[MapReduce_add_3] MapReduce 通过分区解决数据倾斜
0. 说明
数据倾斜及解决方法的介绍与代码实现
1. 介绍
【1.1 数据倾斜的含义】
大量数据发送到同一个节点进行处理,造成此节点繁忙甚至瘫痪,而其他节点资源空闲
【1.2 解决数据倾斜的方式】
重新设计 Key(配合二次 MR 使用)
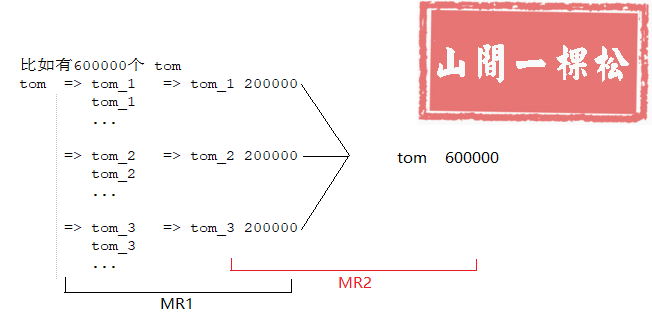
随机分区
伪代码如下:
RandomPartition extends Partitioner{
return r.nextInt()
}
2. 重新设计 Key 代码编写
[2.1 WCMapper.java]
package hadoop.mr.dataskew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
import java.util.Random; /**
* Mapper 程序
* 重新设计 Key
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Random r = new Random();
int i; @Override
protected void setup(Context context) throws IOException, InterruptedException {
// 获取 reduce 的个数
i = context.getNumReduceTasks();
} /**
* map 函数,被调用过程是通过 while 循环每行调用一次
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将 value 变为 String 格式
String line = value.toString();
// 将一行文本进行截串
String[] arr = line.split(" "); for (String word : arr) { String newWord = word + "_" + r.nextInt(i); context.write(new Text(newWord), new IntWritable(1));
} }
}
[2.2 WCReducer.java]
package hadoop.mr.dataskew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* Reducer 类
*/
public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* 通过迭代所有的 key 进行聚合
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0; for (IntWritable value : values) {
sum += value.get();
} context.write(key,new IntWritable(sum));
}
}
[2.3 WCMapper2.java]
package hadoop.mr.dataskew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* Mapper 程序2
* 重新设计 Key
*/
public class WCMapper2 extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* map 函数,被调用过程是通过 while 循环每行调用一次
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将 value 变为 String 格式
String line = value.toString();
// 切割一行文本分为 key 和 value
String[] arr = line.split("\t"); String word = arr[0]; Integer count = Integer.parseInt(arr[1]); // 重新设计 Key
String newWord = word.split("_")[0]; context.write(new Text(newWord), new IntWritable(count)); }
}
[2.4 WCReducer2.java]
package hadoop.mr.dataskew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* Reducer 类2
*/
public class WCReducer2 extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* 通过迭代所有的 key 进行聚合
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0; for (IntWritable value : values) {
sum += value.get();
} context.write(key,new IntWritable(sum));
}
}
[2.5 WCApp.java]
package hadoop.mr.dataskew; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 解决数据倾斜
*/
public class WCApp {
public static void main(String[] args) throws Exception {
// 初始化配置文件
Configuration conf = new Configuration(); // 仅在本地开发时使用
conf.set("fs.defaultFS", "file:///"); // 初始化文件系统
FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job
Job job = Job.getInstance(conf); // 设置 job 名称
job.setJobName("data skew"); // job 入口函数类
job.setJarByClass(WCApp.class); // 设置 mapper 类
job.setMapperClass(WCMapper.class); // 设置 reducer 类
job.setReducerClass(WCReducer.class); // 设置分区数量
job.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径
Path pin = new Path("E:/test/wc/dataskew.txt");
Path pout = new Path("E:/test/wc/out");
// Path pin = new Path(args[0]);
// Path pout = new Path(args[1]);
FileInputFormat.addInputPath(job, pin);
FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除
if (fs.exists(pout)) {
fs.delete(pout, true);
} // 执行 job
boolean b = job.waitForCompletion(true); if (b) {
// 通过配置文件初始化 job
Job job2 = Job.getInstance(conf); // 设置 job 名称
job2.setJobName("data skew2"); // job 入口函数类
job2.setJarByClass(WCApp.class); // 设置 mapper 类
job2.setMapperClass(WCMapper2.class); // 设置 reducer 类
job2.setReducerClass(WCReducer2.class); // 设置分区数量
// job2.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径
Path pin2 = new Path("E:/test/wc/out");
Path pout2 = new Path("E:/test/wc/out2");
// Path pin = new Path(args[0]);
// Path pout = new Path(args[1]);
FileInputFormat.addInputPath(job2, pin2);
FileOutputFormat.setOutputPath(job2, pout2); // 判断输出路径是否已经存在,若存在则删除
if (fs.exists(pout2)) {
fs.delete(pout2, true);
} // 执行 job
job2.waitForCompletion(true);
}
}
}
3. 随机分区代码编写
[3.1 WCMapper.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* Mapper 程序
* 重新设计 Key
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /**
* map 函数,被调用过程是通过 while 循环每行调用一次
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将 value 变为 String 格式
String line = value.toString(); // 将一行文本进行截串
String[] arr = line.split(" "); for (String word : arr) {
context.write(new Text(word), new IntWritable(1));
} }
}
[3.2 WCReducer.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* Reducer 类
*/
public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* 通过迭代所有的 key 进行聚合
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0; for (IntWritable value : values) {
sum += value.get();
} context.write(key, new IntWritable(sum));
}
}
[3.3 WCMapper2.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* Mapper 程序2
* 重新设计 Key
*/
public class WCMapper2 extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* map 函数,被调用过程是通过 while 循环每行调用一次
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将 value 变为 String 格式
String line = value.toString();
// 切割一行文本分为 key 和 value
String[] arr = line.split("\t"); String word = arr[0]; Integer count = Integer.parseInt(arr[1]); context.write(new Text(word), new IntWritable(count)); }
}
[3.4 RandomPartitioner.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; import java.util.Random; /**
* 随机分区类
*/
public class RandomPartitioner extends Partitioner<Text, IntWritable> { Random r = new Random(); @Override
public int getPartition(Text text, IntWritable intWritable, int numPartitions) {
return r.nextInt(numPartitions);
}
}
[3.5 WCApp.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 随机分区解决数据倾斜
*/
public class WCApp {
public static void main(String[] args) throws Exception {
// 初始化配置文件
Configuration conf = new Configuration(); // 仅在本地开发时使用
conf.set("fs.defaultFS", "file:///"); // 初始化文件系统
FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job
Job job = Job.getInstance(conf); // 设置 job 名称
job.setJobName("data skew"); // job 入口函数类
job.setJarByClass(WCApp.class); // 设置 mapper 类
job.setMapperClass(WCMapper.class); // 设置 reducer 类
job.setReducerClass(WCReducer.class); // 设置 partition 类
job.setPartitionerClass(RandomPartitioner.class); // 设置分区数量
job.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径
Path pin = new Path("E:/test/wc/dataskew.txt");
Path pout = new Path("E:/test/wc/out");
// Path pin = new Path(args[0]);
// Path pout = new Path(args[1]);
FileInputFormat.addInputPath(job, pin);
FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除
if (fs.exists(pout)) {
fs.delete(pout, true);
} // 执行 job
boolean b = job.waitForCompletion(true); if (b) {
// 通过配置文件初始化 job
Job job2 = Job.getInstance(conf); // 设置 job 名称
job2.setJobName("data skew2"); // job 入口函数类
job2.setJarByClass(hadoop.mr.dataskew.WCApp.class); // 设置 mapper 类
job2.setMapperClass(WCMapper2.class); // 设置 reducer 类
job2.setReducerClass(WCReducer.class); // 设置分区数量
// job2.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径
Path pin2 = new Path("E:/test/wc/out");
Path pout2 = new Path("E:/test/wc/out2");
// Path pin = new Path(args[0]);
// Path pout = new Path(args[1]);
FileInputFormat.addInputPath(job2, pin2);
FileOutputFormat.setOutputPath(job2, pout2); // 判断输出路径是否已经存在,若存在则删除
if (fs.exists(pout2)) {
fs.delete(pout2, true);
} // 执行 job
job2.waitForCompletion(true);
} }
}
[MapReduce_add_3] MapReduce 通过分区解决数据倾斜的更多相关文章
- Hadoop_22_MapReduce map端join实现方式解决数据倾斜(DistributedCache)
1.Map端Join解决数据倾斜 1.Mapreduce中会将map输出的kv对,按照相同key分组(调用getPartition),然后分发给不同的reducetask 2.Map输出结果的时候 ...
- Spark性能调优之解决数据倾斜
Spark性能调优之解决数据倾斜 数据倾斜七种解决方案 shuffle的过程最容易引起数据倾斜 1.使用Hive ETL预处理数据 • 方案适用场景:如果导致数据倾斜的是Hive表.如果该Hiv ...
- MapReduce如何解决数据倾斜?
数据倾斜是日常大数据查询中隐形的一个BUG,遇不到它时你觉得数据倾斜也就是书本博客上的一个无病呻吟的偶然案例,但当你遇到它是你就会懊悔当初怎么不多了解一下这个赫赫有名的事故. https://www. ...
- 【Spark篇】---Spark解决数据倾斜问题
一.前述 数据倾斜问题是大数据中的头号问题,所以解决数据清洗尤为重要,本文只针对几个常见的应用场景做些分析 . 二.具体方法 1.使用Hive ETL预处理数据 方案适用场景: 如果导致数据倾斜的是 ...
- 专访周金可:我们更倾向于Greenplum来解决数据倾斜的问题
周金可,就职于听云,维护MySQL和GreenPlum的正常运行,以及调研适合听云业务场景的数据库技术方案. 听云周金可 9月24日,周金可将参加在北京举办的线下活动,并做主题为<GreenPl ...
- MapReduce分区数据倾斜
什么是数据倾斜? 数据不可避免的出现离群值,并导致数据倾斜,数据倾斜会显著的拖慢MR的执行速度 常见数据倾斜有以下几类 1.数据频率倾斜 某一个区域的数据量要远远大于其他区域 2.数据大小倾斜 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势
原创文章,同步首发自作者个人博客转载请务必在文章开头处注明出处. 摘要 本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitio ...
- 实战 | Hive 数据倾斜问题定位排查及解决
Hive 数据倾斜怎么发现,怎么定位,怎么解决 多数介绍数据倾斜的文章都是以大篇幅的理论为主,并没有给出具体的数据倾斜案例.当工作中遇到了倾斜问题,这些理论很难直接应用,导致我们面对倾斜时还是不知所措 ...
随机推荐
- ArrayList的实现原理
ArrayList的线性复杂度是1.想确定一个数据,直接通过索引进行访问.实际上这个过程和数组是非常相似的.ArrayList在整个使用过程中,如果想要高效操作,最好设置一个数组的大小.在个数固定的情 ...
- c/c++本地时间获取
在记录程序日志时,需要记录时间.如下: #include <iostream> #include <time.h> #include <windows.h> usi ...
- Zabbix系列之三——部署JMX监控tomcat
zabbix提供了一个java gateway的应用去监控jmx(Java Management Extensions,即Java管理扩展)是一个为应用程序.设备.系统等植入管理功能的框架.JMX可以 ...
- cmd窗口使用sftp命令非密钥和密钥登录SFTP服务器的两种方式
cmd窗口使用sftp命令非密钥和密钥登录SFTP服务器的两种方式 一.在Windows环境下搭建SFTP服务器可参见http://www.cnblogs.com/Kevin00/p/6341295. ...
- Visual Studio 2012 智能提示功能消失解决办法
安装为Visual Studio 2012且更新到了Update3,但是发现智能提示功能用不了,查了一下,网上各种资料,重装VS,连重装系统的都有.不过有很多朋友都是使用命令行重置VS的方法解决了这个 ...
- ClickHouse之简单性能测试
前面的文章ClickHouse之初步认识已经简单的介绍了ClickHouse,接下来进行简单的性能测试.测试数据来源于美国民用航班的数据,从1987年到2017年,有1.7亿条. 环境: centos ...
- 当Elasticsearch遇见Kafka
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由michelmu发表于云+社区专栏 Elasticsearch作为当前主流的全文检索引擎,除了强大的全文检索能力和高扩展性之外,对多种 ...
- JavaWeb学习 (十六)————JSP中的九个内置对象
一.JSP运行原理 每个JSP 页面在第一次被访问时,WEB容器都会把请求交给JSP引擎(即一个Java程序)去处理.JSP引擎先将JSP翻译成一个_jspServlet(实质上也是一个servlet ...
- 实现一个简单的vue-router
所有项目的源代码都放在我的github上,欢迎大家start: https://github.com/Jasonwang911/my-vue-router 首先来看下vue-router的使用: im ...
- openssl签署和自签署证书的多种实现方式
openssl系列文章:http://www.cnblogs.com/f-ck-need-u/p/7048359.html 1.采用自定义配置文件的实现方法 1.1 自建CA 自建CA的机制:1.生成 ...