".*\.jar"/>

4、测试分析


solr6.6 配置拼音分词的更多相关文章
- Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装.这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索. 一.创建Core: ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- solr 中文分词器IKAnalyzer和拼音分词器pinyin
solr分词过程: Solr Admin中,选择Analysis,在FieldType中,选择text_en 左边框输入 “冬天到了天气冷了小明不想上学去了”,点击右边的按钮,发现对每个字都进行分词. ...
- docker环境下solr6.0配置(中文分词+拼音)
前言:这篇文章是基于之前的“linux环境下配置solr5.3详细步骤”(http://www.cnblogs.com/zhangyuan0532/p/4826740.html)进行扩展的.本篇的步骤 ...
- solr-6.4.2安装+分词器配置
一.solr安装 solr下载地址:http://archive.apache.org/dist/lucene/solr/6.4.2/ 1.解压solr软件包:tar xf solr-6.4.2.tg ...
- solr6.6初探之分词篇
关于solr6.6搭建与配置可以参考 solr6.6初探之配置篇 在这里我们探讨一下分词的配置 一.关于分词 1.分词是指将一个中文词语拆成若干个词,提供搜索引擎进行查找,比如说:北京大学 是一个词那 ...
- Elasticsearch拼音分词和IK分词的安装及使用
一.Es插件配置及下载 1.IK分词器的下载安装 关于IK分词器的介绍不再多少,一言以蔽之,IK分词是目前使用非常广泛分词效果比较好的中文分词器.做ES开发的,中文分词十有八九使用的都是IK分词器. ...
随机推荐
- Winform常用操作
>> c#操作cmd命令 using System.Diagnostics; private string RunCmd(string command) { //实例一个Process类, ...
- Django REST Framework的序列化器是什么?
# 转载请留言联系 用Django开发RESTful风格的API存在着很多重复的步骤.详细可见:https://www.cnblogs.com/chichung/p/9933861.html 过程往往 ...
- eps图片中有中文乱码的问题
一般的,如果matlab中的fig图片中有中文,直接saveas为eps,eps再插入latex后会出现乱码. 解决的办法为: (1) *.fig利用‘file--print’保存为*.pdf (2) ...
- 如何在qt中使用中文输入法
参考: http://blog.csdn.net/u013812682/article/details/52101088 dpkg -L fcitx-frontend-qt5 到qt安装目录里find ...
- sybase ase 重启
sybase ase 重启 https://blog.csdn.net/davidmeng10/article/details/50344305 https://blog.csdn.net/wengy ...
- secureCRT的自动登录设置
具体设置的步骤如下: 1. 打scrt,创建一个新的回话 2. 右击该回话选择属性,定位到左边选项卡的登录动作 3. 第一行:预期是$; 发送是ssh username@machine name 第二 ...
- HDU 2824.The Euler function-筛选法求欧拉函数
欧拉函数: φ(n)=n*(1-1/p1)(1-1/p2)....(1-1/pk),其中p1.p2…pk为n的所有素因子.比如:φ(12)=12*(1-1/2)(1-1/3)=4.可以用类似求素数的筛 ...
- [NOI2018]屠龙勇士(exCRT)
首先很明显剑的选择是唯一的,直接用multiset即可. 接下来可以发现每条龙都是一个模线性方程.设攻击第i条龙的剑的攻击力为$s_i$,则$s_ix\equiv a_i\ (mod\ p_i)$. ...
- AtCoder - 2064 Many Easy Problems
Problem Statement One day, Takahashi was given the following problem from Aoki: You are given a tree ...
- POJ 2348 Euclid's Game(博弈论)
[题目链接] http://poj.org/problem?id=2348 [题目大意] 给出两个数,两个参赛者轮流用一个数减去另一个数的倍数,当一个数为0的时候游戏获胜, 求先手是否必胜 [题解] ...