剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充
原文链接:http://mechanitis.blogspot.com/2011/07/dissecting-disruptor-why-its-so-fast_22.html 需翻墙
计算机入门
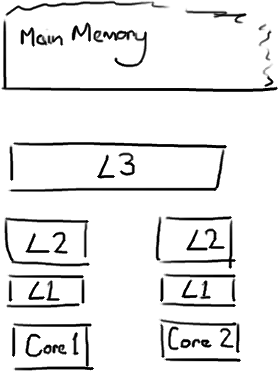
Martin 和 Mike 的 QCon presentation演讲中给出了一些缓存未命中的消耗数据:
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
| 主存 | 约60-80纳秒 | |
| QPI 总线传输 (between sockets, not drawn) |
约20ns | |
| L3 cache | 约40-45 cycles, | 约15ns |
| L2 cache | 约10 cycles, | 约3ns |
| L1 cache | 约3-4 cycles, | 约1ns |
| 寄存器 | 1 cycle |
缓存行
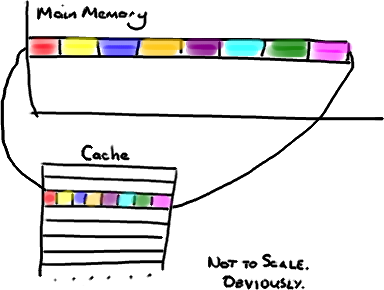
head;同时你的类中有另一个变量紧挨着它,暂时称它为tail。现在,当你加载head到缓存的时候,你也免费加载了tail。
head中保存的内容也正被消费者(译注:和生产者不在同一个内核中)消费。这两个变量并无直接联系,但需要被这两个线程使用,且这两个线程运行在不同的内核(译注:这里是指物理上的内核,即多核CPU)中。head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。而我们必须以整个缓存行作为单位来处理,不能只把head标记为无效。
head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。解决方案-神奇的缓存行填充
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
(译注:前后各七位填充字段,保证cursor[1]在缓冲行中任意位置,其周围都有足够的填充字段)
Entry类中也值得这样做,如果你有不同的消费者往不同的字段写入,你需要确保各个字段间不会出现伪共享。剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充的更多相关文章
- 从缓存行出发理解volatile变量、伪共享False sharing、disruptor
volatilekeyword 当变量被某个线程A改动值之后.其他线程比方B若读取此变量的话,立马能够看到原来线程A改动后的值 注:普通变量与volatile变量的差别是volatile的特殊规则保证 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - Guava Cache
文章目录 1. Guava Cache 集成 2. 个性化配置 3. 源代码 本文,讲解 Spring Boot 如何集成 Guava Cache,实现缓存. 在阅读「Spring Boot 揭秘与实 ...
- 二、Memcached缓存穿透、缓存雪崩
二.Memcached缓存穿透.缓存雪崩 1. 缓存雪崩 可能是数据魏加载到缓存中,或者缓存同一时间大面积失效,导致大量请求去数据库查询的过程,数据库过载,崩溃. 解决方法: 1 采用加锁计数,使用合 ...
- 使用本地缓存快还是使用redis缓存好?
使用本地缓存快还是使用redis缓存好? Redis早已家喻户晓,其性能自不必多说. 但是总有些时候,我们想把性能再提升一点,想着redis是个远程服务,性能也许不够,于是想用本地缓存试试!想法是不错 ...
- 一.rest-framework之版本控制 二、Django缓存 三、跨域问题 四、drf分页器 五、响应器 六、url控制器
一.rest-framework之版本控制 1.作用 用于版本的控制 2.内置的版本控制 from rest_framework.versioning import QueryParameterVer ...
- {MySQL的库、表的详细操作}一 库操作 二 表操作 三 行操作
MySQL的库.表的详细操作 MySQL数据库 本节目录 一 库操作 二 表操作 三 行操作 一 库操作 1.创建数据库 1.1 语法 CREATE DATABASE 数据库名 charset utf ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - Redis Cache
文章目录 1. Redis Cache 集成 2. 源代码 本文,讲解 Spring Boot 如何集成 Redis Cache,实现缓存. 在阅读「Spring Boot 揭秘与实战(二) 数据缓存 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - EhCache
文章目录 1. EhCache 集成 2. 源代码 本文,讲解 Spring Boot 如何集成 EhCache,实现缓存. 在阅读「Spring Boot 揭秘与实战(二) 数据缓存篇 - 快速入门 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - 快速入门
文章目录 1. 声明式缓存 2. Spring Boot默认集成CacheManager 3. 默认的 ConcurrenMapCacheManager 4. 实战演练5. 扩展阅读 4.1. Mav ...
随机推荐
- 【Flex学习】Flex4学习网站
http://blog.minidx.com/category/flex 来自为知笔记(Wiz)
- php正则替换所有空格和换行
替换所有空格为空 $contents=" abc "; $contents=preg_replace('/\s+/','',$contents); //结果$contents=&q ...
- (微信API接口开发) 使用HttpWebRequest进行请求时发生错误:基础连接已关闭,发送时发生错误处理
最近调试原来的微信模拟登陆时发生了“基础连接已关闭,发送时发生错误”的错误提示,原来都是好好的,只是很久没用了. 出错代码如下: HttpWebRequest req = (HttpWebReques ...
- js常用方法收集
JS获取地址栏制定参数值: //获取URL参数的值 function getUrlParam(name){ var reg = new RegExp("(^|&)"+ na ...
- MVC 模型
dbcontent var ALLALBUMS=from album in db.albums orderby album.title ascending select album; storeman ...
- Report_客制化以PLSQL输出XLS标记实现Excel报表(案例)
2015-02-12 Created By BaoXinjian
- [ Redis ] Redis 未授权访问漏洞被利用,服务器登陆不上
一.缘由: 突然有一天某台服务器远程登陆不上,试了好几个人的账号都行,顿时慌了,感觉服务器被黑.在终于找到一个还在登陆状态的同事后,经查看/ect/passwd 和/etc/passwd-异常,文件中 ...
- Python 向上取整的算法
一.初衷: 有时候我们分页展示数据的时候,需要计算页数.一般都是向上取整,例如counts=205 pageCouts=20 ,pages= 11 页. 一般的除法只是取整数部分,达不到要求. 二.方 ...
- Linux命令(17)du 查看文件和目录磁盘使用情况
Linux du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的. 1.命令格式: du [选项][文件] 2.命令功能 ...
- 保存恢复临时信-Android 中使用onSaveInstanceState和onRestoreInstanceState
在Activity中,有两个方法用于临时保存.恢复状态信息,这两个方法是: public void onSaveInstanceState(Bundle savedInstanceState); pu ...