在Hadoop集群上的HBase配置
之前,我们已经在hadoop集群上配置了Hive,今天我们来配置下Hbase。
一、准备工作
1.ZooKeeper下载地址:http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
2.Hbase下载地址:http://mirrors.shuosc.org/apache/hbase/stable/hbase-1.2.6-bin.tar.gz
二、ZooKeeper集群安装配置
1.下载ZooKeeper

2.解压下载的安装包


3.将解压的目录移动到安装目录


4.配置系统环境变量

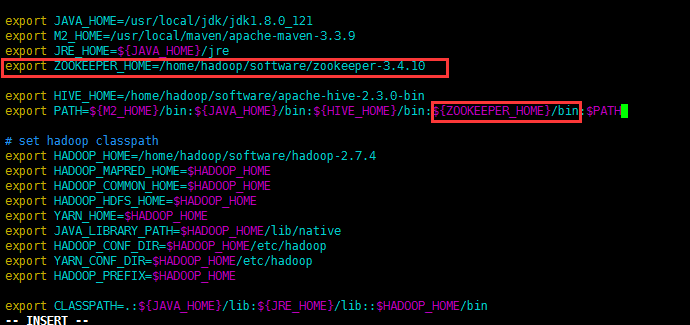
5.使配置生效

6.将conf目录下的zoo_sample.cfg文件拷贝一份,命名为为:zoo.cfg

7.配置zoo.cfg文件

a>.tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳
b>.initLimit:Zookeeper的Leader 接受客户端(Follower)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
c>.syncLimit:表示 Leader 与 Follower 之间发送消息时请求和应答时间长度,最长不能超过多少个tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
d>.clientPort:客户端连接端口
e>.dataDir:数据目录
f>.dataLogDir:日志目录
g>.server.A=B:C:D:其中A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
8.在dataDir目录下创建myid文件

master机器的内容为0,slave1机器的内容为1,slave2机器的内容为2,这些内容对应conf目录下zoo.cfg配置中的server.A中的A。若有更多依此类推
9.在master节点上将配置好的zookeeper分发给各个slave


注:再次提醒别忘了更改/home/hadoop/software/zookeeper-3.4.10/data/myid和/etc/profile中zookeeper的环境变量配置
10.启动zookeeper服务

注:需要在master和slave机上都启动。输入jps命令查看进程,其中,QuorumPeerMain是zookeeper进程,表示启动成功。
11.查看zookeeper状态

显示为leader或者follower
12.停止zookeeper服务

三、Hbase安装配置
1.解压Hbase压缩包

2.将解压的目录移动到安装配置目录

3.将Hbase安装目录配置到环境变量中


4.修改文件conf/hbase-env.sh,修改内容如下
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_121
export HBASE_MANAGES_ZK=false//true为使用Hbase自带ZK,false为使用独

5.修改conf/hbase-site.xml,修改内容如下
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/software/hbase-1.2.6/zookeeper_tmp</value>
</property>
</configuration>

备注:在上面的配置文件中,第一个属性指定本机的hbase的存储目录;第二个属性指定hbase的运行模式,true代表全分布模式;第三和第四个属性是关于Zookeeper集群的配置。我的Zookeeper安装在master,slave1和slave2上。
5.修改conf/regionservers文件,修改内容如下
master
slave1
slave2
注意:一般 regionservers 不在 master 上部署。
6.将Hbase拷贝到 slave节点同样目录下,并将Hbase安装目录配置到slave节点的环境变量中

四、启动集群
1.启动启动ZooKeeper(每个节点都需要启动)

2.在master启动hadoop

3.在master启动hive


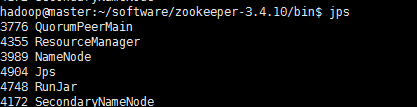
slave节点:

4.在master启动hbase
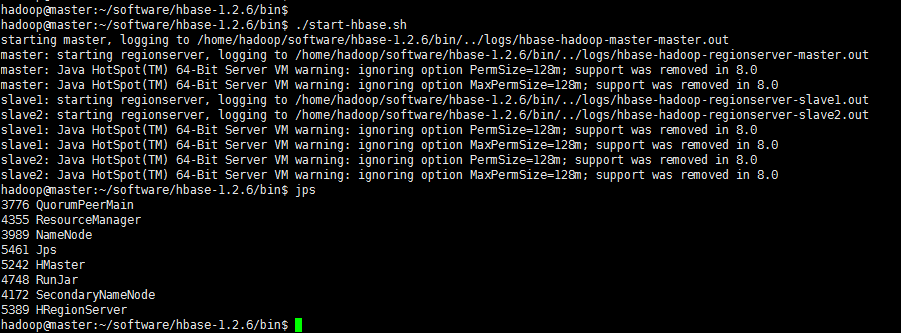
slave节点:

5.通过浏览器查看:输入:http://192.168.19.128:16030

6.进人和退出hbase的shell
进人hbase的shell的命令:hbase shell

退出hbase的shell命令:exit

在Hadoop集群上的HBase配置的更多相关文章
- 在Hadoop集群上,搭建HBase集群
(1)下载Hbase包,并解压:这里下载的是0.98.4版本,对应的hadoop-1.2.1集群 (2)覆盖相关的包:在这个版本里,Hbase刚好和Hadoop集群完美配合,不需要进行覆盖. 不过这里 ...
- 在Hadoop集群上的Hive配置
1. 系统环境Oracle VM VirtualBoxUbuntu 16.04Hadoop 2.7.4Java 1.8.0_111 hadoop集群master:192.168.19.128slave ...
- 沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase 一.安装准备 首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安 ...
- Hadoop集群上搭建Ranger
There are two types of people in the world. I hate both of them. Hadoop集群上搭建Ranger 在搭建Ranger工程之前,需要完 ...
- Hadoop集群搭建-02安装配置Zookeeper
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- Hadoop集群上使用JNI,调用资源文件
hadoop是基于java的数据计算平台,引入第三方库,例如C语言实现的开发包将会大大增强数据分析的效率和能力. 通常在是用一些工具的时候都要用到一些配置文件.资源文件等.接下来,借一个例子来说明ha ...
- hadoop 把mapreduce任务从本地提交到hadoop集群上运行
MapReduce任务有三种运行方式: 1.windows(linux)本地调试运行,需要本地hadoop环境支持 2.本地编译成jar包,手动发送到hadoop集群上用hadoop jar或者yar ...
- [转载] 把Nutch爬虫部署到Hadoop集群上
http://f.dataguru.cn/thread-240156-1-1.html 软件版本:Nutch 1.7, Hadoop 1.2.1, CentOS 6.5, JDK 1.7 前面的3篇文 ...
- 把Nutch爬虫部署到Hadoop集群上
原文地址:http://cn.soulmachine.me/blog/20140204/ 把Nutch爬虫部署到Hadoop集群上 Feb 4th, 2014 | Comments 软件版本:Nutc ...
随机推荐
- 测验2: Python基础语法(上) (第4周)
快乐的数字 描述 编写一个算法来确定一个数字是否“快乐”. 快乐的数字按照如下方式确定:从一个正整数开始,用其每位数的平方之和取代该数,并重复这个过程,直到最后数字要么收敛等于1且一直等于1,要么将无 ...
- thu-learn-lib 开发小记(转)
原创:https://harrychen.xyz/2019/02/09/thu-learn-lib/ 今天是大年初五,原本计划出门玩,但是天气比较糟糕就放弃了.想到第一篇博客里面预告了要给thu-le ...
- Linux系统minicom命令详解
minicom 功能说明:调制解调器通信程序 语 法:minicom [-8lmMostz][-a<on或0ff>][-c<on或off>][-C<取文件>][-d ...
- node.js中通过dgram数据报模块创建UDP服务器和客户端
node.js中 dgram 模块提供了udp数据包的socket实现,可以方便的创建udp服务器和客户端. 一.创建UDP服务器和客户端 服务端: const dgram = require('dg ...
- Solidity类型Uint类型区分?
1. Solidity中默认 Uint 也就是Uint256, 也就是 无符号 256位整数范围,即 2的 256次方 减一的 10进制范围, 预计大小为: 115792089237316195423 ...
- charles本地调试之map和rewrite功能
charles是一款mac下代理调试工具,对于前端开发同学来说是相当方便的一个调试接口的工具:不过charles需要收费,不过在天朝几乎收费的软件都能找到破解方法: 使用charles前,需要将cha ...
- zeromq学习记录(一)最初的简单示例使用ZMQ_REQ ZMQ_REP
阅读zeromq guide的一些学习记录 zeromq官方例子 在VC下运行会有些跨平台的错误 我这里有做修改 稍后会发布出来 相关的代码与库 http://download.zeromq.org ...
- C# Winform 登录中的忘记密码及自动登录
本地保存登录账号实现忘记密码及自动登录 #region 删除本地自动登录及记住密码信息 /// <summary> /// 删除本地自动登录及记住密码信息 /// </summary ...
- margin和padding的用法与区别--以及bug处理方式
margin和padding的用法: (1)padding (margin) -left:10px; 左内 (外) 边距(2)padding (margin) -right:10px; 右内 (外 ...
- Transform Model
self attention Q=K=V :输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算,目的是要学习句子内部词之间的依赖关系,捕获句子的内部结构. 首先,要buil ...