HBase编程 API入门系列之delete.deleteColumn和delete.deleteColumns区别(客户端而言)(4)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了。
delete.deleteColumn和delete.deleteColumns区别是:
deleteColumn是删除某一个列簇里的最新时间戳版本。
delete.deleteColumns是删除某个列簇里的所有时间戳版本。

hbase(main):020:0> desc 'test_table'
Table test_table is ENABLED
test_table
COLUMN FAMILIES DESCRIPTION
{NAME => 'f', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS
=> 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
1 row(s) in 0.2190 seconds
hbase(main):021:0> scan 'test_table'
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478104823358, value=Andy3
3 row(s) in 0.2270 seconds
hbase(main):022:0> scan 'test_table'
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478104823358, value=Andy3
3 row(s) in 0.1480 seconds
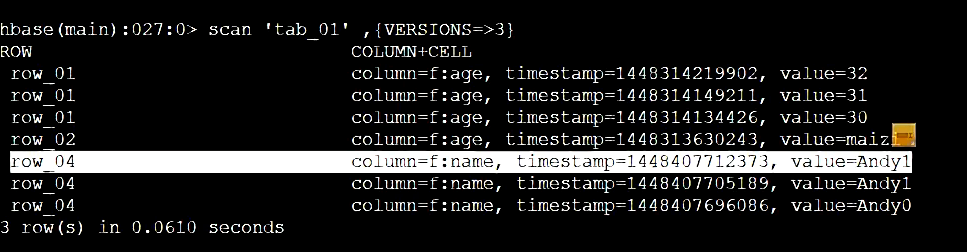
hbase(main):023:0> scan 'test_table',{VERSIONS=>3}
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478104823358, value=Andy3
3 row(s) in 0.1670 seconds
hbase(main):024:0>
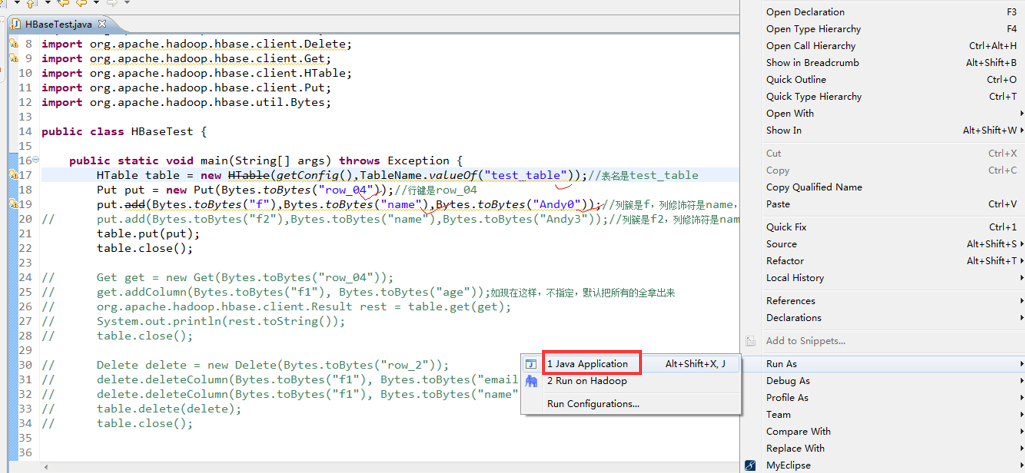
package zhouls.bigdata.HbaseProject.Test1; import javax.xml.transform.Result; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes; public class HBaseTest {
public static void main(String[] args) throws Exception {
HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table
Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04
put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy0"));//列簇是f,列修饰符是name,值是Andy0
// put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3
table.put(put);
table.close(); // Get get = new Get(Bytes.toBytes("row_04"));
// get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来
// org.apache.hadoop.hbase.client.Result rest = table.get(get);
// System.out.println(rest.toString());
// table.close(); // Delete delete = new Delete(Bytes.toBytes("row_2"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close(); // Delete delete = new Delete(Bytes.toBytes("row_03"));
// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close();
} public static Configuration getConfig(){
Configuration configuration = new Configuration();
// conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase");
configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181");
return configuration;
}
}
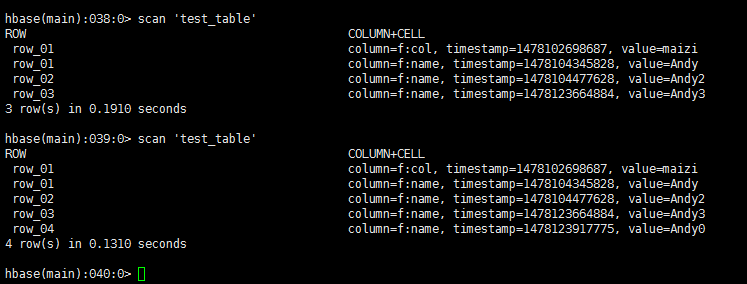
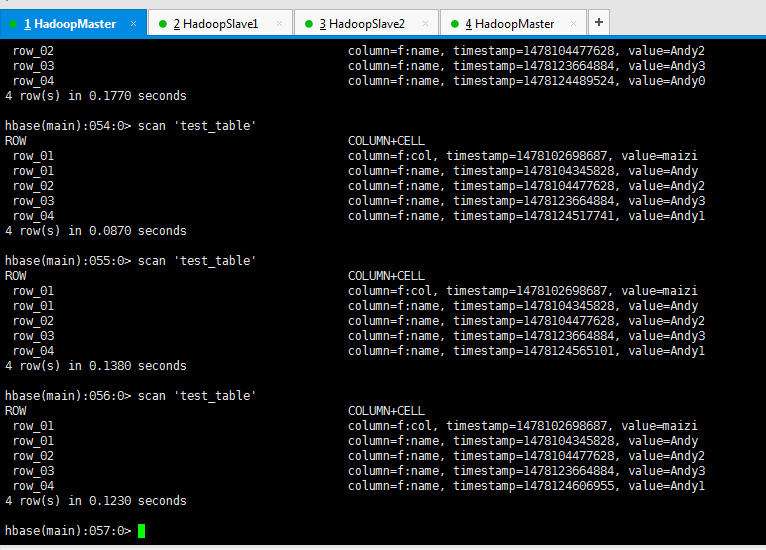
hbase(main):038:0> scan 'test_table'
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478123664884, value=Andy3
3 row(s) in 0.1910 seconds
hbase(main):039:0> scan 'test_table'
ROW COLUMN+CELL
row_01 column=f:col, timestamp=1478102698687, value=maizi
row_01 column=f:name, timestamp=1478104345828, value=Andy
row_02 column=f:name, timestamp=1478104477628, value=Andy2
row_03 column=f:name, timestamp=1478123664884, value=Andy3
row_04 column=f:name, timestamp=1478123917775, value=Andy0
4 row(s) in 0.1310 seconds
delete.deleteColumn和delete.deleteColumns区别是:
deleteColumn是删除某一个列簇里的最新时间戳版本。
delete.deleteColumns是删除某个列簇里的所有时间戳版本。
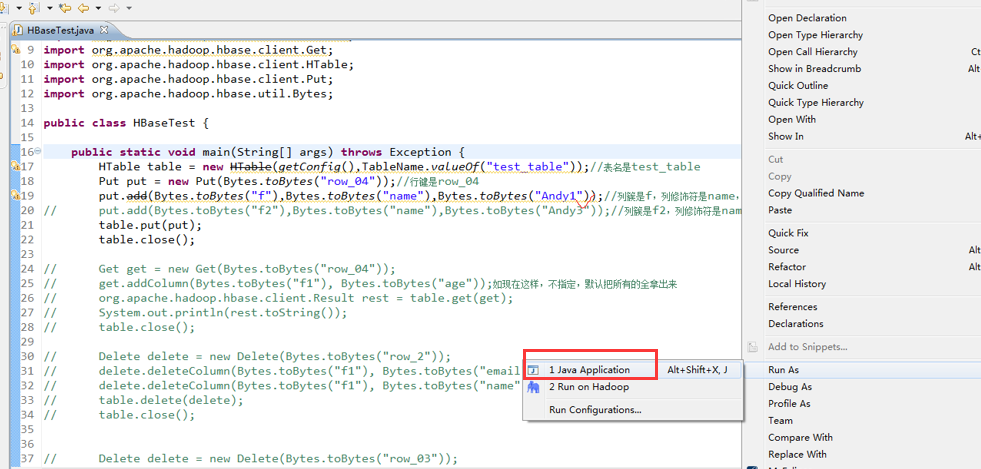
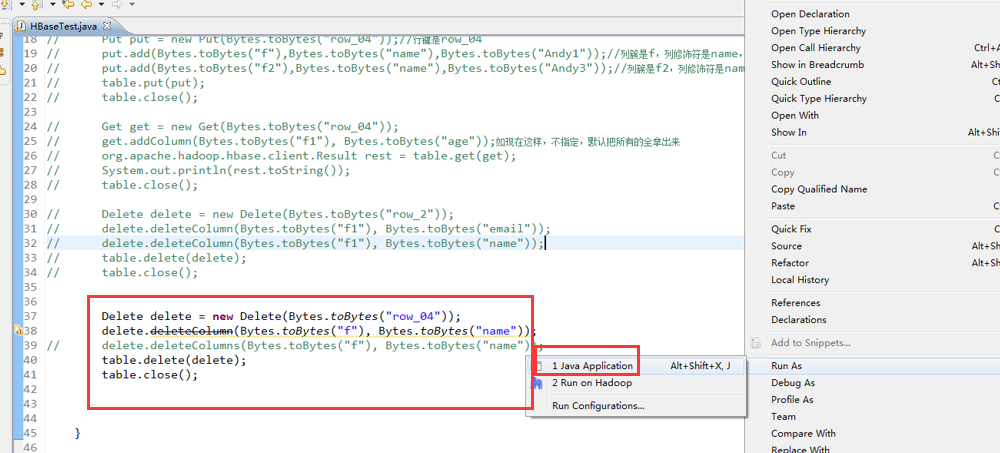
package zhouls.bigdata.HbaseProject.Test1; import javax.xml.transform.Result; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes; public class HBaseTest {
public static void main(String[] args) throws Exception {
HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table
Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04
put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy1"));//列簇是f,列修饰符是name,值是Andy0
// put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3
table.put(put);
table.close(); // Get get = new Get(Bytes.toBytes("row_04"));
// get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来
// org.apache.hadoop.hbase.client.Result rest = table.get(get);
// System.out.println(rest.toString());
// table.close(); // Delete delete = new Delete(Bytes.toBytes("row_2"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close(); // Delete delete = new Delete(Bytes.toBytes("row_03"));
// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close();
} public static Configuration getConfig(){
Configuration configuration = new Configuration();
// conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase");
configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181");
return configuration;
}
}
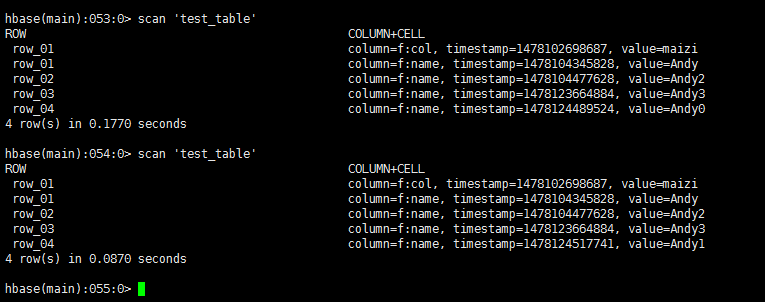


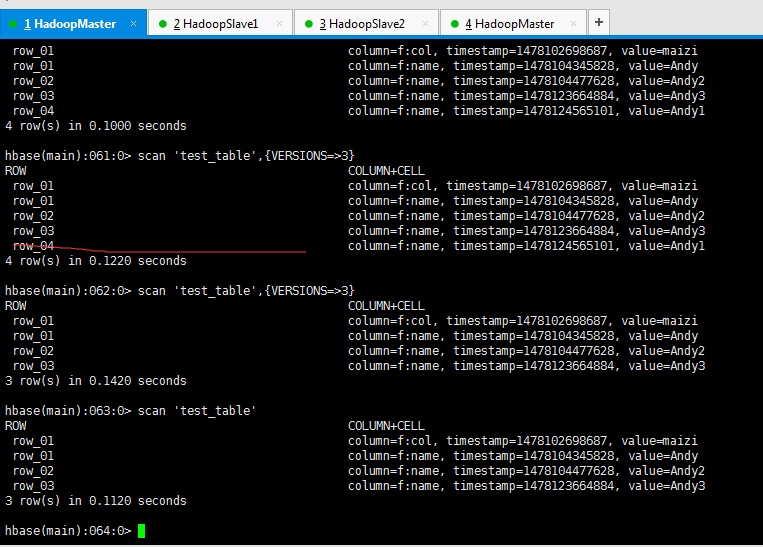
delete.deleteColumn和delete.deleteColumns区别是:
deleteColumn是删除某一个列簇里的最新时间戳版本。
delete.deleteColumns是删除某个列簇里的所有时间戳版本。


HBase编程 API入门系列之delete.deleteColumn和delete.deleteColumns区别(客户端而言)(4)的更多相关文章
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之HTable pool(6)
HTable是一个比较重的对此,比如加载配置文件,连接ZK,查询meta表等等,高并发的时候影响系统的性能,因此引入了“池”的概念. 引入“HBase里的连接池”的目的是: 为了更高的,提高程序的并发 ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
- HBase编程 API入门系列之delete(管理端而言)(9)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门之delete(客户端而言) 就知道,在这篇博文里,我是在客户端里删除HBase表的. 这里,我带领大家,学习更高级的,因为,在开发中 ...
- HBase编程 API入门系列之modify(管理端而言)(10)
这里,我带领大家,学习更高级的,因为,在开发中,尽量不能去服务器上修改表. 所以,在管理端来修改HBase表.采用线程池的方式(也是生产开发里首推的) package zhouls.bigdata.H ...
- HBase编程 API入门系列之scan(客户端而言)(5)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. package zhouls.bigdata.HbaseProject.Test1; import javax.xml.trans ...
- HBase编程 API入门系列之工具Bytes类(7)
这是从程度开发层面来说,为了方便和提高开发人员. 这个工具Bytes类,有很多很多方法,帮助我们HBase编程开发人员,提高开发. 这里,我只赘述,很常用的! package zhouls.bigda ...
- HBase编程 API入门系列之put(客户端而言)(1)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. [hadoop@HadoopSlave1 conf]$ cat regionservers HadoopMasterHadoopS ...
随机推荐
- WebGL画点程序v1
本文程序实现画一个点的任务,如下图.其中,点的位置直接给定("硬编码")在顶点着色器中. 整个程序包含两个文件,分别是: 1. HelloPoint1.html <!DOCT ...
- js-构造数组
js中,字符串的特性跟数组非常类似.数组是一种很重要的数据结构.在java中,数组声明的时候就要为其指定类型,数组中只能放同一种类型的数据.Js中的数组可以放不同的类型,但是是有序的,类似于java中 ...
- 团体程序设计天梯赛-练习集-L1-046. 整除光棍
L1-046. 整除光棍 这里所谓的“光棍”,并不是指单身汪啦~ 说的是全部由1组成的数字,比如1.11.111.1111等.传说任何一个光棍都能被一个不以5结尾的奇数整除.比如,111111就可以被 ...
- gitlab变更邮箱后发送邮件报SSLError错误
测试发送邮件: gitlab-rails console Notify.test_email('test666@example.com', 'Message Subject', 'Message Bo ...
- centos6.5 安装Python3.6.0
首先安装python3.6可能使用的依赖 # yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel ...
- 15.5.4 【Task实现细节】一个入口搞定一切
如果你反编译过异步方法(我非常希望你会这么做),会看到状态机中的 MoveNext() 方法 非常长,变化非常快,像是一个计算有多少 await 表达式的函数.它包含原始方法中的所有逻辑, 和处理所有 ...
- 15.3 Task 异常
1. 在等待时拆包异常 在等待任务时,任务出错或取消都将抛出异常,但并不是 AggregateException .大多情 况下为方便起见,抛出的是 AggregateException 中的第一个异 ...
- java环境搭建心得
右击此电脑,点击属性, 在打开的电脑系统对话框里发电机i直接点击左侧导航里的[高级系统设置]在打开的电脑系统属性对话框里直接点击下面的[环境变量] 打开环境变量对话框后,直接点击系统变量下面的新建, ...
- [USACO10DEC]宝箱Treasure Chest
区间DP,但是卡空间. n2的就是f[i,j]=sum[i,j]-min(f[i+1][j],f[i][j-1])表示这个区间和减去对手取走的最多的. 但是空间是64MB,就很难受 发现一定是由大区间 ...
- Java异常以及继承的一些问题
Java异常以及继承的一些问题 http://blog.csdn.net/hguisu/article/details/6155636 https://www.cnblogs.com/skywang1 ...