python3+selenium3+requests爬取我的博客粉丝的名称
爬取目标
1.本次代码是在python3上运行通过的
- selenium3 +firefox59.0.1(最新)
- BeautifulSoup
- requests
2.爬取目标网站,我的博客:https://home.cnblogs.com/u/lxs1314
爬取内容:爬我的博客的所有粉丝的名称,并保存到txt
3.由于博客园的登录是需要人机验证的,所以是无法直接用账号密码登录,需借助selenium登录
直接贴代码:
# coding:utf-8
# __author__ = 'Carry' import requests
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import time # firefox浏览器配置文件地址
profile_directory = r'C:\Users\Administrator\AppData\Roaming\Mozilla\Firefox\Profiles\pxp74n2x.default' s = requests.session() # 新建session
url = "https://home.cnblogs.com/u/lxs1314" def get_cookies(url):
'''启动selenium获取登录的cookies'''
# 加载配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
driver = webdriver.Firefox(profile)
driver.get(url+"/followers") time.sleep(3)
cookies = driver.get_cookies() # 获取浏览器cookies
print(cookies)
driver.quit()
return cookies def add_cookies(cookies):
'''往session添加cookies'''
# 添加cookies到CookieJar
c = requests.cookies.RequestsCookieJar()
for i in cookies:
c.set(i["name"], i['value']) s.cookies.update(c) # 更新session里cookies def get_ye_nub(url):
# 发请求
r1 = s.get(url+"/relation/followers")
soup = BeautifulSoup(r1.content, "html.parser")
# 抓取我的粉丝数
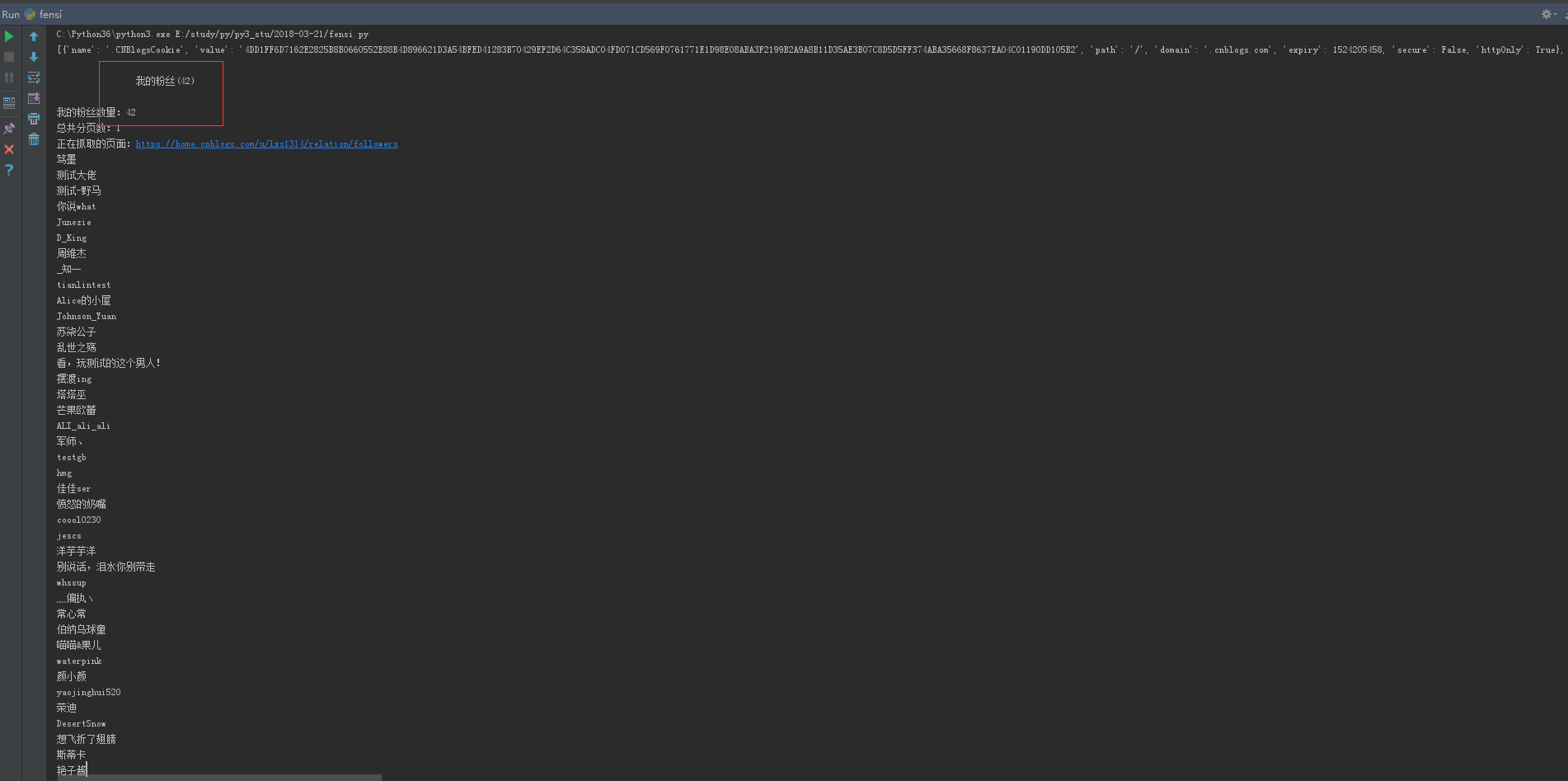
fensinub = soup.find_all(class_="current_nav")
print (fensinub[0].string)
num = re.findall(u"我的粉丝\((.+?)\)", fensinub[0].string)
print (u"我的粉丝数量:%s"%str(num[0])) # 计算有多少页,每页45条
ye = int(int(num[0])/45)+1
print (u"总共分页数:%s"%str(ye))
return ye def save_name(nub):
# 抓取第一页的数据
if nub <= 1:
url_page = url+"/relation/followers"
else:
url_page = url+"/relation/followers?page=%s" % str(nub)
print (u"正在抓取的页面:%s" %url_page)
r2 = s.get(url_page)
soup = BeautifulSoup(r2.content, "html.parser")
fensi = soup.find_all(class_="avatar_name")
for i in fensi:
name = i.string.replace("\n", "").replace(" ","")
print (name)
with open("name.txt", "a") as f: # 追加写入
f.write(name+"\n")
#name.encode("utf-8") if __name__ == "__main__":
cookies = get_cookies(url)
add_cookies(cookies)
n = get_ye_nub(url)
for i in range(1, n+1):
save_name(i)
原文链接:http://www.cnblogs.com/yoyoketang/p/8610779.html
python3+selenium3+requests爬取我的博客粉丝的名称的更多相关文章
- python+selenium+requests爬取我的博客粉丝的名称
爬取目标 1.本次代码是在python2上运行通过的,python3的最需改2行代码,用到其它python模块 selenium 2.53.6 +firefox 44 BeautifulSoup re ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一 ...
- python3使用requests爬取新浪热门微博
微博登录的实现代码来源:https://gist.github.com/mrluanma/3621775 相关环境 使用的python3.4,发现配置好环境后可以直接使用pip easy_instal ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- step2: 爬取廖雪峰博客
#https://zhuanlan.zhihu.com/p/26342933 #https://zhuanlan.zhihu.com/p/26833760 scrapy startproject li ...
- scrapy 爬取自己的博客
定义项目 # -*- coding: utf-8 -*- # items.py import scrapy class LianxiCnblogsItem(scrapy.Item): # define ...
- requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来. 首先进行url分析,可以看到: 歌手网页: 薛之谦网页: 可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码: # -*- ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
随机推荐
- python面试题(二)
最近参加了几场招聘,发现好多人的一些基础知识不是很扎实,做的题很多都是错误的,因此找了一些我们公司面试过程中的一些最基本的面试题供大家参考,希望各位都能找到一个好的工作.今天给大家先分享的是关于Pyt ...
- 浅谈HTTP中GET和POST请求方式的区别
浅谈HTTP中GET和POST请求的区别 HTTP认知: HTTP是基于TCP/IP的关于数据如何在万维网中如何通信的协议.HTTP的底层是TCP/IP.所以GET和POST的底层也是TCP/IP,也 ...
- krkr基础篇(一)
krkr基础篇是我根据krkr的官方教程总结而来 推荐代替记事本的工具:editplus,点我下载 激活码:Vovan 3AG46-JJ48E-CEACC-8E6EW-ECUAW 一:创建新工程 1: ...
- Shader食谱 Chapter3--Toonshader卡通效果
Shader食谱 Chapter3--Toonshader卡通效果 unity shader toon 卡通Shader Shader食谱 Chapter3--Toonshader卡通效果 Over ...
- SNMP TRAP报文解析
转载地址: https://blog.csdn.net/eric_sunah/article/details/19557683 SNMP的报文格式 SNMP代理和管理站通过SNMP协议中的标准消息进行 ...
- UVa 10055
说一下犯错的地方: 1)没有注意数据范围,题目中是The input numbers are not greater than balabalabala. 而这个32位的int类型恰好装不下2^32, ...
- 学员管理系统(SQLAlchemy 实现)
一.业务逻辑 二.设计表结构 三.代码结构 start.py import os, sys sys.path.insert(0, os.path.dirname(os.path.dirname(os. ...
- Mysql数据库的隔离级别
Mysql数据库的隔离级别有四种 1.read umcommitted 读未提交(当前事务可以读取其他事务没提交的数据,会读取到脏数据) 2.read committed 读已提交(当前事务不能读 ...
- iOS中使用RNCryptor对资源文件加密(先加密后拖进项目中)
概述:IPA 在发布时,业务相关的敏感资源文件以明文的形式存储,由于没有加密保护,这些文件在应用发布后 可能被其他人获取,并结合其他漏洞和手段产生真实攻击.所以我们要 1.在设计.开发阶段,集合业务确 ...
- iOS 动态库、静态库 . framework 总结(2017.1.25 修改)
修改于2017.1.25 使用Xcode Version 8.2.1 1.怎么创建.framework? 打开Xcode, 选择File ----> New ---> Project 选择 ...