Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分
Scrapy的爬取流程
Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示
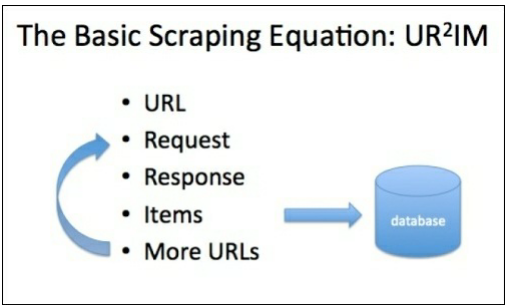
URL:Scrapy的运行就从那个你想要爬取的网站地址开始,当你想要验证用xpath或其他解析器来解析这个网页时,可以使用Scrapy shell工具来进行分析,譬如
$ scrapy shell http://web:9312/properties/property_000000.html
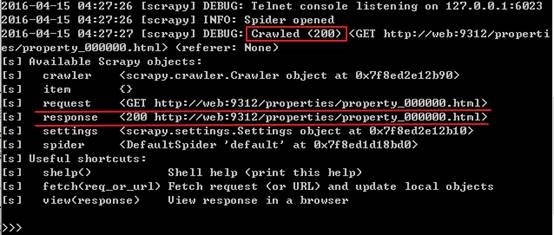
现在你就可以开始验证了
Request和Response:在上面使用Scrapy shell的过程中可以发现,只要我们输入了一个URL,它就可以自动发送一个GET请求并获取返回结果。request是一个把url封装好的对象,response则是一个把网页返回结果封装好的对象,response.body的值是网页的源代码,response.url是网页的url地址,还有更多相关的属性
Items:我们要爬取一个网页的时候并不是只把源代码下载下来就完事了,还需要提取网页中的相关信息,譬如网页的标题,网页的发布时间等等内容,而这些内容使用面向对象的技术,封装成一个Item对象,然后从网页中提取信息来填充这个Item
新建Scrapy工程
首先新建一个名为properties的Scrapy工程
$ scrapy startproject properties
$ cd properties
$ tree .
├── properties
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
2 directories, 6 files
注意,本系列文章的源代码都可以从github上下载
编写爬虫
定义item
编辑items.py文件,在该文件中定义的item并不是一定要在每一个spider中填充,也不是要全部同时使用的,你可以随意添加字段,并且在任何时候填充。
from scrapy.item import Item, Field class PropertiesItem(Item):
# Primary fields
title = Field()
price = Field()
description = Field()
address = Field()
image_urls = Field() # Calculated fields,这些字段需要运算后才得到,后面的文章会解析,暂时不用管
images = Field()
location = Field() # Housekeeping fields,这些字段用来在调试时显示相关信息
url = Field()
project = Field()
spider = Field()
server = Field()
date = Field()
定义spider
在项目的根目录下根据basic模板创建一个名为basic的spider,后面的web指的是spider的可运行的域名
scrapy genspider –t basic basic web
当然可以自己手写一个spider,但是从模板里创建可以省去不少的时间和减少出错机率,查看其他模板的命令:
scrapy genspider -l
由模板创建的basic.py文件的代码如下
# -*- coding: utf-8 -*-
import scrapy class BasicSpider(scrapy.Spider):
name = "basic"
allowed_domains = ["web"]
start_urls = (
'http://www.web/',
) def parse(self, response):
pass
把抓取到的网页存入item中(文件名:basic.py)
import scrapy
from properties.items import PropertiesItem
class BasicSpider(scrapy.Spider):
name = "basic"
allowed_domains = ["web"]
start_urls = (
'http://web:9312/properties/property_000000.html',
)
def parse(self, response):
item = PropertiesItem()
item['title'] = response.xpath(
'//*[@itemprop="name"][1]/text()').extract()
item['price'] = response.xpath(
'//*[@itemprop="price"][1]/text()').re('[.0-9]+')
item['description'] = response.xpath(
'//*[@itemprop="description"][1]/text()').extract()
item['address'] = response.xpath(
'//*[@itemtype="http://schema.org/'
'Place"][1]/text()').extract()
item['image_urls'] = response.xpath(
'//*[@itemprop="image"][1]/@src').extract()
return item
启动爬虫后,看到控制台输出如下信息,说明爬取成功
$scrapy crawl basic
DEBUG: Scraped from <200 http://...000.html>
{'address': [u'Angel, London'],
'description': [u'website ... offered'],
'image_urls': [u'../images/i01.jpg'],
'price': [u'334.39'],
'title': [u'set unique family well']}
将上面的输出保持到各种文件中:
scrapy crawl basic –o item.json
scrapy crawl basic –o item.jl
#json格式的文件会把整个json对象保存在一个巨大的数组里,意味着如果你要保存的数据量有1GB,那么在你解析这些数据之前,就必须用1GB的内存来保存整个文件。而jl格式会在每一行上放一个json对象,所以读取起来效率会更高 scrapy crawl basic –o item.xml
scrapy crawl basic –o item.csv
scrapy crawl basic –o ftp://user:pass@ftp.scrapybook.com/items.json 直接保存到ftp上
ItemLoader
对于上面混乱且难看的parse函数,可以使用Item Loader来处理,并且Item Loader提供更多的功能(http://doc.scrapy.org/en/latest/topics/loaders.html),最重要的是能够对通过xpath提取出来的信息进行处理,譬如去掉空格和替换字符等,然后将清洗后的数据再写入item中。对数据的清洗是通过processor来实现的,很常用的一个processor就是MapCompose()函数,该函数将python函数或者lambda表达式作为参数(参数个数无限制),然后按顺序执行这些函数来产生最终的结果。譬如MapCompose(unicode.strip, float)首先将xpath提取的信息去掉空格,再将其转换为float格式
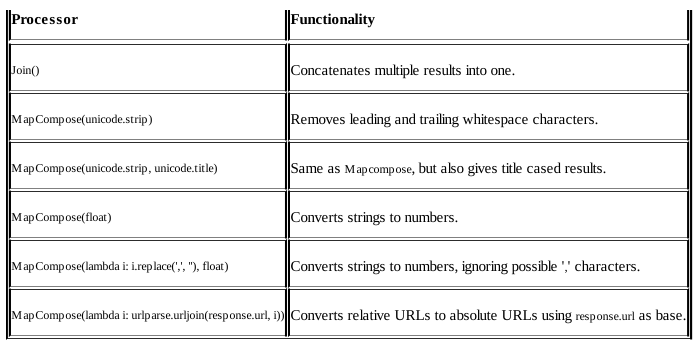
basic.py源代码文件:
修改上面的basic.py文件,使得代码更加简洁和一目了然
import datetime
import urlparse
import socket
import scrapy from scrapy.loader.processors import MapCompose, Join
from scrapy.loader import ItemLoader from properties.items import PropertiesItem class BasicSpider(scrapy.Spider):
name = "basic"
allowed_domains = ["web"] # Start on a property page
start_urls = (
'http://web:9312/properties/property_000000.html',
) def parse(self, response):
""" This function parses a property page. @url http://web:9312/properties/property_000000.html
@returns items 1
@scrapes title price description address image_urls
@scrapes url project spider server date
""" # Create the loader using the response
l = ItemLoader(item=PropertiesItem(), response=response) # Load fields using XPath expressions
l.add_xpath('title', '//*[@itemprop="name"][1]/text()',
MapCompose(unicode.strip, unicode.title))
l.add_xpath('price', './/*[@itemprop="price"][1]/text()',
MapCompose(lambda i: i.replace(',', ''), float),
re='[,.0-9]+')
l.add_xpath('description', '//*[@itemprop="description"][1]/text()',
MapCompose(unicode.strip), Join())
l.add_xpath('address',
'//*[@itemtype="http://schema.org/Place"][1]/text()',
MapCompose(unicode.strip))
l.add_xpath('image_urls', '//*[@itemprop="image"][1]/@src',
MapCompose(lambda i: urlparse.urljoin(response.url, i))) # Housekeeping fields 可以通过add_value函数直接向item填充数据
l.add_value('url', response.url)
l.add_value('project', self.settings.get('BOT_NAME'))
l.add_value('spider', self.name)
l.add_value('server', socket.gethostname())
l.add_value('date', datetime.datetime.now()) return l.load_item()
注意在上面的parse函数中有这样的一段注释
""" This function parses a property page.
@url http://web:9312/properties/property_000000.html
@returns items 1
@scrapes title price description address image_urls
@scrapes url project spider server date
"""
这些以@开头的称为contract,类似于单元测试,假如你在一个月前写了这个spider,现在想测试这个spider是否仍然正确运行,就可以使用这些contract。上面的这些contract的意思是:检查该url,你应该得到一个包含了下面列出来的字段的item
运行scrapy check来检查contract
$ scrapy check basic
----------------------------------------------------------------
Ran 3 contracts in 1.640s
OK
如果spider的代码出错了,或者xpath表达式已经过期了(网站发生了更新),那么就会得到测试失败的结果,虽然出错信息并不详尽,但这是最快的检查手段
Spider的运行原理
在上面用模板定义的spider十一个用来爬取特定网页的类,包括了如何执行爬取动作(譬如如何跟踪超链接)和如何从页面中提取信息。换句话说,spider就是你用来定义对某个特定网站的爬取动作的工具,他的爬取循环类似于这样:
1、 首先要将你指定的初始URL封装成Request对象,并且要指定在网页返回该请求的内容后应该用哪个函数来处理网页的内容。
默认情况下,会调用start_requests()函数,对start_urls中的URL分别生成一个Request对象,并且指定parse()函数作为回调函数(回调函数指的是callback变量指定的函数)
2、 在回调函数中,可以处理response变量,然后返回一个已经提取好数据的字典或者是一个Item对象,或者是Request对象(在这个Request对象中,也可以指定一个回调函数,同样地,处理完这个Request之后生成的response就会传送到回调函数中处理)
3、 在回调函数中,也可以提取网页内容,通常使用Selector(也可以使用BeautifulSoup,lxml或者其他你熟悉的机制)来生成包含了解析数据的item
4、 最后,这些从spider中返回的item通常会存入到数据库中,或者写入到文件中
即使上述流程适用于大部分的spider,但是仍然有不同的spider运行不同的默认流程,更多的信息就查阅这里:
Learning Scrapy笔记(三)- Scrapy基础的更多相关文章
- 学习笔记三:基础篇Linux基础
Linux基础 直接选择排序>快速排序>基数排序>归并排序 >堆排序>Shell排序>冒泡排序=冒泡排序2 =直接插入排序 一.Linux磁盘分区表示 Linux中 ...
- Java基础学习笔记三 Java基础语法
Scanner类 Scanner类属于引用数据类型,先了解下引用数据类型. 引用数据类型的使用 与定义基本数据类型变量不同,引用数据类型的变量定义及赋值有一个相对固定的步骤或格式. 数据类型 变量名 ...
- deep learning 学习笔记(三) 线性回归学习速率优化寻找
继续学习http://www.cnblogs.com/tornadomeet/archive/2013/03/15/2962116.html,上一节课学习速率是固定的,而这里我们的目的是找到一个比较好 ...
- Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面
摘要:介绍了使用Scrapy处理JSON API和AJAX页面的方法 有时候,你会发现你要爬取的页面并不存在HTML源码,譬如,在浏览器打开http://localhost:9312/static/, ...
- Learning Scrapy笔记(零) - 前言
我已经使用了scrapy有半年之多,但是却一直都感觉没有入门,网上关于scrapy的文章简直少得可怜,而官网上的文档(http://doc.scrapy.org/en/1.0/index.html)对 ...
- scrapy爬虫笔记(三)------写入源文件的爬取
开始爬取网页:(2)写入源文件的爬取 为了使代码易于修改,更清晰高效的爬取网页,我们将代码写入源文件进行爬取. 主要分为以下几个步骤: 一.使用scrapy创建爬虫框架: 二.修改并编写源代码,确定我 ...
- scrapy学习笔记(三):使用item与pipeline保存数据
scrapy下使用item才是正经方法.在item中定义需要保存的内容,然后在pipeline处理item,爬虫流程就成了这样: 抓取 --> 按item规则收集需要数据 -->使用pip ...
- 爬虫(九)scrapy框架简介和基础应用
概要 scrapy框架介绍 环境安装 基础使用 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能 ...
- 10.scrapy框架简介和基础应用
今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被 ...
随机推荐
- 翻译:Angular 2 - TypeScript 5 分钟快速入门
原文地址:https://angular.io/docs/ts/latest/quickstart.html Angular 2 终于发布了 beta 版.这意味着正式版应该很快就要发布了. 让我们使 ...
- DFS
HDU1181 http://acm.hdu.edu.cn/showproblem.php?pid=1181 #include<stdio.h> #include<algorith ...
- C#中的委托,匿名方法和Lambda表达式
简介 在.NET中,委托,匿名方法和Lambda表达式很容易发生混淆.我想下面的代码能证实这点.下面哪一个First会被编译?哪一个会返回我们需要的结果?即Customer.ID=.答案是6个Firs ...
- linux 关闭系统提示声音
关闭Linux 提示声音: rmmod pcspkr //永久关闭 在/etc/modprobe.d/blacklist文件最后加上 blacklist pcspkr
- ASP.NET运行机制原理 ---浏览器与IIS的交互过程 自己学习 网上查了下别人写的总结的很好 就转过来了 和自己写的还好里嘻嘻
一.浏览器和服务器的交互原理 (一).浏览器和服务器交互的简单描述: 1.通俗描述:我们平时通过浏览器来访问网站,其实就相当于你通过浏览器去访问一台电脑上访问文件一样,只不过浏览器的访问请求是由被访问 ...
- ZoneMinder配置与使用
ZoneMinder是一套基于Linux操作系统的摄像机的视像数据监控的应用软件.应用范围广泛,包括商业或家居防盗等.ZoneMinder支持单一或多台视像镜头应用,包括摄取.分析.记录.和监视来源, ...
- 按照 where id in ()排序
select * from ibs6_terminal_adv_inf where id in (16,14,15) order by find_in_set(id,'16,14,15')
- 苹果系列机型专业刷机,解锁,解ID
如有软件开发需求,请留言或在猪八戒网主页留言http://home.zhubajie.com/8506525/,常年接收c.c++(vs2010.RAD studio xe5\RAD studio 2 ...
- shell脚本中的特殊符号
1.{} 大括号:用法一:通配符扩展eg: ls my_{finger,toe}s这条命令相当于如下命令的组合:ls my_fingers my_toeseg: mkdir {userA,userB, ...
- Windows Phone 资源管理与换肤思考
新入手一台Windows 8的笔记本,安装了VS2013后,终于又可以开发WP了.公司暂时不愿意开发WP,那么咱就自行研究吧! 在没有WP开发环境的时候,曾经在WPF尝试了一下换肤功能的实现.最简单的 ...