输入格式--InputFormat和InputSplit
1)InputFormat的类图:
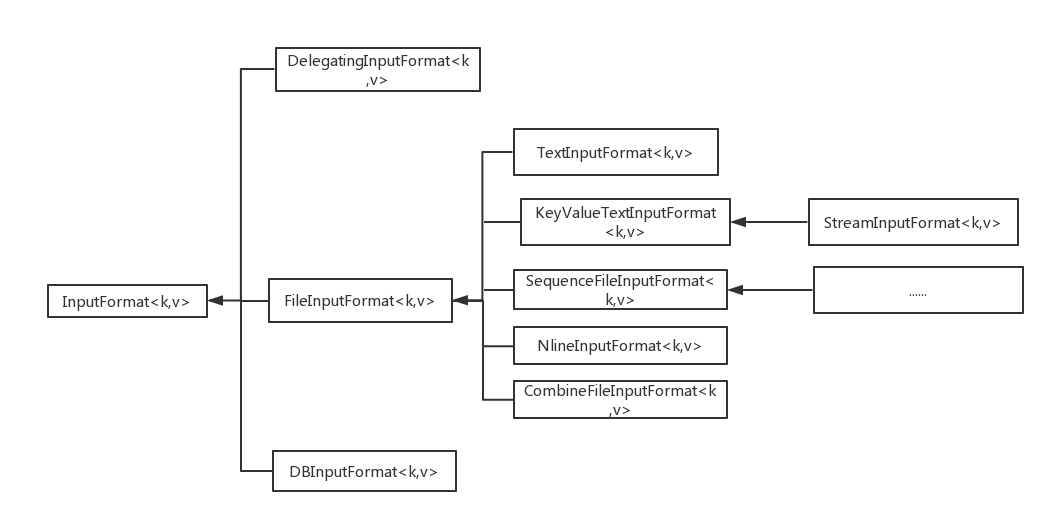
InputFormat 直接子类有三个:DBInputFormat、DelegatingInputFormat和FileInputFormat,分别表示输入文件的来源为从数据库、用于多个输入以及基于文件的输入。对于FileInputFormat,即从文件输入的输入方式,又有五个继承子类:CombineFileInputFormat,KeyValueTextInput,NLineInoutFormat,SequenceFileInputFormat,TextInputFormat。
2)InputSplit的类图
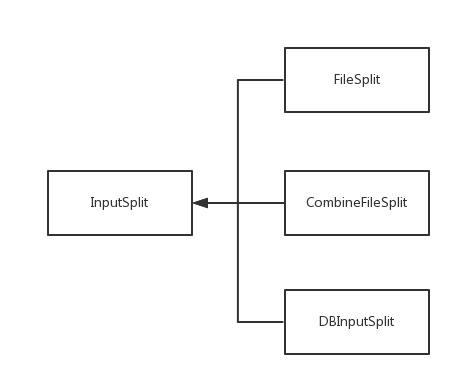
输入分片InputSplit 类有三个子类继承:FileSplit (文件输入分片),CombineFileSplit(多文件输入分片)以及DBInputSplit(数据块输入分片)。
3)InputFormat:
InputFormat有三个作用:
a.验证作业数据的输入形式和格式(要与MR程序中使用的格式相同,比如是TextInputFormat还是DBInputFormat)
b.将输入的数据切分为多个逻辑上的InputSplit,其中每一个InputSplit作为一个MApper的输入。
c.提供一个RecordReader,用于将InputSplit的内容转换为可以作为map输入的<k,v>键值对。
使用代码来指定MR作业数据的输入格式:
job.setInputFormatClass(TextInputFormat.class)
其实,InputFormat是一个抽象类,只是提供了两个抽象方法:
abstract List<InputSplit>getSplits(JobContext context);
abstract RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context)
只提供两个抽象方法是有原因的,首先不同的格式的文件切片的方法不同(对应于getSplits),同一份文件可能希望读出不同形式的内容(对应createRecordReader)。
getSplits:
InputFormat的直接派生类需要实现此方法,例如FileInputFormat和DBInputFormat。另外,InputSplit的类型在选择了InputFormat的类型就已经确定了的,因为每个InputFormat的派生类都实现了getSplits,在此方法内部已经生成了对应的InputSplit。
createRecordReader:
FileInputFormat的派生类都实现了这个方法。
4)
InputSplit:
任何数据分块儿的实现都继承自抽象基类InputSplit,它位于org.apache.hadoop.mapreduce.InputSplit。此抽象类中有两个抽象方法:
abstract long getLength()
abstract String[] getLocation()
getLength()返回该块儿的大小,单位是字节。getLocation()返回存储该数据块的数据节点的名称,例如:String[0]="Slave1",String[1]="Slave2".
这两个方法也是需要在InputSplit的派生类中实现的。
5)
InputSplit的大小:
一个数据分片的大小由以下三行代码确定:
goalSize=totalSize/(numSplits==0?1:numSplits)
//totalSize是输入数据文件的大小,numSplits是用户设置的map数量,就是按照用户自己
//的意愿,每个分片的大小应该是goalSize
minSize=Math.max(job.getLong("mapred.min.split.size",1),minSplitSize)
//hadoop1.2.1中mapred-default.xml文件中mapred.min.split.size=0,所以job.getLong("mapred.min.split.size",1)=0,而minSplitSize是InputSplit中的一个数据成员,在File//Split中值为1.所以minSize=1,其目的就是得到配置中的最小值。
splitSize=Math.max(minSize,Math.min(goalSize,blockSize))
//真正的分片大小就是取按照用户设置的map数量计算出的goalSize和块大小blockSize中最小值(这是为了是分片不会大于一个块大小,有利于本地化计算),并且又比minSize大的值。
输入格式--InputFormat和InputSplit的更多相关文章
- hadoop输入格式(InputFormat)
InputFormat接口(package org.apache.hadoop.mapreduce包中)里包括两个方法:getSplits()和createRecordReader(),这两个方法分别 ...
- mapreduce的输入格式 --- InputFormat
InputFormat 接口决定了mapreduce如何切分输入文件. InputFormat 由getspilit和createRecordReader组成,getspilit主要是标记分片的初始位 ...
- MapReduce输入格式
文件是 MapReduce 任务数据的初始存储地.正常情况下,输入文件一般是存储在 HDFS 里面.这些文件的格式可以是任意的:我们可以使用基于行的日志文件, 也可以使用二进制格式,多行输入记录或者其 ...
- InputFormat,OutputFormat,InputSplit,RecordRead(一些常见面试题),使用yum安装64位Mysql
列举出hadoop常用的一些InputFormat InputFormat是用来对我们的输入数据进行格式化的.TextInputFormat是默认的. InputFormat有哪些类型? DBInpu ...
- hadoopMR自定义输入格式
输入格式 1.输入分片与记录 2.文件输入 3.文本输入 4.二进制输入 5.多文件输入 6.数据库格式输入 详细的介绍:https://blog.csdn.net/py_123456/ar ...
- MapReduce实战:自定义输入格式实现成绩管理
1. 项目需求 我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩. 样本数据如下所示,每行数据的数据格式为:学号.姓名.语文成绩.数学成绩.英语成绩.物理成绩.化 ...
- MapReduce的输入格式
1. InputFormat接口 InputFormat接口包含了两个抽象方法:getSplits()和creatRecordReader().InputFormat决定了Hadoop如何对文件进行分 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
随机推荐
- .Net 自己写个简单的 半 ORM (练手)
ORM 大家都知道, .Net 是EF 还有一些其他的ORM 从JAVA 中移植过来的 有 , 大神自己写的也有 不管ORM 提供什么附加的 乱七八糟的功能 但是 最主要的 还是 关系映射 的事情 ...
- 史上最简单的个人移动APP开发入门--jQuery Mobile版跨平台APP开发
书是人类进步的阶梯. ——高尔基 习大大要求新新人类要有中国梦,鼓励大学生们一毕业就创业.那最好的创业途径是什么呢?就是APP.<构建跨平台APP-jQuery Mobile移动应用实战> ...
- [terry笔记]RMAN综合学习之备份
rman是最经济实惠的oracle备份工具,在这里做一个rman的整体学习. 文章中大多是rman命令的语法,还是最好做做实验,以便印象深刻,因为大多数数据库的备份就是按时跑脚本,恢复也不是经常能遇到 ...
- python 数据类型(sequence 序列、dictionary 词典、动态类型)
文章内容摘自:http://www.cnblogs.com/vamei 1.sequence 序列 sequence(序列)是一组有顺序的元素的集合 (严格的说,是对象的集合,但鉴于我们还没有引入“对 ...
- 【C#】 装箱 (boxing) 和拆箱 (unboxing)
目录: 1. 装箱和拆箱 2. 深入理解装箱和拆箱 3. int[] to object[],值类型数组到对象数组的转化 4. 使用泛型减少装箱和拆箱 1. 装箱和拆箱 装箱 就是把“值类型”转换成 ...
- 对Iframe和图表设置高度的优质代码
//对Iframe和图表设置高度 function f() { parent.window.setWinHeight(parent.window.document.getElementById(&qu ...
- jdbc 连接 oracle rac
jdbc 连接 oracle rac 的连接串如下: jdbc:oracle:thin:@(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = 192. ...
- c++编程规范的纲要和记录
这是一本好书, 可以让你认清自己对C++的掌握程度.看完之后,给自己打分,我对C++了解多少? 答案是不足20分.对于我自己是理所当然的问题, 就不提了, 记一些有启发的条目和细节: (*号表示不能完 ...
- Stream,Reader/Writer,Buffered的区别(1)
Stream: 是字节流形式,exe文件,图片,视频等.支持8位的字符,用于 ASCII 字符和二进制数据. Reader/Writer: 是字符流,文本文件,XML,txt等,用于16位字符,也就是 ...
- hdu 5166 Missing number
题目连接 http://acm.hdu.edu.cn/showproblem.php?pid=5166 Missing number Description There is a permutatio ...