unordered_map(hash_map)和map的比较
测试代码:
#include <iostream>
using namespace std;
#include <string>
#include <windows.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <map>
const int maxval = 2000000 * 5;
#include <unordered_map>
void map_test()
{
printf("map_test\n");
map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval]++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand()%maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
void hash_map_test()
{
printf("hash_map_test\n");
unordered_map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval] ++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand() % maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
int main(int argc, char *argv[])
{
srand(0);
map_test();
Sleep(1000);
srand(0);
hash_map_test();
system("pause");
return 0;
}
详解:
map(使用红黑树)与unordered_map(hash_map)比较
map理论插入、查询时间复杂度O(logn)
unordered_map理论插入、查询时间复杂度O(1)
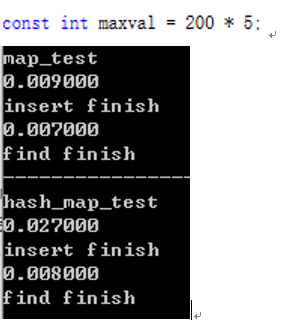
数据量较小时,可能是由于unordered_map(hash_map)初始大小较小,大小频繁到达阈值,多次重建导致插入所用时间稍大。(类似vector的重建过程)。
哈希函数也是有消耗的(应该是常数时间),这时候用于哈希的消耗大于对红黑树查找的消耗(O(logn)),所以unordered_map的查找时间会多余对map的查找时间。
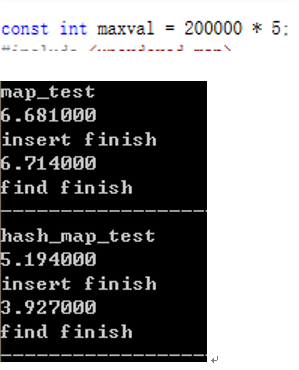
数据量较大时,重建次数减少,用于重建的开销小,unordered_map O(1)的优势开始显现
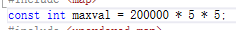
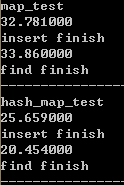
数据量更大,优势更明显
使用空间:


前半部分为map,后半部分为unordered_map
unordered_map占用的空间比map略多,但可以接受。
map和unordered_map内部实现应该都是采用达到阈值翻倍开辟空间的机制(16、32、64、128、256、512、1024……)浪费一定的空间是不可避免的。并且在开双倍空间时,若不能从当前开辟,会在其他位置开辟,开好后将数据移过去。数据的频繁移动也会消耗一定的时间,在数据量较小时尤为明显。
一种方法是手写定长开散列。这样做在数据量较小时有很好地效果(避免了数据频繁移动,真正趋近O(1))。但由于是定长的,在数据量较大时,数据重叠严重,散列效果急剧下降,时间复杂度趋近O(n)。
一种折中的方法是自己手写unordered_map(hash_map),将初始大小赋为一个较大的值。扩张可以模仿STL的双倍扩张,也可以自己采用其他方法。这样写出来的是最优的,但是实现起来极为麻烦。
综合利弊,我们组采用unordered_map。
附:使用Dev测试与VS2017测试效果相差极大???
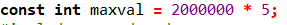
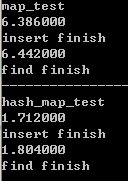
效率差了10倍???
原因:
Dev

VS2017

在Debug下,要记录断点等调试信息,的确慢。
Release:不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的。
VS2017切到release后,还更快

除了前面说的Debug与release导致效率差异外,编译器的不同也会导致效率差异。
学到了。
unordered_map(hash_map)和map的比较的更多相关文章
- hash_map和map的区别
hash_map和map的区别 分类: STL2008-10-15 21:24 5444人阅读 评论(0) 收藏 举报 class数据结构编译器存储平台tree 这里列几个常见问题,应该对你理解和使用 ...
- C++中的hash_map和map的区别
hash_map和map的区别在哪里?构造函数.hash_map需要hash函数,等于函数:map只需要比较函数(小于函数). 存储结构.hash_map采用hash表存储,map一般采用红黑树(RB ...
- boost::unordered_map 和 std::map 的效率 与 内存比较
例子链接:http://blog.csdn.net/gamecreating/article/details/7698719 结论: unordered_map 查找效率快五倍,插入更快,节省一定内存 ...
- std::unordered_map与std::map
前者查找更快.后者自动排序,并可指定排序方式. 资料参考: https://blog.csdn.net/photon222/article/details/102947597
- 福大软工1816 · 第五次作业 - 结对作业2_map与unordered map的比较测试
测试代码: #include <iostream> using namespace std; #include <string> #include <windows.h& ...
- STL中的map、unordered_map、hash_map
转自https://blog.csdn.net/liumou111/article/details/49252645 在之前使用STL时,经常混淆的几个数据结构,特别是做Leetcode的题目时,对于 ...
- map、hash_map、unordered_map 的思考
#include <map> map<string,int> dict; map是基于红黑树实现的,可以快速查找一个元素是否存在,是关系型容器,能够表达两个数据之间的映射关系. ...
- map vs hash_map
1. map, multimap, set, multiset g++ 中 map, multimap, set, multiset 由红黑树实现 map: bits/stl_map.h multim ...
- c++ map unordered_map
map operator<的重载一定要定义成const.因为map内部实现时调用operator<的函数好像是const. #include<string> #include& ...
随机推荐
- php 算法(二分法)只适用于有序表,且限于顺序存储结构
function demo($array,$low,$high,$k){ if($low<=$high){//判断该数组是否存在 $mid = intval(($low+$high)/2 ); ...
- R语言进行词云统计分析
R语言进行词云统计分析 本文章从爬虫.词频统计.可视化三个方面讲述了R语言的具体应用,欢迎大家共同谈论学习 1.使用 rvest 进行数据的爬取 #如果没有,先安装rvest包 install.pac ...
- 用Turtle库画一个爱心
---恢复内容开始--- 用Python中的turtle库画一个爱心 这个学期,我学了Python语言,并学到其中的一个库:turtle库.用turtle库可以画一些你想画的图片,所以我就想画一个爱心 ...
- linux进程篇 (三) 进程间的通信2 信号通信
2. 信号通信 用户空间 进程A <----无法通信----> 进程B -----------------|--------------------------------------|- ...
- fedora/centos下gcc编译出现gcc: error trying to exec ‘cc1plus’: execvp: No such file or directory
fedora/centos下gcc编译出现gcc: error trying to exec 'cc1plus': execvp: No such file or directory解决办法 翻译自: ...
- 成都Uber优步司机奖励政策(3月24日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 【机器学习笔记】EM算法及其应用
极大似然估计 考虑一个高斯分布\(p(\mathbf{x}\mid{\theta})\),其中\(\theta=(\mu,\Sigma)\).样本集\(X=\{x_1,...,x_N\}\)中每个样本 ...
- Chrome模拟平板调试
1. 按F12,打开开发者工具,右上角,点击红圈中的标志.然后在弹出的面板中点击'Emulation'. 2. 会看到左侧的四个选项卡 Device 设备.Screen 屏幕.User Agent ...
- php 用continue加数字实现foreach 嵌套循环中止
foreach($array as $key => $value) { if($value == 5)break; } // 这是一种. // 如果是嵌套的循环,用continue加数字也可以实 ...
- Sql Server Profiler使用
在使用Entity Framework的过程当中,有时候需要看Entity Framework自动生成的Sql语句,在客户端可以使用跟踪的方法看到每次查询时的Sql语句,其实通过数据库 ...