spark系列-4、spark序列化方案、GC对spark性能的影响
一、spark的序列化
1.1、官网解释
http://spark.apache.org/docs/2.1.1/tuning.html#data-serialization
序列化在任何分布式应用程序的性能中起着重要作用。将对象序列化或消耗大量字节的速度慢的格式将大大减慢计算速度。通常,这将是您应该优化Spark应用程序的第一件事。Spark旨在在便利性(允许您使用操作中的任何Java类型)和性能之间取得平衡。它提供了两个序列化库:
- Java序列化:默认情况下,Spark使用Java ObjectOutputStream框架序列化对象,并且可以与您创建的任何类一起使用java.io.Serializable。您还可以通过扩展来更紧密地控制序列化的性能 java.io.Externalizable。Java序列化是灵活的,但通常很慢,并导致许多类的大型序列化格式。
- Kryo序列化:Spark还可以使用Kryo库(版本2)更快地序列化对象。Kryo比Java序列化(通常高达10倍)显着更快,更紧凑,但不支持所有Serializable类型,并且需要您提前注册您将在程序中使用的类以获得最佳性能。
1.2、Serializable方案
- Serializable方案:你的对象必须继承Serializable接口,类中的属性如果有实例那也必须是继承Serializable 可序列化的。
- 无法序列化:用transient修饰的。java是在修饰属性的最前面使用transient关键字,scala是在修饰属性的最前面使用@transient
- transient的作用是在Serializable序列化的时候,声明某个属性不参与序列化,带来的问题就是如果声明了不参与序列化,那这个属性存储的数据也带不过去了。
1.3、kryo方案
能用于广播变量和shuffle数据传输时候的序列化,外部变量和算子中的代码必须用Serializable
- 设置spark的全序列化:conf.set("spark.serializer", classOf[KryoSerializer].getName)
- 这时spark的全局序列化工具就变成了KryoSerializer而不是默认的Serializable方案了
- 当不设置conf.set("spark.kryo.registrationRequired","true")时,spark的所有对象都默认使用KryoSerializer序列化
- 当设置了conf.set("spark.kryo.registrationRequired","true")时,spark中自定义的类想被KryoSerializer序列化的对象必须得进行注册。
val classes: Array[Class[_]] = Array[Class[_]](classOf[ORCUtil],classOf[StructObjectInspector],classOf[OrcStruct]) //classOf[OrcStruct] OrcStruct:注册的类
conf.set("spark.serializer", classOf[KryoSerializer].getName)
conf.set("spark.kryo.registrationRequired","true")
conf.registerKryoClasses(classes)
如果对象很大,则可能还需要增加
spark.kryoserializer.bufferconfig。该值必须足够大以容纳要序列化的最大对象。
二、GC对spark性能的影响
2.1、频繁GC的影响

2.2、task运行期间动态创建的对象使用的Jvm堆内存的情况
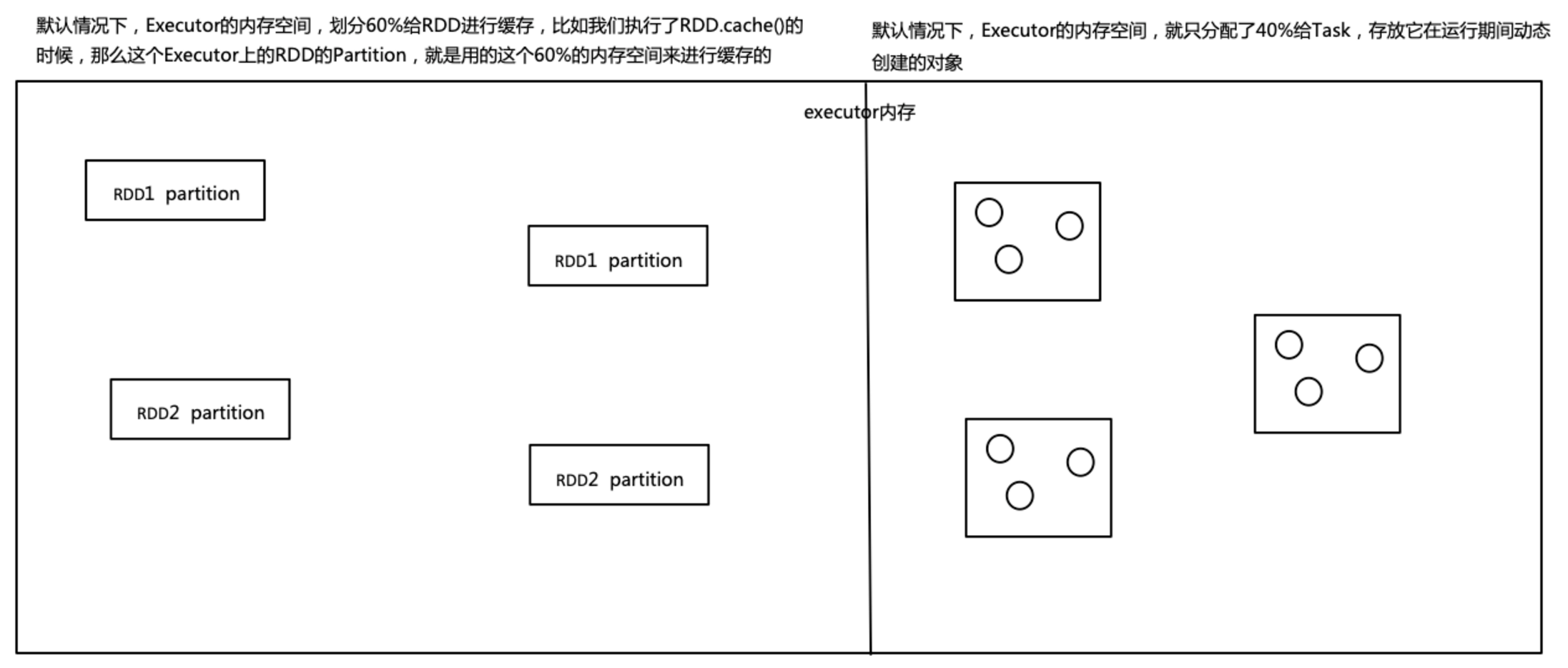
在默认情况下,就是分配给Task运行期间动态创建的内存空间有点小了,就很可能会发生full gc
因为内存小了就会导致,创建的对象很快就把内存空间填满了,然后就会GC了,就是JVM尝试找到那些不再被使用的对象,然后将其回收掉,清除出内存,腾出空间,给Task以后创建的新对象来使用和存放
所以说,如果给Task分配的内存空间小了,可能会频繁的发生GC,从而导致频繁的Task工作线程的停止,从而降低Spark应用程序的性能
解决方法:
- 可以通过调整比例,比如将RDD缓存空间占比调为40%,分配给Task的空间就变为60%,这样的话,至少可以降低GC发生的频率
- 还可以配合降低RDD的使用内存的空间,比如调节序列化的级别为MEMORY_DISK_SER或MEMORY_ONLY_SER,让RDD的partition序列化成一个字节的数组
- 还可以使用Kryo序列化类库,进行序列化,因为kryo序列化方法可以进一步的降低RDD的parition的内存占用量
2.3、JVM的minor gc(小级别)与full gc(大级别)原理
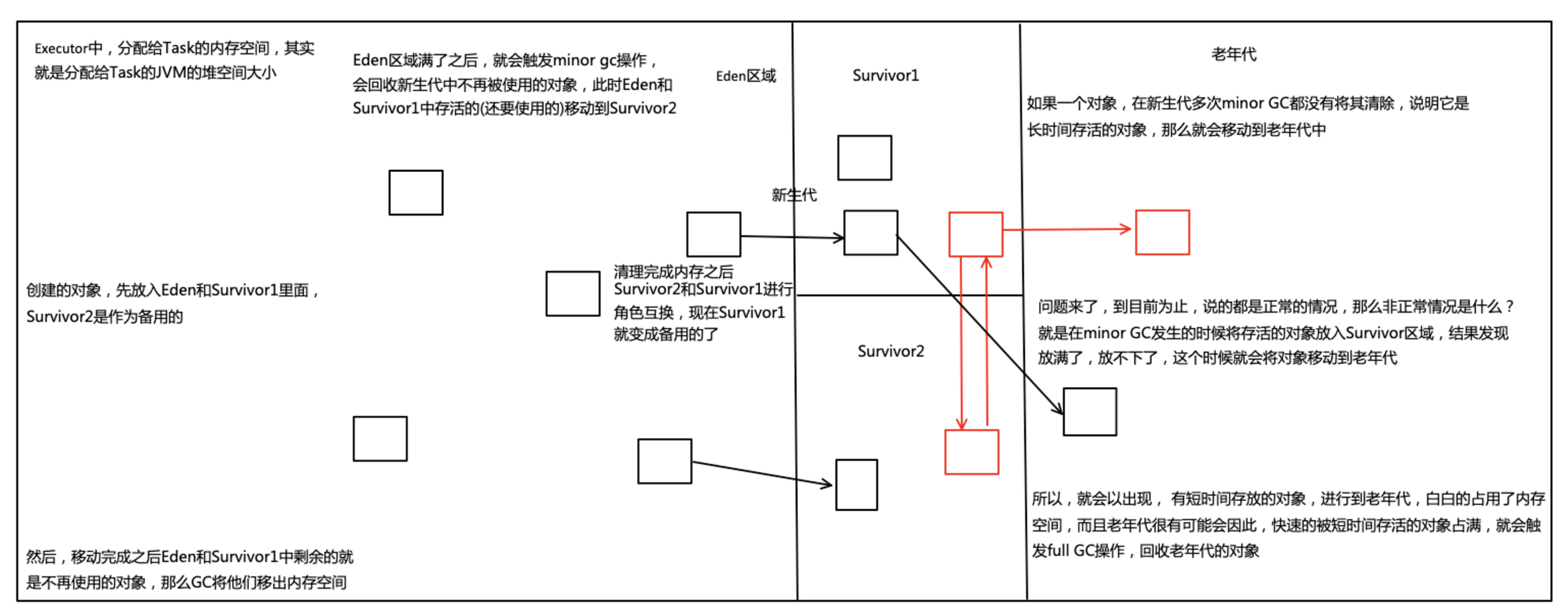
总结:
- 内存分为新生代和老年代,新生代分为Eden和Survivor(有2个)
- 创建的对象,首先放入Eden和Survivor1(可能是短时间)的
- 当Eden满了会启动minor gc,回收新生代中不再使用的对象,还要用的就放到Survivor2中
- 移完之后eden和Survivor1中省下的就是不再使用的对象,就将他们清理掉
- Survivor1和Survivor2交换角色。那就是原来的Survivor1成了备用的了,也就是原来的Survivor2
- 多次在Survivor区没有被清理掉的,说明它是长时间使用的,那么将它移动到老年代,到目前为止世界一切和平
- 由于对象越New越多,minor时发生备用的Survivor区满了,放不进去了,怎么办呢?这个本来可能是短时间生存的对象被放入老年代
- 短时间生存的对象,很可能快速的给老年代占满,白白的浪费老年代的空间,就会触发Full GC,回收老年代的对象
spark系列-4、spark序列化方案、GC对spark性能的影响的更多相关文章
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 在Spark中自定义Kryo序列化输入输出API(转)
原文链接:在Spark中自定义Kryo序列化输入输出API 在Spark中内置支持两种系列化格式:(1).Java serialization:(2).Kryo serialization.在默认情况 ...
- 几种Android数据序列化方案
一.引言 数据的序列化在Android开发中占据着重要的地位,无论是在进程间通信.本地数据存储又或者是网络数据传输都离不开序列化的支持.而针对不同场景选择合适的序列化方案对于应用的性能有着极大的影响. ...
- spark系列-7、spark调优
官网说明:http://spark.apache.org/docs/2.1.1/tuning.html#data-serialization 一.JVM调优 1.1.Java虚拟机垃圾回收调优的背景 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark 系列(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下 ...
- Spark 系列(三)—— 弹性式数据集RDDs
一.RDD简介 RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的.分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD ...
- Spark入门实战系列--7.Spark Streaming(下)--实时流计算Spark Streaming实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源 ...
- Spark系列之二——一个高效的分布式计算系统
1.什么是Spark? Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有H ...
随机推荐
- Vulnhub webdeveloper靶机渗透
信息搜集 nmap -sP 192.168.146.0/24 #主机发现 nmap -A 192.168.146.148 #综合扫描 访问一下发现是wordpress,wp直接上wpscan wpsc ...
- Linux服务器架设篇,Nginx服务器的架设
1.安装 nginx依赖包 (1)安装pcre yum install pcre-devel (2)安装openssl yum -y install openssl-devel (3)安装zlib y ...
- GhostNet: 使用简单的线性变换生成特征图,超越MobileNetV3的轻量级网络 | CVPR 2020
为了减少神经网络的计算消耗,论文提出Ghost模块来构建高效的网络结果.该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过简单的线性变化操作来进一步高效地生成ghost特 ...
- 09-soap接口类型进行测试webservice协议
webxml.com.cn/zh_cn/weather_icon.aspx webxml.com.cn/webservices/weatherWS.asmx? 以上2个url可用来免费使用(经典场景) ...
- Linux c++ vim环境搭建系列(1)——Ubuntu18.04.4编译安装vim8.2
1. vim源码编译安装 参考网址: https://github.com/ycm-core/YouCompleteMe/wiki/Building-Vim-from-source 安装各类依赖库 s ...
- 使用docker-compose编写常规的lnmp容器,pdo连接mysql失败。
问题的核心是yii2 是通过pdo的方式去连接数据的.但是我们通过容器去搭建lnmp环境时,nginx , php , mysql 这三个服务是独立的三个容器,彼此隔离.所以在yii2中连接mysql ...
- Linux中vim编辑器 的 快捷键 --- 常用 的 都比较全
Linux中vim编辑器的功能非常强大,许多常用快捷键用起来非常方便,这里将我学vim入门时学的一些常用的快捷键分享给大家一下,希望可以帮助你们. 这个是我将鸟哥书上的进行了一下整理的,希望不要涉及到 ...
- JAVA+HttpServletRequest文件上传
public Result fileUp(HttpServletRequest request) { RowsVo vo = new RowsVo(); MultipartHttpServletReq ...
- 爬取腾讯网的热点新闻文章 并进行词频统计(Python爬虫+词频统计)
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:一棵程序树 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 学会这项python技能,就再也不怕孩子偷偷打游戏了
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:鸟哥 PS:如果想了解更多关于python的应用,可以私信小编,资料 ...