基于redis的简易分布式爬虫框架
开发环境
- Python 3.6
- Requests
- Redis 3.2.100
- Pycharm(非必需,但可能出现bug)
运行环境
Win 10 + Redis 3.2.100(已测试)
Mac + Redis 3.2.11(已测试)
redis配置问题,请自行百度或者谷歌。
实现功能
分布式爬虫,可并发
需求分析
作为一个分布式爬虫框架,方便的部署到多个环境上,快速的获取数据,简易的使用,
在运行中忽略某些错误,以及在遇到某些情况时停止抓取,管理者强制停止爬虫时可以
将正在进行的线程进行完等,个人理解中大体需求如此。
程序实现
- 目前程序算是基础版本(0.1?赫赫),实现了如下功能:
- 分布式: 只需要一台redis服务器,其余爬虫链接到服务器获取url进行数据采集即可。
- 部署方便: 文件夹copy一下就行,python本身就可以跨平台进行运转。
- 快速获取数据: 下载使用的是requests库,快慢完全凭借自己,调整settings.py中的delay以及max_threads就行。
- 使用简单: 继承一下爬虫类,写个解析函数,跟scrapy类似,简化版。
- 错误处理: 目前除了ctrl+C和关闭窗口以外,只有level_time到了才能停止程序。
- 停止处理: ctrl+c后会完成线程后再停止。
- 统计: 目前只统计进行了多少次抓取,没有计算成功与失败次数。
- 日志: 部分情况会纪录日志,不过比较少,不过可以自己定制。
- 代理: 代理和headers可设置。
- 代码结构:
- __init__.py 初始化文件,实例化日志
- download.py 下载器类
- scheduler.py 调度器类(虽然功能不全)
- settings.py 默认设置
- spider.py 爬虫类
- logs.log 日志文件
- example.py 示例
- README.md 说明
- 截图
- 部分源码展示:
# download.py
class DOWNLOAD:
def __init__(self, proxy=None, delay=DELAY, num_retries=NUM_RETRIES,
timeout=TIMEOUT, headers=HEADERS, **kwargs):
"""
初始化
:param proxy: 下载时使用的代理
:param delay: 下载延迟
:param timeout: 下载超时时间
:param headers: 下载时使用的文件头
:param num_retries: 下载重试次数
:param kwargs: 其他
"""
self.proxy = proxy
self.timeout = timeout
self.headers = headers or {'User-agent': 'OSpider'}
self.logging = logger
self.throttle = Throttle(delay)
self.num_retries = num_retries
self.kwargs = kwargs
def __call__(self, url, method='GET', data=None, cookies=None, **kwargs):
"""
这个魔法函数可以让类的实例像函数一样被调用,例如:
D = DOWNLOAD(...)
result = D(url)
:param url: url
:param method: 请求的方法
:param data: 请求的内容
:param cookies: 请求时使用的cookies
:param kwargs: 其他,比如代理
:return: {'html': 网页内容, 'status': 状态码, 'url': 请求地址}
"""
# 设置同个域下的限速
self.throttle.wait(url)
# 让类的实例返回download函数的返回值
return self.download(url, method, data, cookies)
def download(self, url, method='GET', data=None, cookies=None):
"""
具体下载用函数
:param url: 请求地址
:param method: 请求方法
:param data: 请求附带的内容
:return: {'html': 网页内容, 'status': 状态码, 'url': 请求地址}
"""
methods = ["GET", "POST", "PUT", "DELETE"]
session = requests.Session()
# 设置头信息
session.headers = self.headers
# 设置代理
if self.proxy:
if isinstance(self.proxy, dict):
if self.proxy.get('http') or self.proxy.get('https'):
session.proxies = self.proxy
self.logging.info('设置代理:{}'.format(self.proxy))
else:
self.logging.error('代理格式错误,需要使用字典格式')
# 检查请求方法
if method not in methods:
raise ValueError("请求方法错误, 请在{}中选择!".format(methods))
# 设置cookies
if cookies:
session.cookies = cookies
# 获取内容并返回
try:
res = session.request(method, url, data=data)
html = res.text
status = res.status_code
# 出现问题打印到日志,然后重试num_retries次
except Exception as e:
html = ''
if hasattr(e, 'code'):
code = e.code
if self.num_retries > 0 and 500 <= code < 600:
self.num_retries -= 1
return self.download(url, method, data, cookies)
else:
code = None
self.logging.error(e)
html = None
status = None
return {'html': html, 'status': status, 'url': url}
# Scheduler.py
"""
SCHEDULER(调度器) 目前只有抓取然后返回结果的功能.....
"""
# 初始化就略过了,选了两个较重要的放了上来
# 使用threading达成了并发抓取,因为是密集型IO所以影响不大。
def run(self):
"""开始进行抓取"""
threads = []
wait = 0
try:
while True:
num = self.show_num()
if num is None or num == 0:
print('抓捕队列为空!{}秒后继续抓取'.format(self.wait_time))
time.sleep(self.wait_time)
wait += self.wait_time
if wait >= self.leave_time:
print('{}秒内获取不到url,程序终端'.format(self.leave_time))
break
continue
for thread in threads:
if not thread.is_alive():
# 移除停止活动的线程
threads.remove(thread)
# 如果活动的线程数没有到达最大线程就继续创建线程
while len(threads) < self.max_threads:
thread = threading.Thread(target=self.crawl)
thread.setDaemon(True)
thread.start()
threads.append(thread)
time.sleep(3)
# 按了CTRL+c之后....
except KeyboardInterrupt:
self.leave_time = 0
# 等待线程结束然后移除还在活动的线程
for thread in threads:
thread.join()
if thread.is_alive():
threads.remove(thread)
print('程序停止!')
print('花费时间{}'.format(datetime.now() - self.start_time))
print('采集了{}个url'.format(self.start_num - self.show_num()))
def crawl(self):
"""抓取流程控制函数"""
while True:
# 设置一个可以在外部控制循环结束的条件
if self.leave_time == 0:
break
url = self.get_url()
if url is None:
break
res = self.D(url, **self.kwargs)
if self.callback:
self.callback(response=res)
else:
pprint('没有解析函数,直接打印结果:')
pprint(res)
程序使用方法以及截图
首先需要一台已经开启redis服务的主机。
然后进入settings进行配置
之后如下:
# 例子
# example.py
import json
import redis
from OSpider import OSPIDER, logger
# 继承爬虫类
class T(OSPIDER):
# 创建一个存储用的redis链接
r = redis.StrictRedis()
# 爬虫类中也有一个解析函数,这个函数有一个要求,有个参数必须名为response
def parse(self, response):
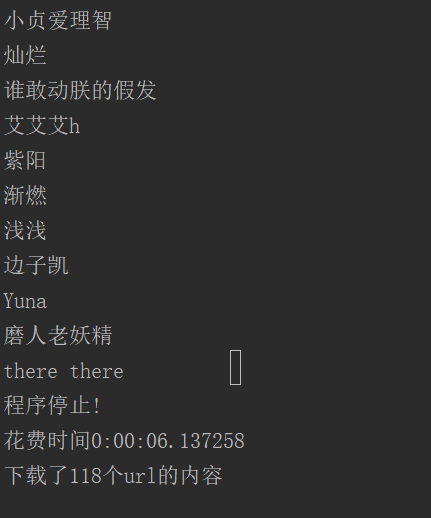
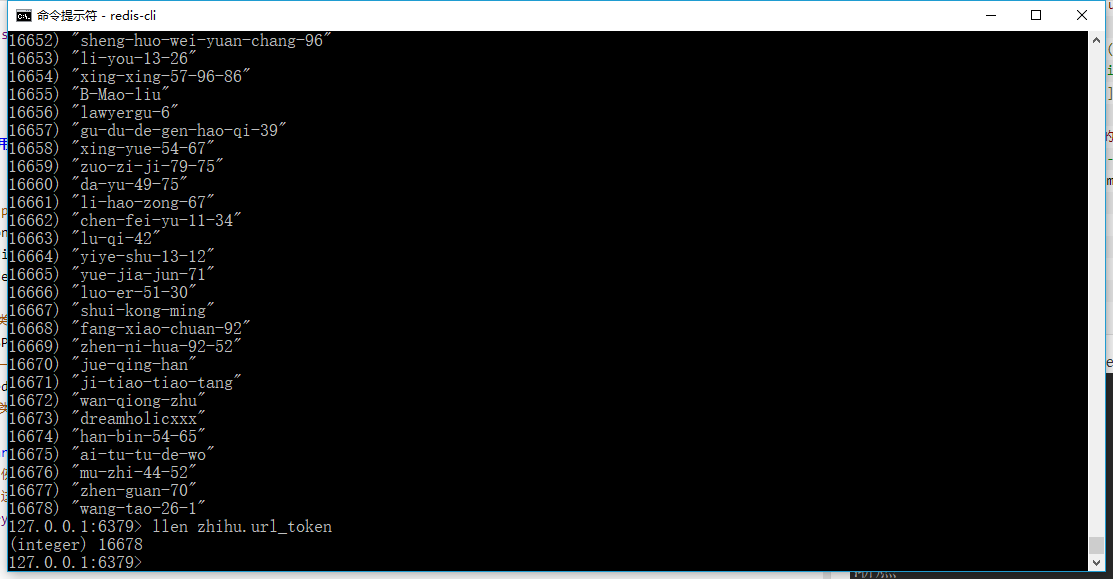
# 例子中采集的url是知乎的api,返回一个json数据,所以比较简单。
# 这里也就是获取了一下url_token,其实是无意义行为,举例用。
try:
res = json.loads(response['html'])
self.r.lpush('zhihu.url_token', res['url_token'])
print(res['name'])
except Exception:
# 导入的logger用的是自带的logging模块,日志同时会打印到屏幕以及日志文件中去。
logger.info("{}--出现错误,状态码--{}"
.format(response['url'], response['status']))
if __name__ == '__main__':
# 运行....
t = T()
t.run()
例子只是打印了用户名以及存储了url_token
其它
如果出现 ModuleNotFoundError: No module named 'OSpider'
在前几行加入
try:
import OSpider
except:
import sys
import os
sys.path.append(os.path.abspath('..'))
个人试做,如有BUG,请反馈。
基于redis的简易分布式爬虫框架
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
基于redis的简易分布式爬虫框架的更多相关文章
- 分布式爬虫框架XXL-CRAWLER
<分布式爬虫框架XXL-CRAWLER> 一.简介 1.1 概述 XXL-CRAWLER 是一个分布式爬虫框架.一行代码开发一个分布式爬虫,拥有"多线程.异步.IP动态代理.分布 ...
- 基于scrapy-redis组件的分布式爬虫
scrapy-redis组件安装 分布式实现流程 scrapy-redis组件安装 - 下载scrapy-redis组件:pip install scrapy-redis - 更改redis配置文件: ...
- 基于redis实现的分布式锁
基于redis实现的分布式锁 我们知道,在多线程环境中,锁是实现共享资源互斥访问的重要机制,以保证任何时刻只有一个线程在访问共享资源.锁的基本原理是:用一个状态值表示锁,对锁的占用和释放通过状态值来标 ...
- Cola:一个分布式爬虫框架 - 系统架构 - Python4cn(news, jobs)
Cola:一个分布式爬虫框架 - 系统架构 - Python4cn(news, jobs) Cola:一个分布式爬虫框架 发布时间:2013-06-17 14:58:27, 关注:+2034, 赞美: ...
- Swift:一个基于.NET Core的分布式批处理框架
Swift是什么 从文章的标题可知:此Swift非Apple那个Swift,只是考虑这个词的含义比较适合. Swift是一个基于.NET Core的分布式批处理框架,支持将作业分割后分发到多台服务器并 ...
- Scrapy框架之基于RedisSpider实现的分布式爬虫
需求:爬取的是基于文字的网易新闻数据(国内.国际.军事.航空). 基于Scrapy框架代码实现数据爬取后,再将当前项目修改为基于RedisSpider的分布式爬虫形式. 一.基于Scrapy框架数据爬 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 基于Redis的简单分布式锁的原理
参考资料:https://redis.io/commands/setnx 加锁是为了解决多线程的资源共享问题.Java中,单机环境的锁可以用synchronized和Lock,其他语言也都应该有自己的 ...
- Python 用Redis简单实现分布式爬虫
Redis通常被认为是一种持久化的存储器关键字-值型存储,可以用于几台机子之间的数据共享平台. 连接数据库 注意:假设现有几台在同一局域网内的机器分别为Master和几个Slaver Master连接 ...
随机推荐
- JavaScript中的Date类型
ECMAScript中的Date类型是在早起Java中的java.util.Date类基础上构建的.为此,Date类型使用自UTC(Coordinated Universal Time,国际协调时间) ...
- Nginx配置自签名的SSL证书(转载)
要保证Web浏览器到服务器的安全连接,HTTPS几乎是唯一选择.HTTPS其实就是HTTP over SSL,也就是让HTTP连接建立在SSL安全连接之上. SSL使用证书来创建安全连接.有两种验证模 ...
- 判断UISrollview的滑动方向
很常用的一个功能,就记录下来了. -(void)scrollViewWillBeginDragging:(UIScrollView *)scrollView { historyY = scrollVi ...
- material design动画
这是一篇material design 文档动画部分的学习! Summary: Material Design动画交互 动画速度的3个原则 3种交互方式 如何设计有意义的动画 使人高兴的动画细节 1 ...
- JIRA Service Desk 3.9.2 没有许可证
https://my.atlassian.com/license/evaluation Server ID BFHT-0XFL-3NM8-3KRF SEN SEN-L10880225 License ...
- 解决kylin报错:Failed to create dictionary on <db>.<table>, Caused by: java.lang.IllegalArgumentException: Too high cardinality is not suitable for dictionary
报错信息: 2017-05-13 15:14:30,035 DEBUG [pool-9-thread-10] dict.DictionaryGenerator:94 : Dictionary clas ...
- Traefik访问master节点不通的问题定位
问题 部署traefik到客户节点的对外访问节点后,发现日志里面报错 类似于 E0122 :: reflector.go:] k8s.io/dns/vendor/k8s.io/client-go/to ...
- 创建maven web项目无法创建sec目录
创建maven web项目无法创建sec目录 解决方法:-DarchetypeCatalog=internal
- zigbee 学习笔记
在德州仪器的站点:http://www.ti.com.cn/tool/cn/z-stack上下载安装zigbee2007协议栈版,我的是ZStack-CC2530-2.3.0-1.4.0. 以下演示一 ...
- 解决SSH窗口关闭,linux上的应用也关闭
最近在应用linux上的服务的时候发现一个问题 使用SSH远程连接启动的应用在SSH关闭的时候也死掉了,网上查了一下原因 大致是说SSH在关闭的时候会发送一个终止的指令给应用,然后就停了 简要的解决办 ...